 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Amortization: A Unified Approach to Accelerate Feature and Data Attribution
Paper and Code
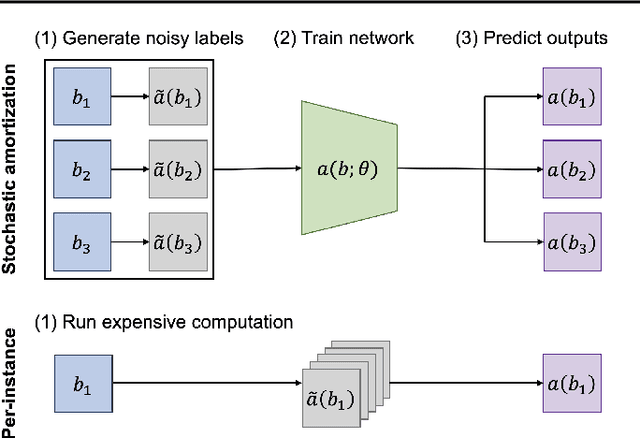

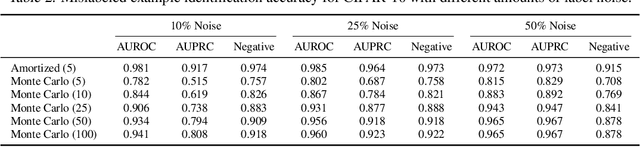
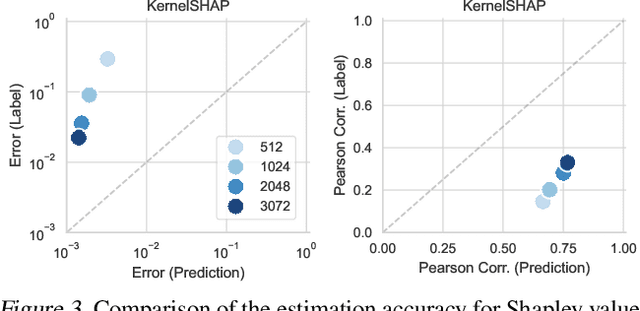
Many tasks in explainable machine learning, such as data valuation and feature attribution, perform expensive computation for each data point and can be intractable for large datasets. These methods require efficient approximations, and learning a network that directly predicts the desired output, which is commonly known as amortization, is a promising solution. However, training such models with exact labels is often intractable; we therefore explore training with noisy labels and find that this is inexpensive and surprisingly effective. Through theoretical analysis of the label noise and experiments with various models and datasets, we show that this approach significantly accelerates several feature attribution and data valuation methods, often yielding an order of magnitude speedup over existing approaches.