 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA dynamic risk score for early prediction of cardiogenic shock using machine learning
Mar 28, 2023



Myocardial infarction and heart failure are major cardiovascular diseases that affect millions of people in the US. The morbidity and mortality are highest among patients who develop cardiogenic shock. Early recognition of cardiogenic shock is critical. Prompt implementation of treatment measures can prevent the deleterious spiral of ischemia, low blood pressure, and reduced cardiac output due to cardiogenic shock. However, early identification of cardiogenic shock has been challenging due to human providers' inability to process the enormous amount of data in the cardiac intensive care unit (ICU) and lack of an effective risk stratification tool. We developed a deep learning-based risk stratification tool, called CShock, for patients admitted into the cardiac ICU with acute decompensated heart failure and/or myocardial infarction to predict onset of cardiogenic shock. To develop and validate CShock, we annotated cardiac ICU datasets with physician adjudicated outcomes. CShock achieved an area under the receiver operator characteristic curve (AUROC) of 0.820, which substantially outperformed CardShock (AUROC 0.519), a well-established risk score for cardiogenic shock prognosis. CShock was externally validated in an independent patient cohort and achieved an AUROC of 0.800, demonstrating its generalizability in other cardiac ICUs.
Don't be fooled: label leakage in explanation methods and the importance of their quantitative evaluation
Feb 24, 2023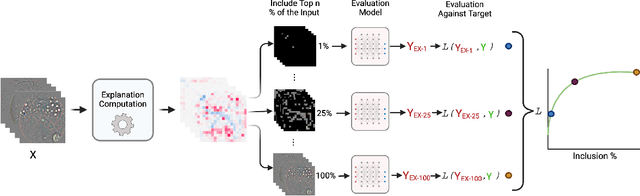
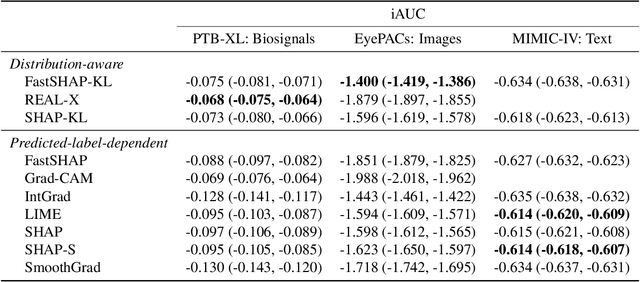
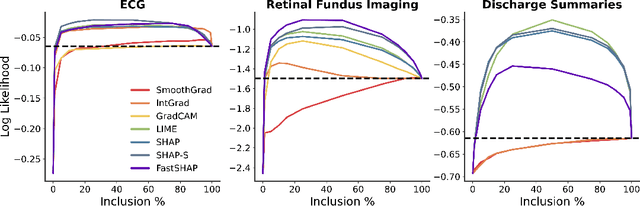
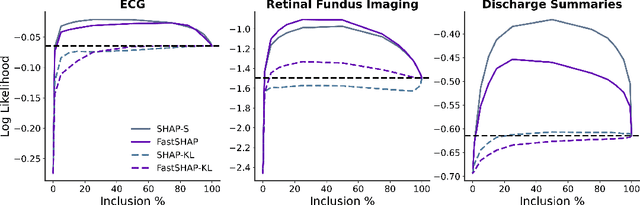
Feature attribution methods identify which features of an input most influence a model's output. Most widely-used feature attribution methods (such as SHAP, LIME, and Grad-CAM) are "class-dependent" methods in that they generate a feature attribution vector as a function of class. In this work, we demonstrate that class-dependent methods can "leak" information about the selected class, making that class appear more likely than it is. Thus, an end user runs the risk of drawing false conclusions when interpreting an explanation generated by a class-dependent method. In contrast, we introduce "distribution-aware" methods, which favor explanations that keep the label's distribution close to its distribution given all features of the input. We introduce SHAP-KL and FastSHAP-KL, two baseline distribution-aware methods that compute Shapley values. Finally, we perform a comprehensive evaluation of seven class-dependent and three distribution-aware methods on three clinical datasets of different high-dimensional data types: images, biosignals, and text.
New-Onset Diabetes Assessment Using Artificial Intelligence-Enhanced Electrocardiography
May 05, 2022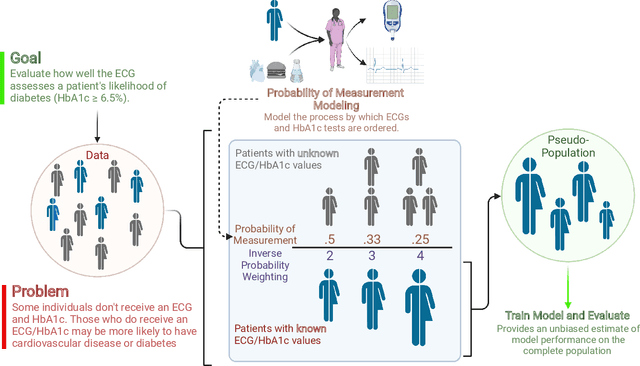
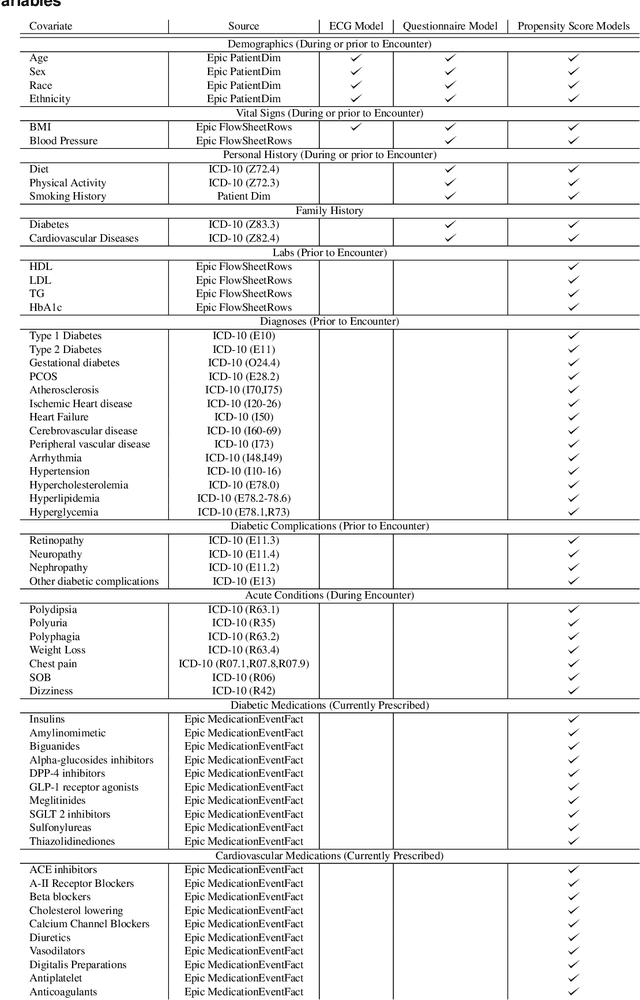
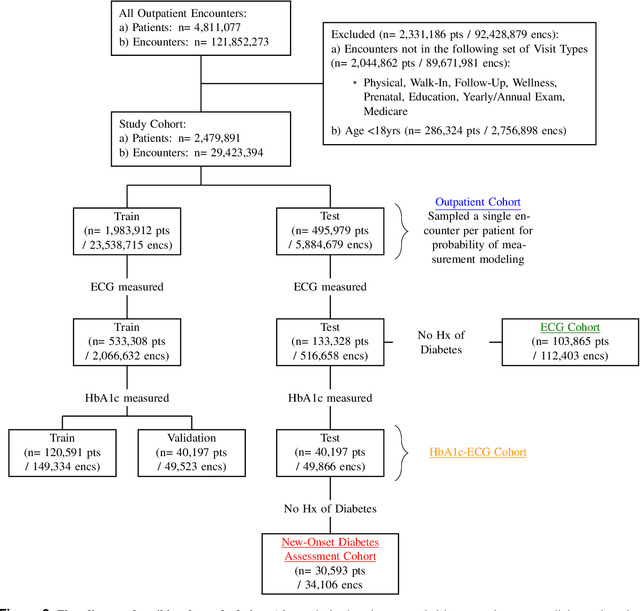
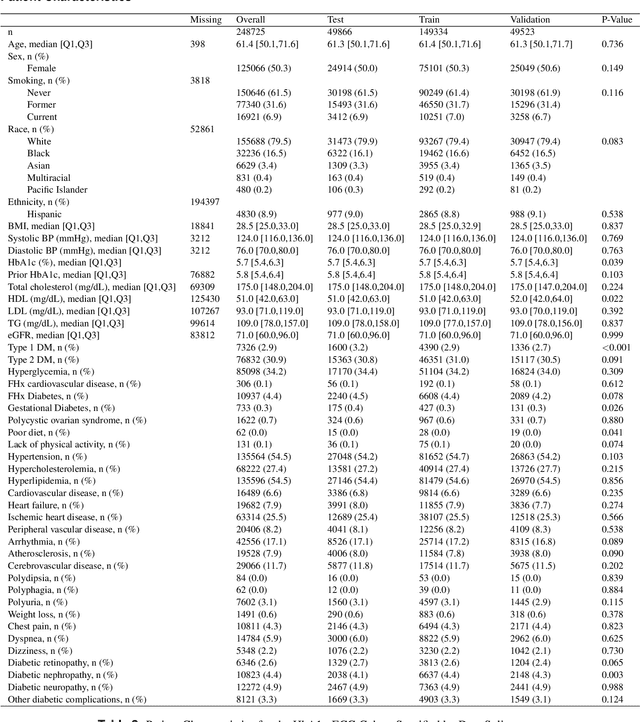
Undiagnosed diabetes is present in 21.4% of adults with diabetes. Diabetes can remain asymptomatic and undetected due to limitations in screening rates. To address this issue, questionnaires, such as the American Diabetes Association (ADA) Risk test, have been recommended for use by physicians and the public. Based on evidence that blood glucose concentration can affect cardiac electrophysiology, we hypothesized that an artificial intelligence (AI)-enhanced electrocardiogram (ECG) could identify adults with new-onset diabetes. We trained a neural network to estimate HbA1c using a 12-lead ECG and readily available demographics. We retrospectively assembled a dataset comprised of patients with paired ECG and HbA1c data. The population of patients who receive both an ECG and HbA1c may a biased sample of the complete outpatient population, so we adjusted the importance placed on each patient to generate a more representative pseudo-population. We found ECG-based assessment outperforms the ADA Risk test, achieving a higher area under the curve (0.80 vs. 0.68) and positive predictive value (14% vs. 9%) -- 2.6 times the prevalence of diabetes in the cohort. The AI-enhanced ECG significantly outperforms electrophysiologist interpretation of the ECG, suggesting that the task is beyond current clinical capabilities. Given the prevalence of ECGs in clinics and via wearable devices, such a tool would make precise, automated diabetes assessment widely accessible.
FastSHAP: Real-Time Shapley Value Estimation
Jul 15, 2021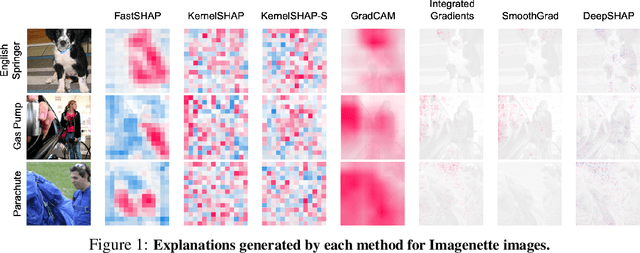
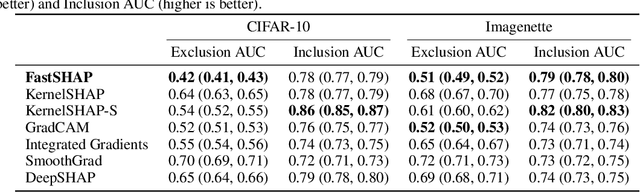
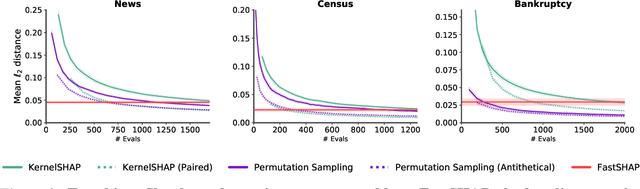
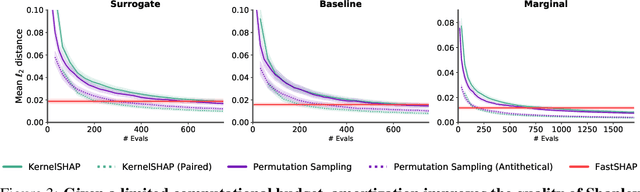
Shapley values are widely used to explain black-box models, but they are costly to calculate because they require many model evaluations. We introduce FastSHAP, a method for estimating Shapley values in a single forward pass using a learned explainer model. FastSHAP amortizes the cost of explaining many inputs via a learning approach inspired by the Shapley value's weighted least squares characterization, and it can be trained using standard stochastic gradient optimization. We compare FastSHAP to existing estimation approaches, revealing that it generates high-quality explanations with orders of magnitude speedup.
Have We Learned to Explain?: How Interpretability Methods Can Learn to Encode Predictions in their Interpretations
Mar 02, 2021
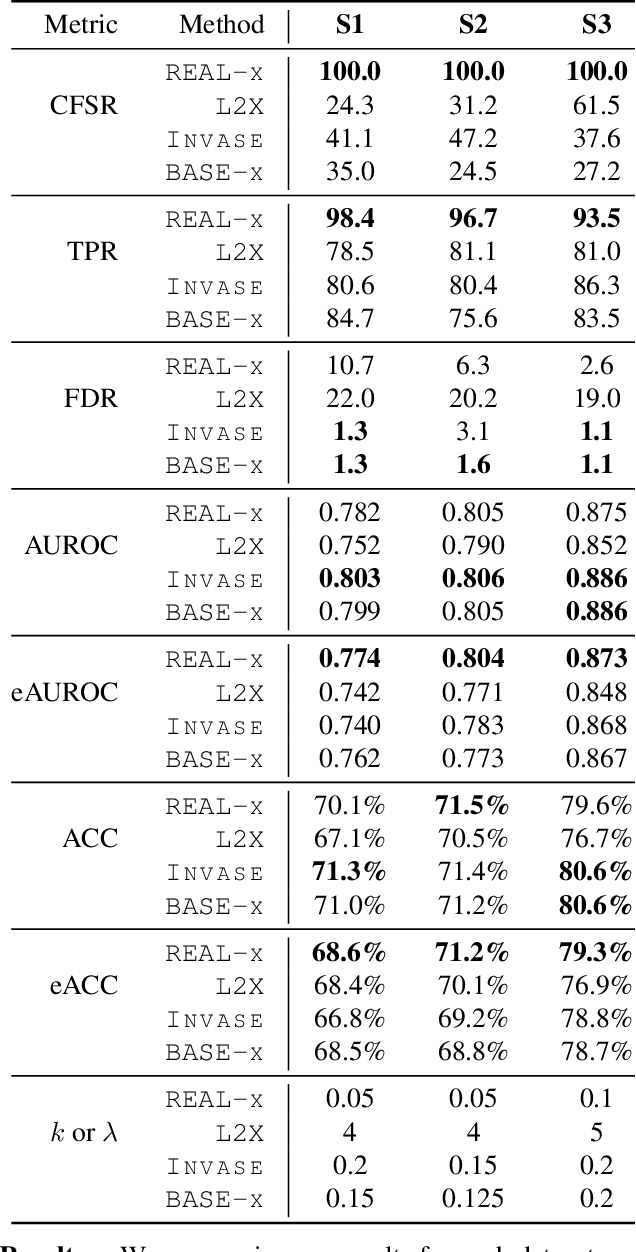
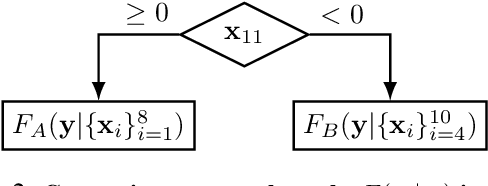
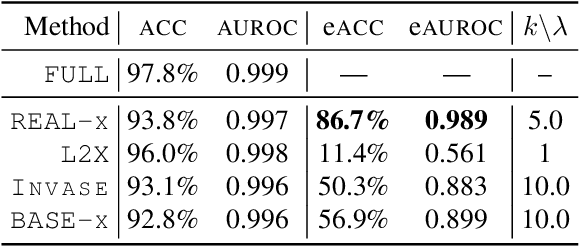
While the need for interpretable machine learning has been established, many common approaches are slow, lack fidelity, or hard to evaluate. Amortized explanation methods reduce the cost of providing interpretations by learning a global selector model that returns feature importances for a single instance of data. The selector model is trained to optimize the fidelity of the interpretations, as evaluated by a predictor model for the target. Popular methods learn the selector and predictor model in concert, which we show allows predictions to be encoded within interpretations. We introduce EVAL-X as a method to quantitatively evaluate interpretations and REAL-X as an amortized explanation method, which learn a predictor model that approximates the true data generating distribution given any subset of the input. We show EVAL-X can detect when predictions are encoded in interpretations and show the advantages of REAL-X through quantitative and radiologist evaluation.
* 15 pages, 3 figures, Proceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS) 2021