 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnforcing Conditional Independence for Fair Representation Learning and Causal Image Generation
Apr 21, 2024Conditional independence (CI) constraints are critical for defining and evaluating fairness in machine learning, as well as for learning unconfounded or causal representations. Traditional methods for ensuring fairness either blindly learn invariant features with respect to a protected variable (e.g., race when classifying sex from face images) or enforce CI relative to the protected attribute only on the model output (e.g., the sex label). Neither of these methods are effective in enforcing CI in high-dimensional feature spaces. In this paper, we focus on a nascent approach characterizing the CI constraint in terms of two Jensen-Shannon divergence terms, and we extend it to high-dimensional feature spaces using a novel dynamic sampling strategy. In doing so, we introduce a new training paradigm that can be applied to any encoder architecture. We are able to enforce conditional independence of the diffusion autoencoder latent representation with respect to any protected attribute under the equalized odds constraint and show that this approach enables causal image generation with controllable latent spaces. Our experimental results demonstrate that our approach can achieve high accuracy on downstream tasks while upholding equality of odds.
Combining Counterfactuals With Shapley Values To Explain Image Models
Jun 14, 2022
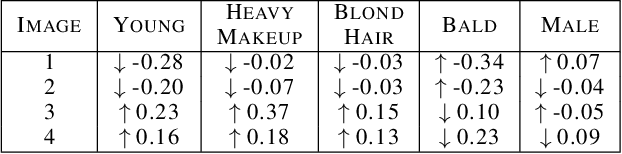
With the widespread use of sophisticated machine learning models in sensitive applications, understanding their decision-making has become an essential task. Models trained on tabular data have witnessed significant progress in explanations of their underlying decision making processes by virtue of having a small number of discrete features. However, applying these methods to high-dimensional inputs such as images is not a trivial task. Images are composed of pixels at an atomic level and do not carry any interpretability by themselves. In this work, we seek to use annotated high-level interpretable features of images to provide explanations. We leverage the Shapley value framework from Game Theory, which has garnered wide acceptance in general XAI problems. By developing a pipeline to generate counterfactuals and subsequently using it to estimate Shapley values, we obtain contrastive and interpretable explanations with strong axiomatic guarantees.
Explaining Image Classifiers Using Contrastive Counterfactuals in Generative Latent Spaces
Jun 10, 2022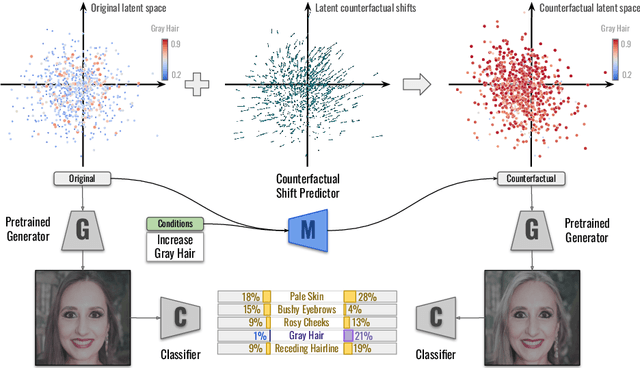


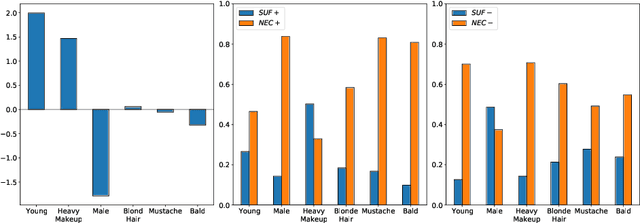
Despite their high accuracies, modern complex image classifiers cannot be trusted for sensitive tasks due to their unknown decision-making process and potential biases. Counterfactual explanations are very effective in providing transparency for these black-box algorithms. Nevertheless, generating counterfactuals that can have a consistent impact on classifier outputs and yet expose interpretable feature changes is a very challenging task. We introduce a novel method to generate causal and yet interpretable counterfactual explanations for image classifiers using pretrained generative models without any re-training or conditioning. The generative models in this technique are not bound to be trained on the same data as the target classifier. We use this framework to obtain contrastive and causal sufficiency and necessity scores as global explanations for black-box classifiers. On the task of face attribute classification, we show how different attributes influence the classifier output by providing both causal and contrastive feature attributions, and the corresponding counterfactual images.
Predicting Airbnb Rental Prices Using Multiple Feature Modalities
Dec 13, 2021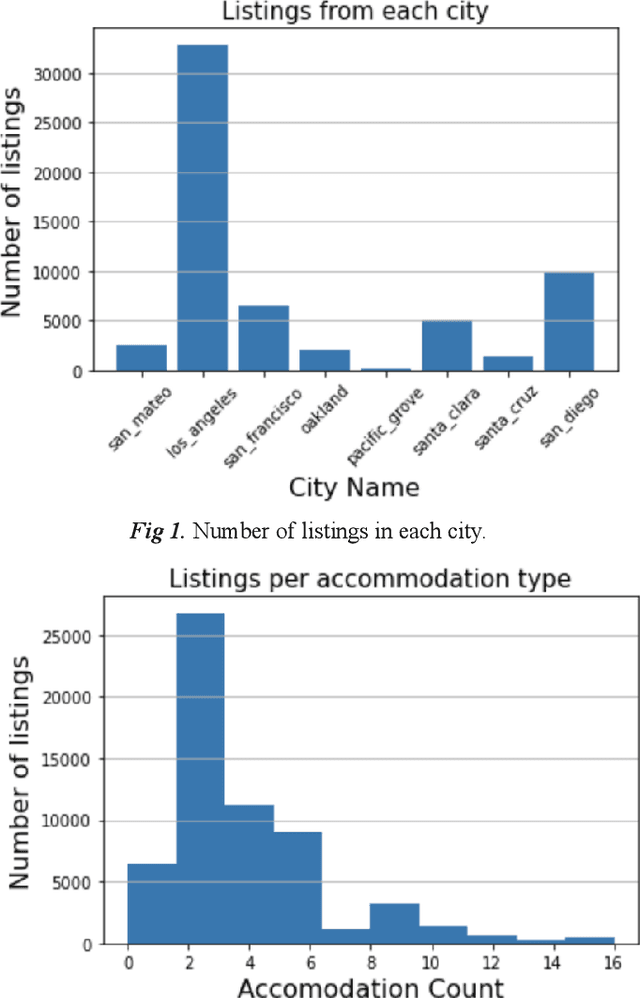
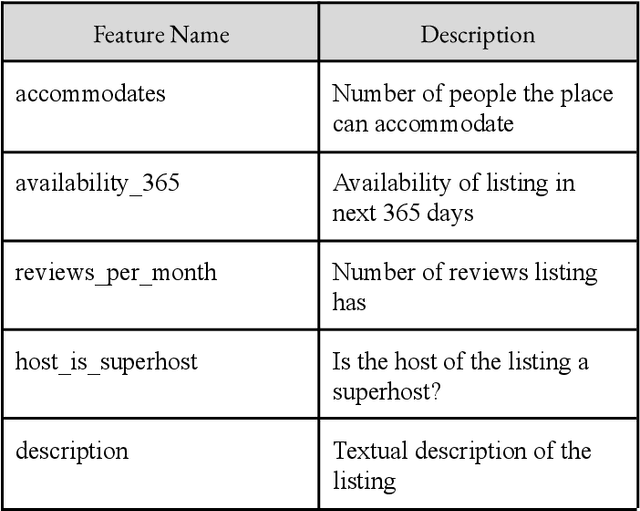
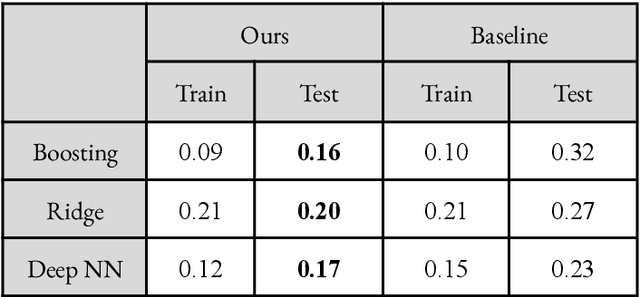
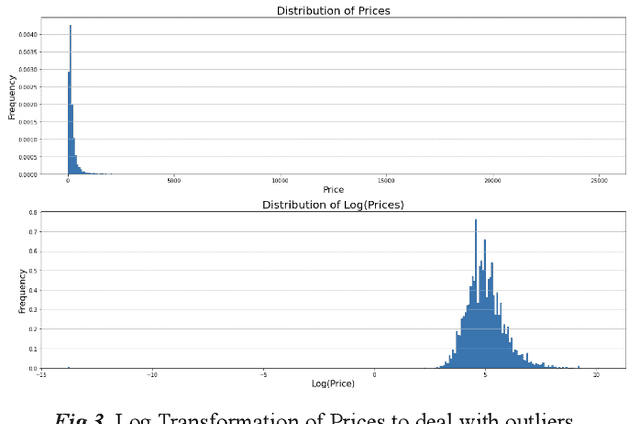
Figuring out the price of a listed Airbnb rental is an important and difficult task for both the host and the customer. For the former, it can enable them to set a reasonable price without compromising on their profits. For the customer, it helps understand the key drivers for price and also provides them with similarly priced places. This price prediction regression task can also have multiple downstream uses, such as in recommendation of similar rentals based on price. We propose to use geolocation, temporal, visual and natural language features to create a reliable and accurate price prediction algorithm.
Pitfalls of Explainable ML: An Industry Perspective
Jun 14, 2021As machine learning (ML) systems take a more prominent and central role in contributing to life-impacting decisions, ensuring their trustworthiness and accountability is of utmost importance. Explanations sit at the core of these desirable attributes of a ML system. The emerging field is frequently called ``Explainable AI (XAI)'' or ``Explainable ML.'' The goal of explainable ML is to intuitively explain the predictions of a ML system, while adhering to the needs to various stakeholders. Many explanation techniques were developed with contributions from both academia and industry. However, there are several existing challenges that have not garnered enough interest and serve as roadblocks to widespread adoption of explainable ML. In this short paper, we enumerate challenges in explainable ML from an industry perspective. We hope these challenges will serve as promising future research directions, and would contribute to democratizing explainable ML.
Accurate and Intuitive Contextual Explanations using Linear Model Trees
Sep 11, 2020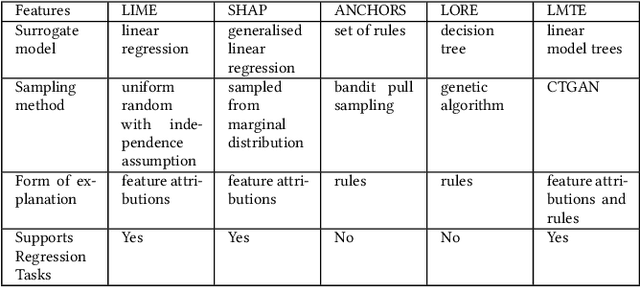
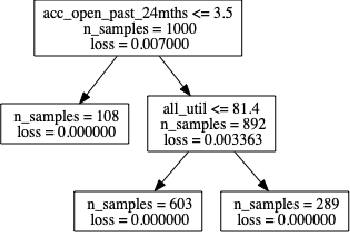
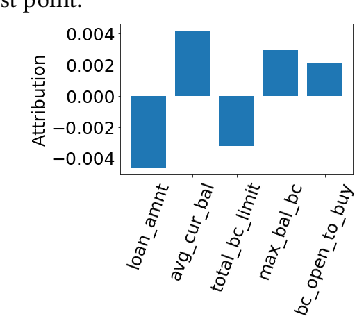

With the ever-increasing use of complex machine learning models in critical applications within the finance domain, explaining the decisions of the model has become a necessity. With applications spanning from credit scoring to credit marketing, the impact of these models is undeniable. Among the multiple ways in which one can explain the decisions of these complicated models, local post hoc model agnostic explanations have gained massive adoption. These methods allow one to explain each prediction independent of the modelling technique that was used while training. As explanations, they either give individual feature attributions or provide sufficient rules that represent conditions for a prediction to be made. The current state of the art methods use rudimentary methods to generate synthetic data around the point to be explained. This is followed by fitting simple linear models as surrogates to obtain a local interpretation of the prediction. In this paper, we seek to significantly improve on both, the method used to generate the explanations and the nature of explanations produced. We use a Generative Adversarial Network for synthetic data generation and train a piecewise linear model in the form of Linear Model Trees to be used as the surrogate model.In addition to individual feature attributions, we also provide an accompanying context to our explanations by leveraging the structure and property of our surrogate model.