 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Geometric View for Understanding Concept Learning and Neuron Interpretation in Sparse Autoencoders
Jun 05, 2026We propose a unified mathematical framework for a geometric understanding of concept learning and neuron interpretation in sparse autoencoders (SAEs). While SAEs improve interpretability of neural networks by learning sparse feature representations, a principled definition of ''concept'' and ''learning'' remains unclear. We formalize concepts as sets of data points and cast concept learning as a set-alignment problem between human-defined and model-induced concepts. This formulation distinguishes three increasingly strong notions of learning -- detection, separation, and approximation -- and yields geometric conditions, error bounds, and capacity constraints for when concepts can be represented by individual neurons or multi-neuron units. It also provides a set-theoretic account for common SAE phenomena, including feature splitting, feature absorption, feature families, and hierarchical concepts. Finally, we connect concept learning and neuron interpretation through formal concept analysis, showing that the two directions need not agree and that their many-to-many structure can be organized by concept lattices. Experiments on synthetic data with ReLU and Top-$K$ SAEs illustrate the theory and reveal the effects of SAE size and sparsity on concept learning.
Agents that Matter: Optimizing Multi-Agent LLMs via Removal-Based Attribution
May 26, 2026As multi-agent systems (MAS) become increasingly complex, identifying the contributions of individual agents is critical for system optimization. However, existing approaches lack a rigorous, unified framework for credit assignment. In this work, we formalize agent attribution as a cooperative game, parameterized by the coalition distribution, removal protocol, and target metric. Using this framework, we show that Leave-One-Out (LOO) identifies bottleneck agents as effectively as combinatorial methods, but at a fraction of the computational cost. We also demonstrate that removal protocols induce distinct games: Agent ablation isolates structural bottlenecks, whereas introspective LLM judges fail to faithfully approximate this behavior. Furthermore, to evaluate the utility of specific agent backbones, we introduce attribution via model replacement. By substituting underlying models of low-contribution agents, we improve task performance by up to 17% while reducing cost by up to 35% across three benchmarks. Finally, we apply our framework to audit a medical MAS, revealing that agent contributions to diagnostic accuracy and ethical behavior are often decoupled. By intervening on counterproductive roles, we observe an increase in ethics alignment while maintaining diagnostic accuracy. Overall, this work provides a principled approach for cost-effective MAS attribution and intervention.
Where to Steer: Input-Dependent Layer Selection for Steering Improves LLM Alignment
Apr 04, 2026Steering vectors have emerged as a lightweight and effective approach for aligning large language models (LLMs) at inference time, enabling modulation over model behaviors by shifting LLM representations towards a target behavior. However, existing methods typically apply steering vectors at a globally fixed layer, implicitly assuming that the optimal intervention layer is invariant across inputs. We argue that this assumption is fundamentally limited, as representations relevant to a target behavior can be encoded at different layers depending on the input. Theoretically, we show that different inputs can require steering at different layers to achieve alignment with a desirable model behavior. We also provide empirical evidence that the optimal steering layer varies substantially across inputs in practice. Motivated by these observations, we introduce Where to Steer (W2S), a framework that adaptively selects the intervention layer conditioned on the input, by learning a mapping from input embeddings to optimal steering layers. Across multiple LLMs and alignment behaviors, W2S consistently outperforms fixed-layer baselines, with improvements in both in-distribution and out-of-distribution settings. Our findings highlight the importance of input-dependent control in LLM alignment and demonstrate that adaptive layer selection is a key design dimension missing in the current methodology of steering vectors.
SurrogateSHAP: Training-Free Contributor Attribution for Text-to-Image (T2I) Models
Jan 29, 2026As Text-to-Image (T2I) diffusion models are increasingly used in real-world creative workflows, a principled framework for valuing contributors who provide a collection of data is essential for fair compensation and sustainable data marketplaces. While the Shapley value offers a theoretically grounded approach to attribution, it faces a dual computational bottleneck: (i) the prohibitive cost of exhaustive model retraining for each sampled subset of players (i.e., data contributors) and (ii) the combinatorial number of subsets needed to estimate marginal contributions due to contributor interactions. To this end, we propose SurrogateSHAP, a retraining-free framework that approximates the expensive retraining game through inference from a pretrained model. To further improve efficiency, we employ a gradient-boosted tree to approximate the utility function and derive Shapley values analytically from the tree-based model. We evaluate SurrogateSHAP across three diverse attribution tasks: (i) image quality for DDPM-CFG on CIFAR-20, (ii) aesthetics for Stable Diffusion on Post-Impressionist artworks, and (iii) product diversity for FLUX.1 on Fashion-Product data. Across settings, SurrogateSHAP outperforms prior methods while substantially reducing computational overhead, consistently identifying influential contributors across multiple utility metrics. Finally, we demonstrate that SurrogateSHAP effectively localizes data sources responsible for spurious correlations in clinical images, providing a scalable path toward auditing safety-critical generative models.
Ensembling Sparse Autoencoders
May 21, 2025Sparse autoencoders (SAEs) are used to decompose neural network activations into human-interpretable features. Typically, features learned by a single SAE are used for downstream applications. However, it has recently been shown that SAEs trained with different initial weights can learn different features, demonstrating that a single SAE captures only a limited subset of features that can be extracted from the activation space. Motivated by this limitation, we propose to ensemble multiple SAEs through naive bagging and boosting. Specifically, SAEs trained with different weight initializations are ensembled in naive bagging, whereas SAEs sequentially trained to minimize the residual error are ensembled in boosting. We evaluate our ensemble approaches with three settings of language models and SAE architectures. Our empirical results demonstrate that ensembling SAEs can improve the reconstruction of language model activations, diversity of features, and SAE stability. Furthermore, ensembling SAEs performs better than applying a single SAE on downstream tasks such as concept detection and spurious correlation removal, showing improved practical utility.
Stochastic Amortization: A Unified Approach to Accelerate Feature and Data Attribution
Jan 29, 2024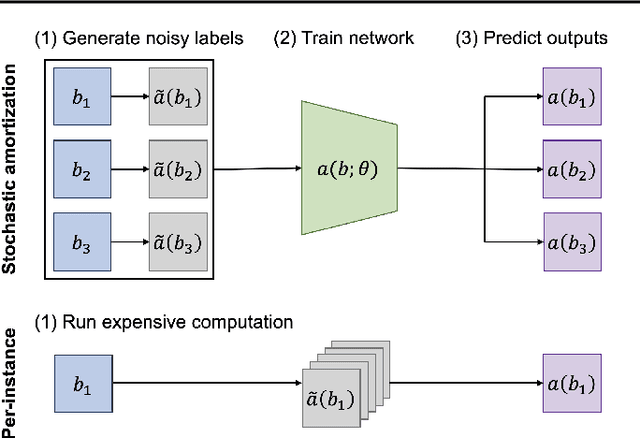

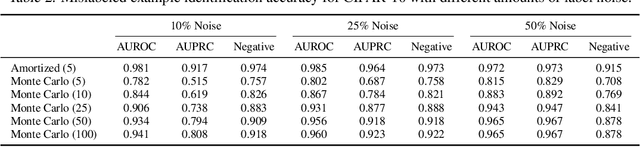
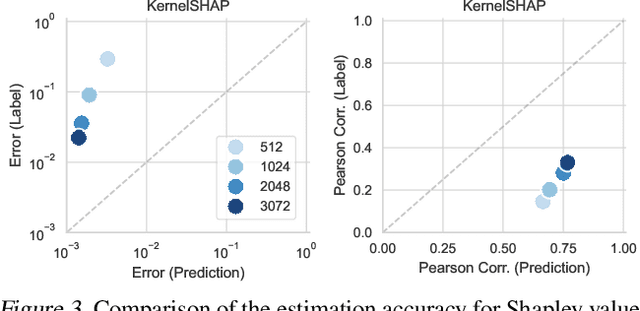
Many tasks in explainable machine learning, such as data valuation and feature attribution, perform expensive computation for each data point and can be intractable for large datasets. These methods require efficient approximations, and learning a network that directly predicts the desired output, which is commonly known as amortization, is a promising solution. However, training such models with exact labels is often intractable; we therefore explore training with noisy labels and find that this is inexpensive and surprisingly effective. Through theoretical analysis of the label noise and experiments with various models and datasets, we show that this approach significantly accelerates several feature attribution and data valuation methods, often yielding an order of magnitude speedup over existing approaches.
Feature Selection in the Contrastive Analysis Setting
Oct 27, 2023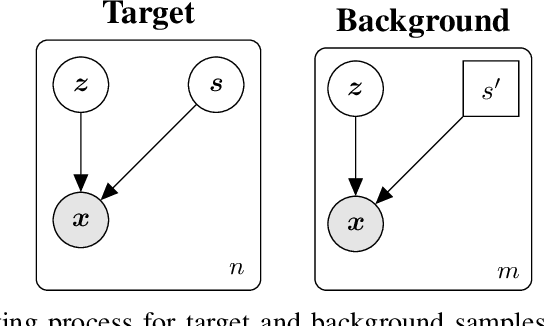
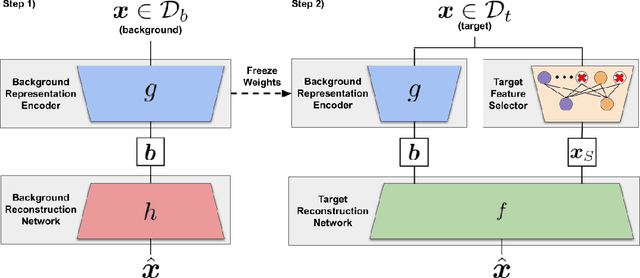
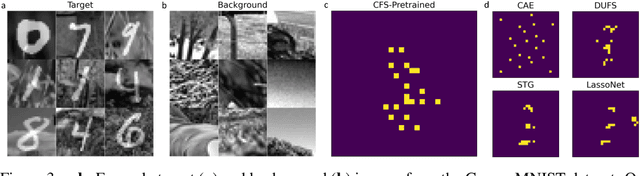

Contrastive analysis (CA) refers to the exploration of variations uniquely enriched in a target dataset as compared to a corresponding background dataset generated from sources of variation that are irrelevant to a given task. For example, a biomedical data analyst may wish to find a small set of genes to use as a proxy for variations in genomic data only present among patients with a given disease (target) as opposed to healthy control subjects (background). However, as of yet the problem of feature selection in the CA setting has received little attention from the machine learning community. In this work we present contrastive feature selection (CFS), a method for performing feature selection in the CA setting. We motivate our approach with a novel information-theoretic analysis of representation learning in the CA setting, and we empirically validate CFS on a semi-synthetic dataset and four real-world biomedical datasets. We find that our method consistently outperforms previously proposed state-of-the-art supervised and fully unsupervised feature selection methods not designed for the CA setting. An open-source implementation of our method is available at https://github.com/suinleelab/CFS.
On the Robustness of Removal-Based Feature Attributions
Jun 12, 2023



To explain complex models based on their inputs, many feature attribution methods have been developed that assign importance scores to input features. However, some recent work challenges the robustness of feature attributions by showing that these methods are sensitive to input and model perturbations, while other work addresses this robustness issue by proposing robust attribution methods and model modifications. Nevertheless, previous work on attribution robustness has focused primarily on gradient-based feature attributions. In contrast, the robustness properties of removal-based attribution methods are not comprehensively well understood. To bridge this gap, we theoretically characterize the robustness of removal-based feature attributions. Specifically, we provide a unified analysis of such methods and prove upper bounds for the difference between intact and perturbed attributions, under settings of both input and model perturbations. Our empirical experiments on synthetic and real-world data validate our theoretical results and demonstrate their practical implications.
Estimating Conditional Mutual Information for Dynamic Feature Selection
Jun 05, 2023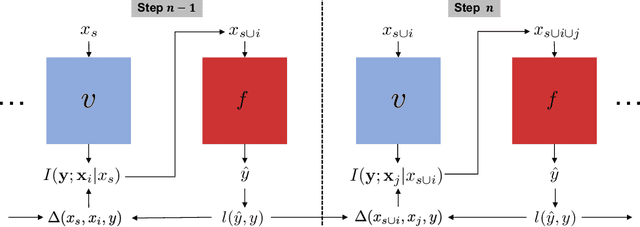
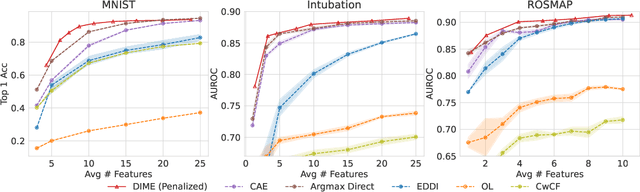
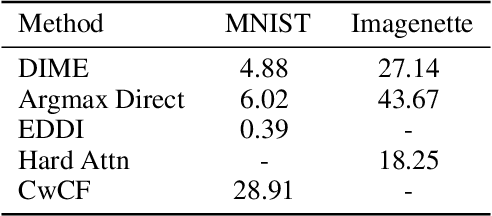
Dynamic feature selection, where we sequentially query features to make accurate predictions with a minimal budget, is a promising paradigm to reduce feature acquisition costs and provide transparency into the prediction process. The problem is challenging, however, as it requires both making predictions with arbitrary feature sets and learning a policy to identify the most valuable selections. Here, we take an information-theoretic perspective and prioritize features based on their mutual information with the response variable. The main challenge is learning this selection policy, and we design a straightforward new modeling approach that estimates the mutual information in a discriminative rather than generative fashion. Building on our learning approach, we introduce several further improvements: allowing variable feature budgets across samples, enabling non-uniform costs between features, incorporating prior information, and exploring modern architectures to handle partial input information. We find that our method provides consistent gains over recent state-of-the-art methods across a variety of datasets.
Learning to Maximize Mutual Information for Dynamic Feature Selection
Jan 02, 2023



Feature selection helps reduce data acquisition costs in ML, but the standard approach is to train models with static feature subsets. Here, we consider the dynamic feature selection (DFS) problem where a model sequentially queries features based on the presently available information. DFS is often addressed with reinforcement learning (RL), but we explore a simpler approach of greedily selecting features based on their conditional mutual information. This method is theoretically appealing but requires oracle access to the data distribution, so we develop a learning approach based on amortized optimization. The proposed method is shown to recover the greedy policy when trained to optimality and outperforms numerous existing feature selection methods in our experiments, thus validating it as a simple but powerful approach for this problem.