 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Locality Alignment Improves Vision-Language Models
Oct 14, 2024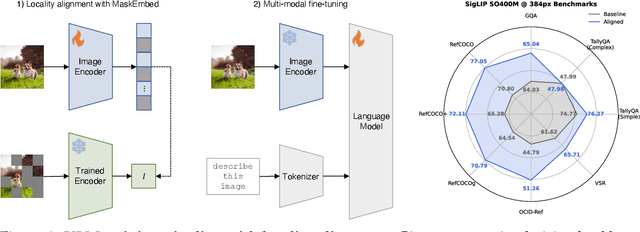
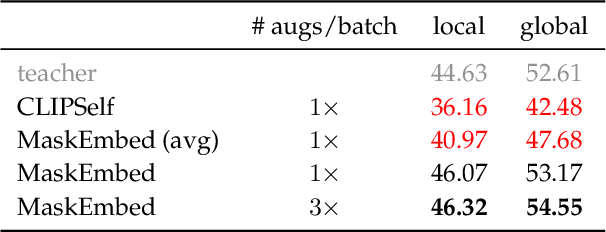
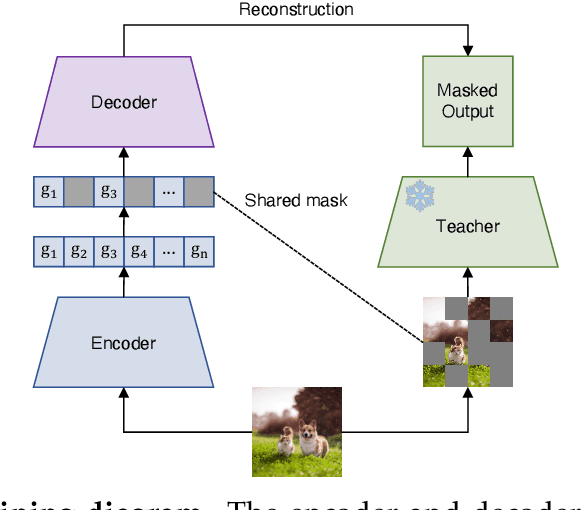
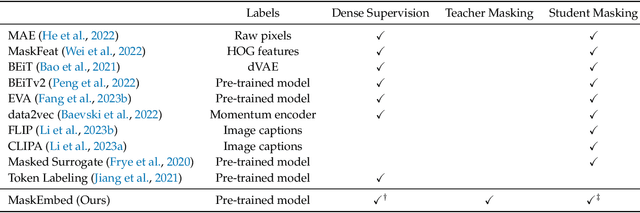
Vision language models (VLMs) have seen growing adoption in recent years, but many still struggle with basic spatial reasoning errors. We hypothesize that this is due to VLMs adopting pre-trained vision backbones, specifically vision transformers (ViTs) trained with image-level supervision and minimal inductive biases. Such models may fail to encode the class contents at each position in the image, and our goal is to resolve this by ensuring that the vision backbone effectively captures both local and global image semantics. Our main insight is that we do not require new supervision to learn this capability -- pre-trained models contain significant knowledge of local semantics that we can extract and use for scalable self-supervision. We propose a new efficient post-training stage for ViTs called locality alignment and a novel fine-tuning procedure called MaskEmbed that uses a masked reconstruction loss to learn semantic contributions for each image patch. We first evaluate locality alignment with a vision-only benchmark, finding that it improves a model's performance at a patch-level semantic segmentation task, especially for strong backbones trained with image-caption pairs (e.g., CLIP and SigLIP). We then train a series of VLMs with and without locality alignment, and show that locality-aligned backbones improve performance across a range of benchmarks, particularly ones that involve spatial understanding (e.g., RefCOCO, OCID-Ref, TallyQA, VSR, AI2D). Overall, we demonstrate that we can efficiently learn local semantic extraction via a locality alignment stage, and that this procedure complements existing VLM training recipes that use off-the-shelf vision backbones.
Scaling Laws for the Value of Individual Data Points in Machine Learning
May 30, 2024



Recent works have shown that machine learning models improve at a predictable rate with the total amount of training data, leading to scaling laws that describe the relationship between error and dataset size. These scaling laws can help design a model's training dataset, but they typically take an aggregate view of the data by only considering the dataset's size. We introduce a new perspective by investigating scaling behavior for the value of individual data points: we find that a data point's contribution to model's performance shrinks predictably with the size of the dataset in a log-linear manner. Interestingly, there is significant variability in the scaling exponent among different data points, indicating that certain points are more valuable in small datasets while others are relatively more useful as a part of large datasets. We provide learning theory to support our scaling law, and we observe empirically that it holds across diverse model classes. We further propose a maximum likelihood estimator and an amortized estimator to efficiently learn the individualized scaling behaviors from a small number of noisy observations per data point. Using our estimators, we provide insights into factors that influence the scaling behavior of different data points. Finally, we demonstrate applications of the individualized scaling laws to data valuation and data subset selection. Overall, our work represents a first step towards understanding and utilizing scaling properties for the value of individual data points.
Stochastic Amortization: A Unified Approach to Accelerate Feature and Data Attribution
Jan 29, 2024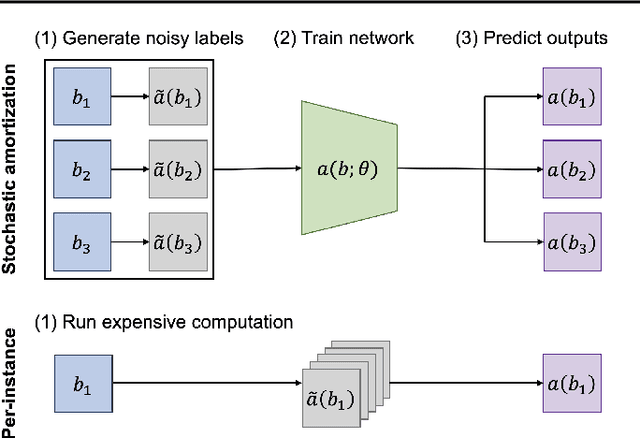

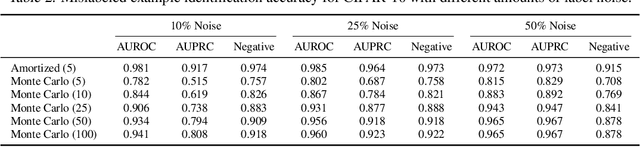
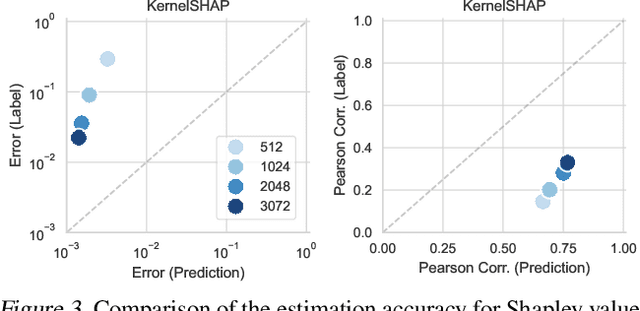
Many tasks in explainable machine learning, such as data valuation and feature attribution, perform expensive computation for each data point and can be intractable for large datasets. These methods require efficient approximations, and learning a network that directly predicts the desired output, which is commonly known as amortization, is a promising solution. However, training such models with exact labels is often intractable; we therefore explore training with noisy labels and find that this is inexpensive and surprisingly effective. Through theoretical analysis of the label noise and experiments with various models and datasets, we show that this approach significantly accelerates several feature attribution and data valuation methods, often yielding an order of magnitude speedup over existing approaches.
Feature Selection in the Contrastive Analysis Setting
Oct 27, 2023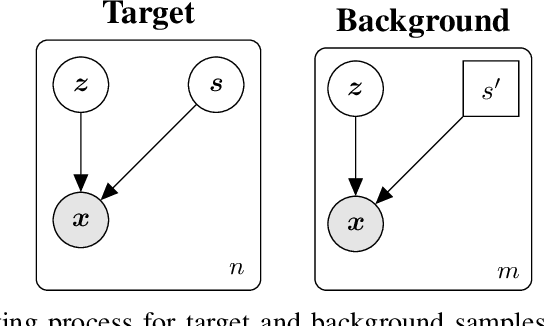
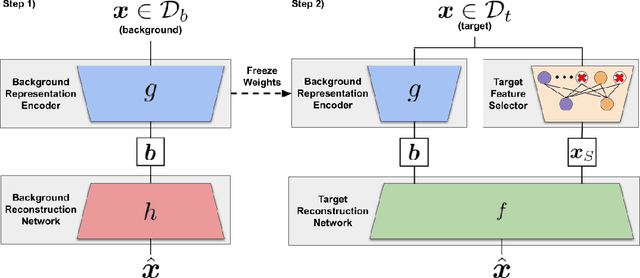
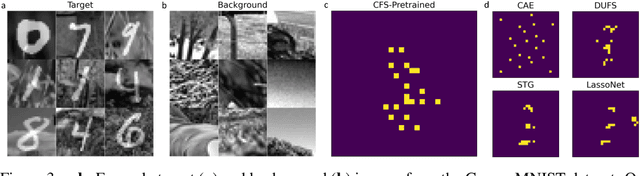

Contrastive analysis (CA) refers to the exploration of variations uniquely enriched in a target dataset as compared to a corresponding background dataset generated from sources of variation that are irrelevant to a given task. For example, a biomedical data analyst may wish to find a small set of genes to use as a proxy for variations in genomic data only present among patients with a given disease (target) as opposed to healthy control subjects (background). However, as of yet the problem of feature selection in the CA setting has received little attention from the machine learning community. In this work we present contrastive feature selection (CFS), a method for performing feature selection in the CA setting. We motivate our approach with a novel information-theoretic analysis of representation learning in the CA setting, and we empirically validate CFS on a semi-synthetic dataset and four real-world biomedical datasets. We find that our method consistently outperforms previously proposed state-of-the-art supervised and fully unsupervised feature selection methods not designed for the CA setting. An open-source implementation of our method is available at https://github.com/suinleelab/CFS.
On the Robustness of Removal-Based Feature Attributions
Jun 12, 2023



To explain complex models based on their inputs, many feature attribution methods have been developed that assign importance scores to input features. However, some recent work challenges the robustness of feature attributions by showing that these methods are sensitive to input and model perturbations, while other work addresses this robustness issue by proposing robust attribution methods and model modifications. Nevertheless, previous work on attribution robustness has focused primarily on gradient-based feature attributions. In contrast, the robustness properties of removal-based attribution methods are not comprehensively well understood. To bridge this gap, we theoretically characterize the robustness of removal-based feature attributions. Specifically, we provide a unified analysis of such methods and prove upper bounds for the difference between intact and perturbed attributions, under settings of both input and model perturbations. Our empirical experiments on synthetic and real-world data validate our theoretical results and demonstrate their practical implications.
Estimating Conditional Mutual Information for Dynamic Feature Selection
Jun 05, 2023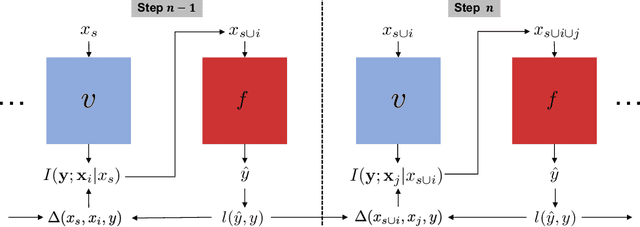
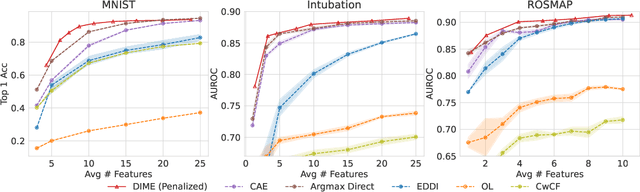
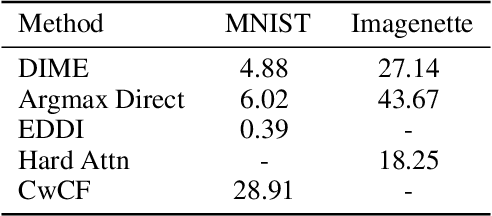
Dynamic feature selection, where we sequentially query features to make accurate predictions with a minimal budget, is a promising paradigm to reduce feature acquisition costs and provide transparency into the prediction process. The problem is challenging, however, as it requires both making predictions with arbitrary feature sets and learning a policy to identify the most valuable selections. Here, we take an information-theoretic perspective and prioritize features based on their mutual information with the response variable. The main challenge is learning this selection policy, and we design a straightforward new modeling approach that estimates the mutual information in a discriminative rather than generative fashion. Building on our learning approach, we introduce several further improvements: allowing variable feature budgets across samples, enabling non-uniform costs between features, incorporating prior information, and exploring modern architectures to handle partial input information. We find that our method provides consistent gains over recent state-of-the-art methods across a variety of datasets.
Learning to Maximize Mutual Information for Dynamic Feature Selection
Jan 02, 2023



Feature selection helps reduce data acquisition costs in ML, but the standard approach is to train models with static feature subsets. Here, we consider the dynamic feature selection (DFS) problem where a model sequentially queries features based on the presently available information. DFS is often addressed with reinforcement learning (RL), but we explore a simpler approach of greedily selecting features based on their conditional mutual information. This method is theoretically appealing but requires oracle access to the data distribution, so we develop a learning approach based on amortized optimization. The proposed method is shown to recover the greedy policy when trained to optimality and outperforms numerous existing feature selection methods in our experiments, thus validating it as a simple but powerful approach for this problem.
Learning to Estimate Shapley Values with Vision Transformers
Jun 10, 2022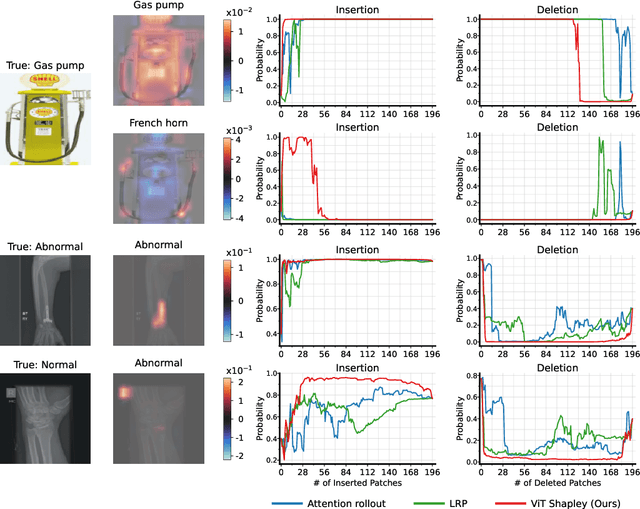
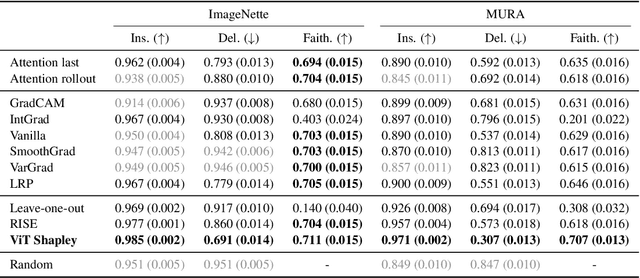
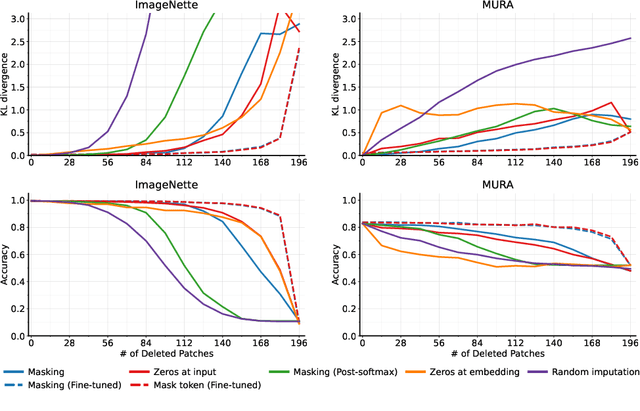
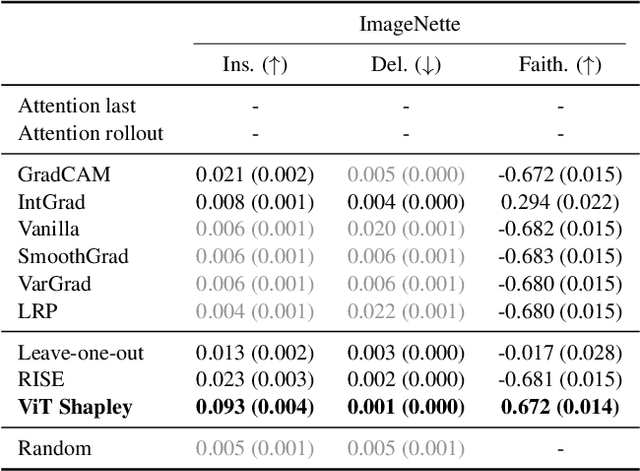
Transformers have become a default architecture in computer vision, but understanding what drives their predictions remains a challenging problem. Current explanation approaches rely on attention values or input gradients, but these give a limited understanding of a model's dependencies. Shapley values offer a theoretically sound alternative, but their computational cost makes them impractical for large, high-dimensional models. In this work, we aim to make Shapley values practical for vision transformers (ViTs). To do so, we first leverage an attention masking approach to evaluate ViTs with partial information, and we then develop a procedure for generating Shapley value explanations via a separate, learned explainer model. Our experiments compare Shapley values to many baseline methods (e.g., attention rollout, GradCAM, LRP), and we find that our approach provides more accurate explanations than any existing method for ViTs.
FastSHAP: Real-Time Shapley Value Estimation
Jul 15, 2021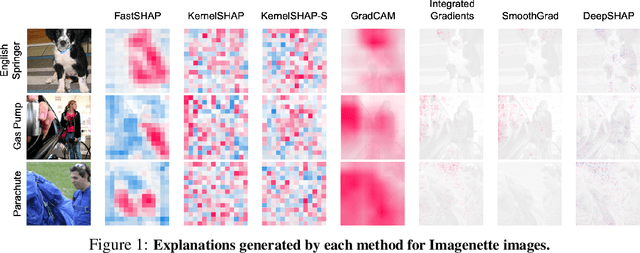
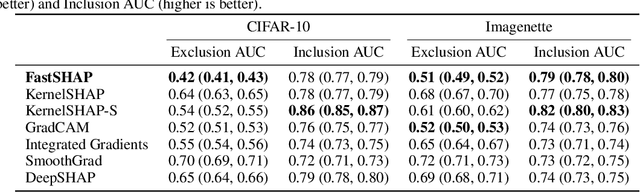
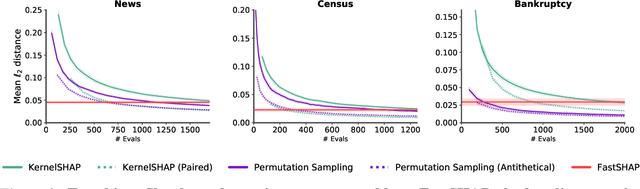
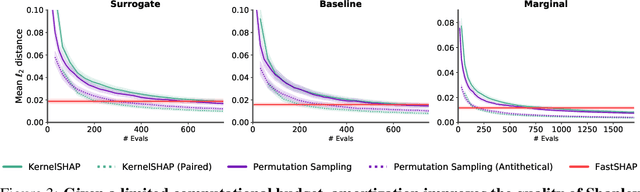
Shapley values are widely used to explain black-box models, but they are costly to calculate because they require many model evaluations. We introduce FastSHAP, a method for estimating Shapley values in a single forward pass using a learned explainer model. FastSHAP amortizes the cost of explaining many inputs via a learning approach inspired by the Shapley value's weighted least squares characterization, and it can be trained using standard stochastic gradient optimization. We compare FastSHAP to existing estimation approaches, revealing that it generates high-quality explanations with orders of magnitude speedup.