 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet the Experts Speak: Improving Survival Prediction & Calibration via Mixture-of-Experts Heads
Nov 11, 2025Deep mixture-of-experts models have attracted a lot of attention for survival analysis problems, particularly for their ability to cluster similar patients together. In practice, grouping often comes at the expense of key metrics such calibration error and predictive accuracy. This is due to the restrictive inductive bias that mixture-of-experts imposes, that predictions for individual patients must look like predictions for the group they're assigned to. Might we be able to discover patient group structure, where it exists, while improving calibration and predictive accuracy? In this work, we introduce several discrete-time deep mixture-of-experts (MoE) based architectures for survival analysis problems, one of which achieves all desiderata: clustering, calibration, and predictive accuracy. We show that a key differentiator between this array of MoEs is how expressive their experts are. We find that more expressive experts that tailor predictions per patient outperform experts that rely on fixed group prototypes.
Attention and Compression is all you need for Controllably Efficient Language Models
Nov 07, 2025The quadratic cost of attention in transformers motivated the development of efficient approaches: namely sparse and sliding window attention, convolutions and linear attention. Although these approaches result in impressive reductions in compute and memory, they often trade-off with quality, specifically in-context recall performance. Moreover, apriori fixing this quality-compute tradeoff means being suboptimal from the get-go: some downstream applications require more memory for in-context recall, while others require lower latency and memory. Further, these approaches rely on heuristic choices that artificially restrict attention, or require handcrafted and complex recurrent state update rules, or they must be carefully composed with attention at specific layers to form a hybrid architecture that complicates the design process, especially at scale. To address above issues, we propose Compress & Attend Transformer (CAT), a conceptually simple architecture employing two simple ingredients only: dense attention and compression. CAT decodes chunks of tokens by attending to compressed chunks of the sequence so far. Compression results in decoding from a reduced sequence length that yields compute and memory savings, while choosing a particular chunk size trades-off quality for efficiency. Moreover, CAT can be trained with multiple chunk sizes at once, unlocking control of quality-compute trade-offs directly at test-time without any retraining, all in a single adaptive architecture. In exhaustive evaluations on common language modeling tasks, in-context recall, and long-context understanding, a single adaptive CAT model outperforms existing efficient baselines, including hybrid architectures, across different compute-memory budgets. Further, a single CAT matches dense transformer in language modeling across model scales while being 1.4-3x faster and requiring 2-9x lower total memory usage.
Explanations that reveal all through the definition of encoding
Nov 04, 2024



Feature attributions attempt to highlight what inputs drive predictive power. Good attributions or explanations are thus those that produce inputs that retain this predictive power; accordingly, evaluations of explanations score their quality of prediction. However, evaluations produce scores better than what appears possible from the values in the explanation for a class of explanations, called encoding explanations. Probing for encoding remains a challenge because there is no general characterization of what gives the extra predictive power. We develop a definition of encoding that identifies this extra predictive power via conditional dependence and show that the definition fits existing examples of encoding. This definition implies, in contrast to encoding explanations, that non-encoding explanations contain all the informative inputs used to produce the explanation, giving them a "what you see is what you get" property, which makes them transparent and simple to use. Next, we prove that existing scores (ROAR, FRESH, EVAL-X) do not rank non-encoding explanations above encoding ones, and develop STRIPE-X which ranks them correctly. After empirically demonstrating the theoretical insights, we use STRIPE-X to uncover encoding in LLM-generated explanations for predicting the sentiment in movie reviews.
* 35 pages, 7 figures, 6 tables, 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
Contrasting with Symile: Simple Model-Agnostic Representation Learning for Unlimited Modalities
Nov 01, 2024



Contrastive learning methods, such as CLIP, leverage naturally paired data-for example, images and their corresponding text captions-to learn general representations that transfer efficiently to downstream tasks. While such approaches are generally applied to two modalities, domains such as robotics, healthcare, and video need to support many types of data at once. We show that the pairwise application of CLIP fails to capture joint information between modalities, thereby limiting the quality of the learned representations. To address this issue, we present Symile, a simple contrastive learning approach that captures higher-order information between any number of modalities. Symile provides a flexible, architecture-agnostic objective for learning modality-specific representations. To develop Symile's objective, we derive a lower bound on total correlation, and show that Symile representations for any set of modalities form a sufficient statistic for predicting the remaining modalities. Symile outperforms pairwise CLIP, even with modalities missing in the data, on cross-modal classification and retrieval across several experiments including on an original multilingual dataset of 33M image, text and audio samples and a clinical dataset of chest X-rays, electrocardiograms, and laboratory measurements. All datasets and code used in this work are publicly available at https://github.com/rajesh-lab/symile.
Robust Anomaly Detection for Particle Physics Using Multi-Background Representation Learning
Jan 16, 2024Anomaly, or out-of-distribution, detection is a promising tool for aiding discoveries of new particles or processes in particle physics. In this work, we identify and address two overlooked opportunities to improve anomaly detection for high-energy physics. First, rather than train a generative model on the single most dominant background process, we build detection algorithms using representation learning from multiple background types, thus taking advantage of more information to improve estimation of what is relevant for detection. Second, we generalize decorrelation to the multi-background setting, thus directly enforcing a more complete definition of robustness for anomaly detection. We demonstrate the benefit of the proposed robust multi-background anomaly detection algorithms on a high-dimensional dataset of particle decays at the Large Hadron Collider.
Don't blame Dataset Shift! Shortcut Learning due to Gradients and Cross Entropy
Aug 24, 2023



Common explanations for shortcut learning assume that the shortcut improves prediction under the training distribution but not in the test distribution. Thus, models trained via the typical gradient-based optimization of cross-entropy, which we call default-ERM, utilize the shortcut. However, even when the stable feature determines the label in the training distribution and the shortcut does not provide any additional information, like in perception tasks, default-ERM still exhibits shortcut learning. Why are such solutions preferred when the loss for default-ERM can be driven to zero using the stable feature alone? By studying a linear perception task, we show that default-ERM's preference for maximizing the margin leads to models that depend more on the shortcut than the stable feature, even without overparameterization. This insight suggests that default-ERM's implicit inductive bias towards max-margin is unsuitable for perception tasks. Instead, we develop an inductive bias toward uniform margins and show that this bias guarantees dependence only on the perfect stable feature in the linear perception task. We develop loss functions that encourage uniform-margin solutions, called margin control (MARG-CTRL). MARG-CTRL mitigates shortcut learning on a variety of vision and language tasks, showing that better inductive biases can remove the need for expensive two-stage shortcut-mitigating methods in perception tasks.
When More is Less: Incorporating Additional Datasets Can Hurt Performance By Introducing Spurious Correlations
Aug 08, 2023



In machine learning, incorporating more data is often seen as a reliable strategy for improving model performance; this work challenges that notion by demonstrating that the addition of external datasets in many cases can hurt the resulting model's performance. In a large-scale empirical study across combinations of four different open-source chest x-ray datasets and 9 different labels, we demonstrate that in 43% of settings, a model trained on data from two hospitals has poorer worst group accuracy over both hospitals than a model trained on just a single hospital's data. This surprising result occurs even though the added hospital makes the training distribution more similar to the test distribution. We explain that this phenomenon arises from the spurious correlation that emerges between the disease and hospital, due to hospital-specific image artifacts. We highlight the trade-off one encounters when training on multiple datasets, between the obvious benefit of additional data and insidious cost of the introduced spurious correlation. In some cases, balancing the dataset can remove the spurious correlation and improve performance, but it is not always an effective strategy. We contextualize our results within the literature on spurious correlations to help explain these outcomes. Our experiments underscore the importance of exercising caution when selecting training data for machine learning models, especially in settings where there is a risk of spurious correlations such as with medical imaging. The risks outlined highlight the need for careful data selection and model evaluation in future research and practice.
A dynamic risk score for early prediction of cardiogenic shock using machine learning
Mar 28, 2023



Myocardial infarction and heart failure are major cardiovascular diseases that affect millions of people in the US. The morbidity and mortality are highest among patients who develop cardiogenic shock. Early recognition of cardiogenic shock is critical. Prompt implementation of treatment measures can prevent the deleterious spiral of ischemia, low blood pressure, and reduced cardiac output due to cardiogenic shock. However, early identification of cardiogenic shock has been challenging due to human providers' inability to process the enormous amount of data in the cardiac intensive care unit (ICU) and lack of an effective risk stratification tool. We developed a deep learning-based risk stratification tool, called CShock, for patients admitted into the cardiac ICU with acute decompensated heart failure and/or myocardial infarction to predict onset of cardiogenic shock. To develop and validate CShock, we annotated cardiac ICU datasets with physician adjudicated outcomes. CShock achieved an area under the receiver operator characteristic curve (AUROC) of 0.820, which substantially outperformed CardShock (AUROC 0.519), a well-established risk score for cardiogenic shock prognosis. CShock was externally validated in an independent patient cohort and achieved an AUROC of 0.800, demonstrating its generalizability in other cardiac ICUs.
Nuisances via Negativa: Adjusting for Spurious Correlations via Data Augmentation
Oct 04, 2022



There exist features that are related to the label in the same way across different settings for that task; these are semantic features or semantics. Features with varying relationships to the label are nuisances. For example, in detecting cows from natural images, the shape of the head is a semantic and because images of cows often have grass backgrounds but only in certain settings, the background is a nuisance. Relationships between a nuisance and the label are unstable across settings and, consequently, models that exploit nuisance-label relationships face performance degradation when these relationships change. Direct knowledge of a nuisance helps build models that are robust to such changes, but knowledge of a nuisance requires extra annotations beyond the label and the covariates. In this paper, we develop an alternative way to produce robust models by data augmentation. These data augmentations corrupt semantic information to produce models that identify and adjust for where nuisances drive predictions. We study semantic corruptions in powering different robust-modeling methods for multiple out-of distribution (OOD) tasks like classifying waterbirds, natural language inference, and detecting Cardiomegaly in chest X-rays.
New-Onset Diabetes Assessment Using Artificial Intelligence-Enhanced Electrocardiography
May 05, 2022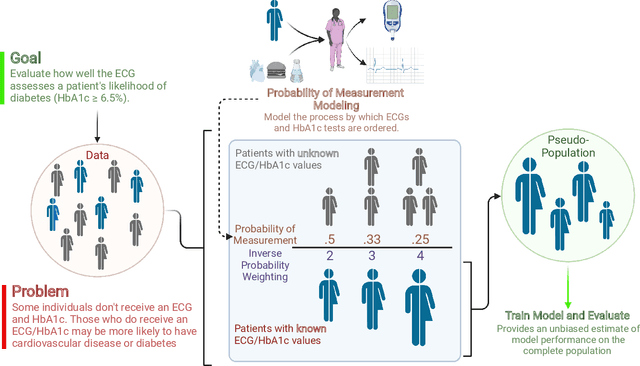
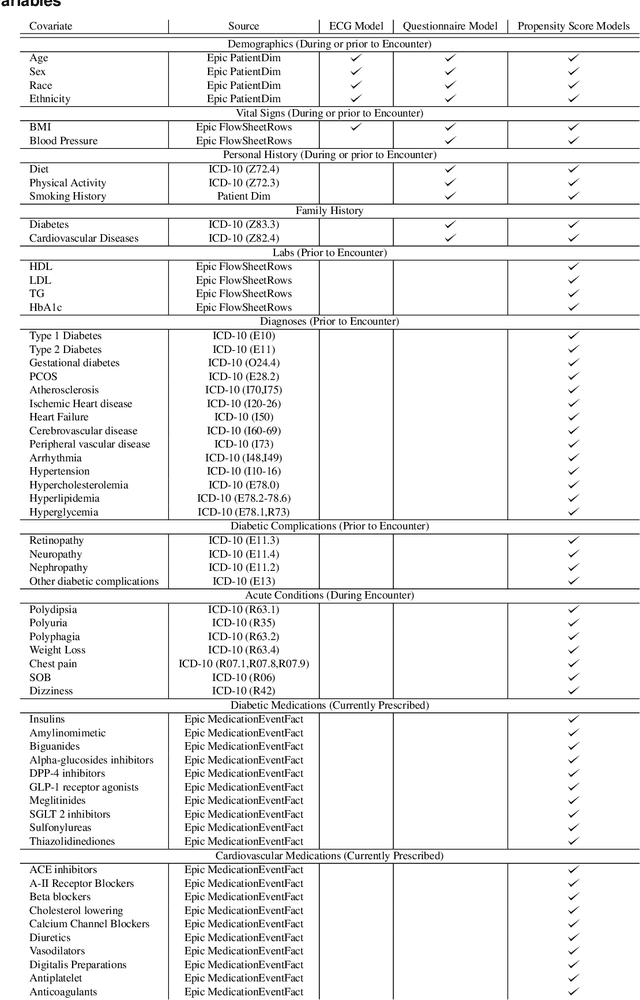
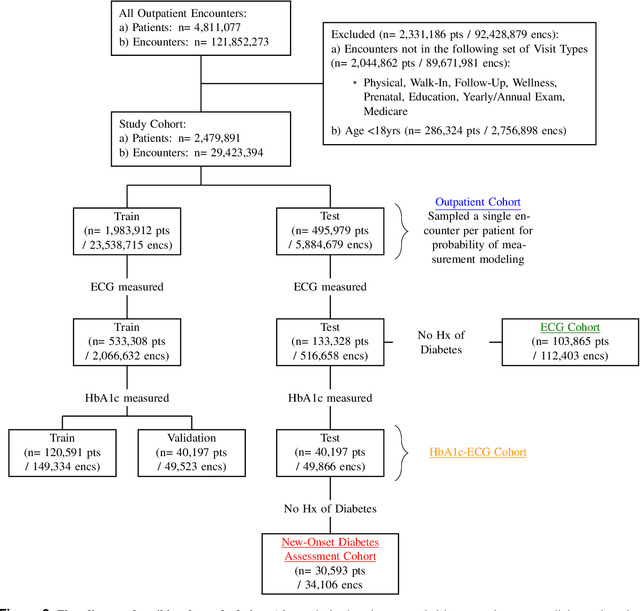
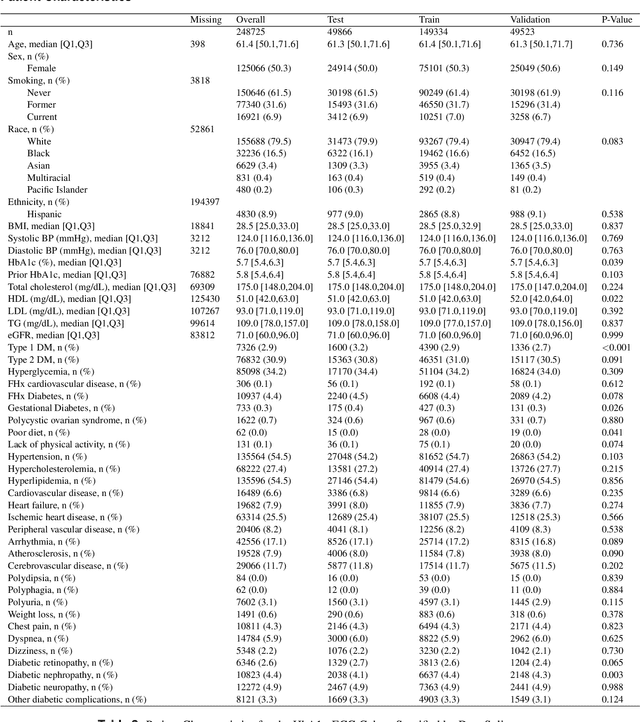
Undiagnosed diabetes is present in 21.4% of adults with diabetes. Diabetes can remain asymptomatic and undetected due to limitations in screening rates. To address this issue, questionnaires, such as the American Diabetes Association (ADA) Risk test, have been recommended for use by physicians and the public. Based on evidence that blood glucose concentration can affect cardiac electrophysiology, we hypothesized that an artificial intelligence (AI)-enhanced electrocardiogram (ECG) could identify adults with new-onset diabetes. We trained a neural network to estimate HbA1c using a 12-lead ECG and readily available demographics. We retrospectively assembled a dataset comprised of patients with paired ECG and HbA1c data. The population of patients who receive both an ECG and HbA1c may a biased sample of the complete outpatient population, so we adjusted the importance placed on each patient to generate a more representative pseudo-population. We found ECG-based assessment outperforms the ADA Risk test, achieving a higher area under the curve (0.80 vs. 0.68) and positive predictive value (14% vs. 9%) -- 2.6 times the prevalence of diabetes in the cohort. The AI-enhanced ECG significantly outperforms electrophysiologist interpretation of the ECG, suggesting that the task is beyond current clinical capabilities. Given the prevalence of ECGs in clinics and via wearable devices, such a tool would make precise, automated diabetes assessment widely accessible.