 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetween Linear and Sinusoidal: Rethinking the Time Encoder in Dynamic Graph Learning
Apr 10, 2025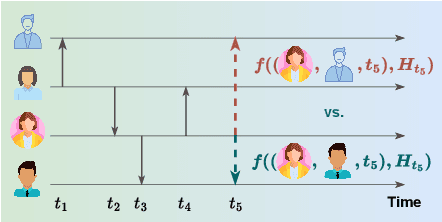
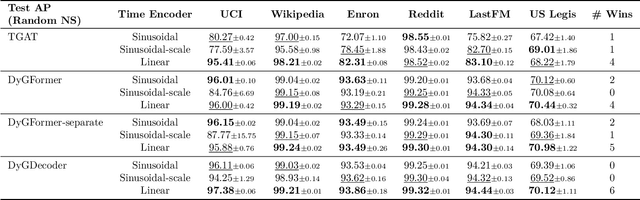


Dynamic graph learning is essential for applications involving temporal networks and requires effective modeling of temporal relationships. Seminal attention-based models like TGAT and DyGFormer rely on sinusoidal time encoders to capture temporal relationships between edge events. In this paper, we study a simpler alternative: the linear time encoder, which avoids temporal information loss caused by sinusoidal functions and reduces the need for high dimensional time encoders. We show that the self-attention mechanism can effectively learn to compute time spans from linear time encodings and extract relevant temporal patterns. Through extensive experiments on six dynamic graph datasets, we demonstrate that the linear time encoder improves the performance of TGAT and DyGFormer in most cases. Moreover, the linear time encoder can lead to significant savings in model parameters with minimal performance loss. For example, compared to a 100-dimensional sinusoidal time encoder, TGAT with a 2-dimensional linear time encoder saves 43% of parameters and achieves higher average precision on five datasets. These results can be readily used to positively impact the design choices of a wide variety of dynamic graph learning architectures. The experimental code is available at: https://github.com/hsinghuan/dg-linear-time.git.
Time After Time: Deep-Q Effect Estimation for Interventions on When and What to do
Mar 20, 2025



Problems in fields such as healthcare, robotics, and finance requires reasoning about the value both of what decision or action to take and when to take it. The prevailing hope is that artificial intelligence will support such decisions by estimating the causal effect of policies such as how to treat patients or how to allocate resources over time. However, existing methods for estimating the effect of a policy struggle with \emph{irregular time}. They either discretize time, or disregard the effect of timing policies. We present a new deep-Q algorithm that estimates the effect of both when and what to do called Earliest Disagreement Q-Evaluation (EDQ). EDQ makes use of recursion for the Q-function that is compatible with flexible sequence models, such as transformers. EDQ provides accurate estimates under standard assumptions. We validate the approach through experiments on survival time and tumor growth tasks.
Weighted Risk Invariance: Domain Generalization under Invariant Feature Shift
Jul 25, 2024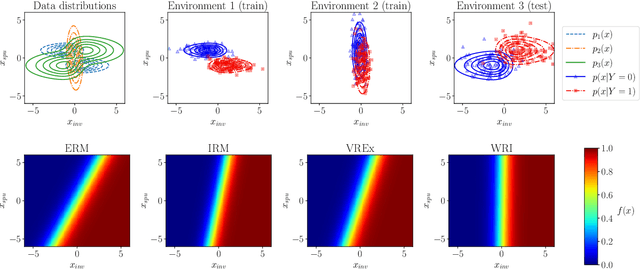
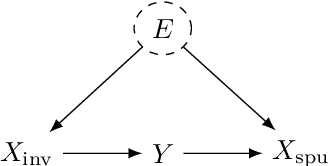

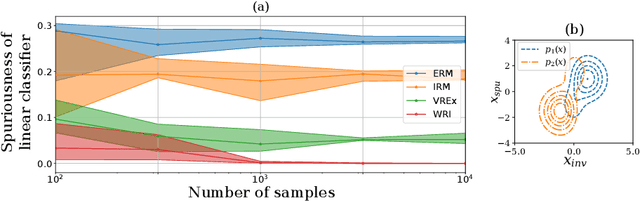
Learning models whose predictions are invariant under multiple environments is a promising approach for out-of-distribution generalization. Such models are trained to extract features $X_{\text{inv}}$ where the conditional distribution $Y \mid X_{\text{inv}}$ of the label given the extracted features does not change across environments. Invariant models are also supposed to generalize to shifts in the marginal distribution $p(X_{\text{inv}})$ of the extracted features $X_{\text{inv}}$, a type of shift we call an $\textit{invariant covariate shift}$. However, we show that proposed methods for learning invariant models underperform under invariant covariate shift, either failing to learn invariant models$\unicode{x2014}$even for data generated from simple and well-studied linear-Gaussian models$\unicode{x2014}$or having poor finite-sample performance. To alleviate these problems, we propose $\textit{weighted risk invariance}$ (WRI). Our framework is based on imposing invariance of the loss across environments subject to appropriate reweightings of the training examples. We show that WRI provably learns invariant models, i.e. discards spurious correlations, in linear-Gaussian settings. We propose a practical algorithm to implement WRI by learning the density $p(X_{\text{inv}})$ and the model parameters simultaneously, and we demonstrate empirically that WRI outperforms previous invariant learning methods under invariant covariate shift.
Novel Node Category Detection Under Subpopulation Shift
Apr 01, 2024



In real-world graph data, distribution shifts can manifest in various ways, such as the emergence of new categories and changes in the relative proportions of existing categories. It is often important to detect nodes of novel categories under such distribution shifts for safety or insight discovery purposes. We introduce a new approach, Recall-Constrained Optimization with Selective Link Prediction (RECO-SLIP), to detect nodes belonging to novel categories in attributed graphs under subpopulation shifts. By integrating a recall-constrained learning framework with a sample-efficient link prediction mechanism, RECO-SLIP addresses the dual challenges of resilience against subpopulation shifts and the effective exploitation of graph structure. Our extensive empirical evaluation across multiple graph datasets demonstrates the superior performance of RECO-SLIP over existing methods.
Causal-structure Driven Augmentations for Text OOD Generalization
Oct 19, 2023



The reliance of text classifiers on spurious correlations can lead to poor generalization at deployment, raising concerns about their use in safety-critical domains such as healthcare. In this work, we propose to use counterfactual data augmentation, guided by knowledge of the causal structure of the data, to simulate interventions on spurious features and to learn more robust text classifiers. We show that this strategy is appropriate in prediction problems where the label is spuriously correlated with an attribute. Under the assumptions of such problems, we discuss the favorable sample complexity of counterfactual data augmentation, compared to importance re-weighting. Pragmatically, we match examples using auxiliary data, based on diff-in-diff methodology, and use a large language model (LLM) to represent a conditional probability of text. Through extensive experimentation on learning caregiver-invariant predictors of clinical diagnoses from medical narratives and on semi-synthetic data, we demonstrate that our method for simulating interventions improves out-of-distribution (OOD) accuracy compared to baseline invariant learning algorithms.
Don't blame Dataset Shift! Shortcut Learning due to Gradients and Cross Entropy
Aug 24, 2023



Common explanations for shortcut learning assume that the shortcut improves prediction under the training distribution but not in the test distribution. Thus, models trained via the typical gradient-based optimization of cross-entropy, which we call default-ERM, utilize the shortcut. However, even when the stable feature determines the label in the training distribution and the shortcut does not provide any additional information, like in perception tasks, default-ERM still exhibits shortcut learning. Why are such solutions preferred when the loss for default-ERM can be driven to zero using the stable feature alone? By studying a linear perception task, we show that default-ERM's preference for maximizing the margin leads to models that depend more on the shortcut than the stable feature, even without overparameterization. This insight suggests that default-ERM's implicit inductive bias towards max-margin is unsuitable for perception tasks. Instead, we develop an inductive bias toward uniform margins and show that this bias guarantees dependence only on the perfect stable feature in the linear perception task. We develop loss functions that encourage uniform-margin solutions, called margin control (MARG-CTRL). MARG-CTRL mitigates shortcut learning on a variety of vision and language tasks, showing that better inductive biases can remove the need for expensive two-stage shortcut-mitigating methods in perception tasks.
Malign Overfitting: Interpolation Can Provably Preclude Invariance
Nov 28, 2022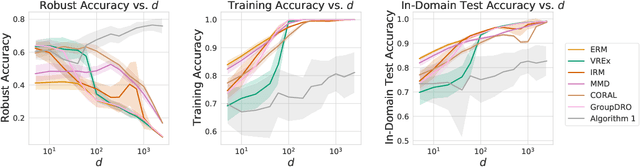
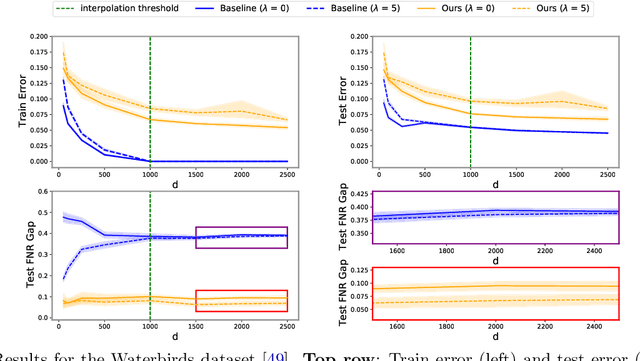
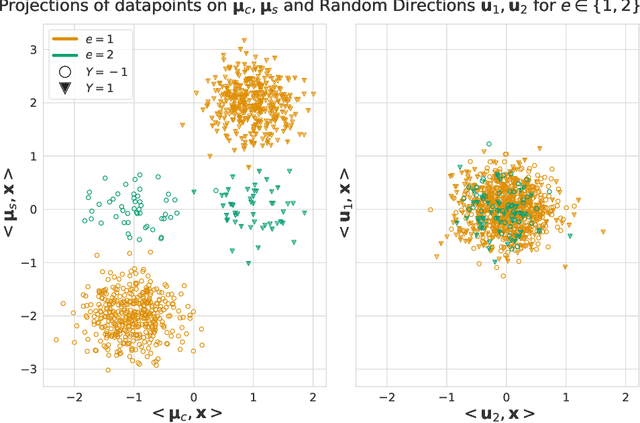
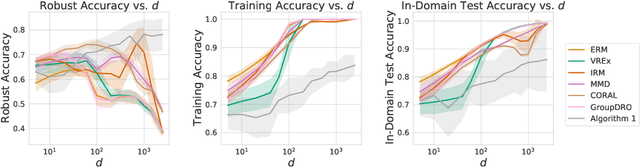
Learned classifiers should often possess certain invariance properties meant to encourage fairness, robustness, or out-of-distribution generalization. However, multiple recent works empirically demonstrate that common invariance-inducing regularizers are ineffective in the over-parameterized regime, in which classifiers perfectly fit (i.e. interpolate) the training data. This suggests that the phenomenon of ``benign overfitting," in which models generalize well despite interpolating, might not favorably extend to settings in which robustness or fairness are desirable. In this work we provide a theoretical justification for these observations. We prove that -- even in the simplest of settings -- any interpolating learning rule (with arbitrarily small margin) will not satisfy these invariance properties. We then propose and analyze an algorithm that -- in the same setting -- successfully learns a non-interpolating classifier that is provably invariant. We validate our theoretical observations on simulated data and the Waterbirds dataset.
In the Eye of the Beholder: Robust Prediction with Causal User Modeling
Jun 01, 2022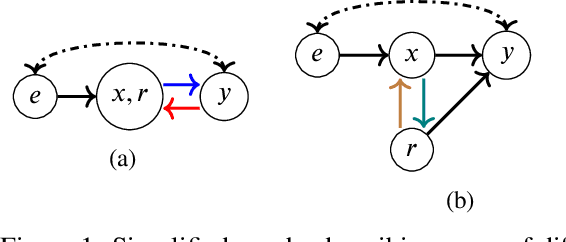

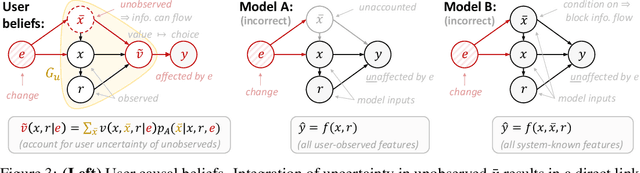
Accurately predicting the relevance of items to users is crucial to the success of many social platforms. Conventional approaches train models on logged historical data; but recommendation systems, media services, and online marketplaces all exhibit a constant influx of new content -- making relevancy a moving target, to which standard predictive models are not robust. In this paper, we propose a learning framework for relevance prediction that is robust to changes in the data distribution. Our key observation is that robustness can be obtained by accounting for how users causally perceive the environment. We model users as boundedly-rational decision makers whose causal beliefs are encoded by a causal graph, and show how minimal information regarding the graph can be used to contend with distributional changes. Experiments in multiple settings demonstrate the effectiveness of our approach.
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
Apr 27, 2021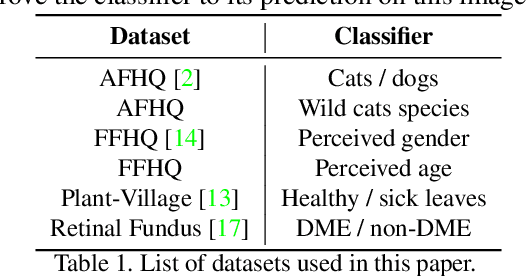
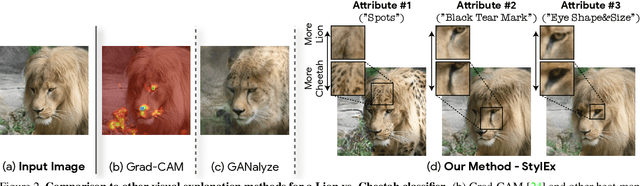
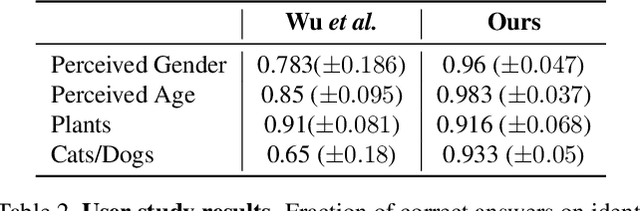
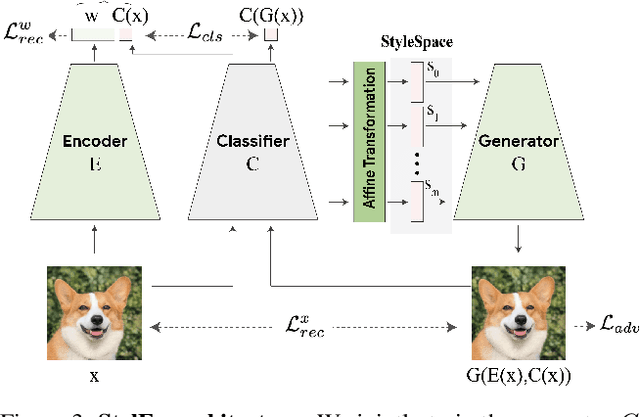
Image classification models can depend on multiple different semantic attributes of the image. An explanation of the decision of the classifier needs to both discover and visualize these properties. Here we present StylEx, a method for doing this, by training a generative model to specifically explain multiple attributes that underlie classifier decisions. A natural source for such attributes is the StyleSpace of StyleGAN, which is known to generate semantically meaningful dimensions in the image. However, because standard GAN training is not dependent on the classifier, it may not represent these attributes which are important for the classifier decision, and the dimensions of StyleSpace may represent irrelevant attributes. To overcome this, we propose a training procedure for a StyleGAN, which incorporates the classifier model, in order to learn a classifier-specific StyleSpace. Explanatory attributes are then selected from this space. These can be used to visualize the effect of changing multiple attributes per image, thus providing image-specific explanations. We apply StylEx to multiple domains, including animals, leaves, faces and retinal images. For these, we show how an image can be modified in different ways to change its classifier output. Our results show that the method finds attributes that align well with semantic ones, generate meaningful image-specific explanations, and are human-interpretable as measured in user-studies.
On Calibration and Out-of-domain Generalization
Feb 20, 2021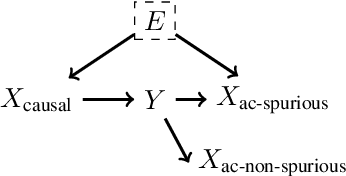

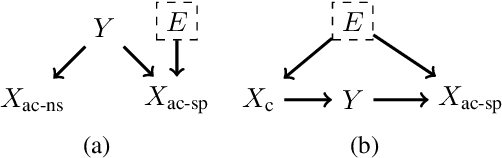
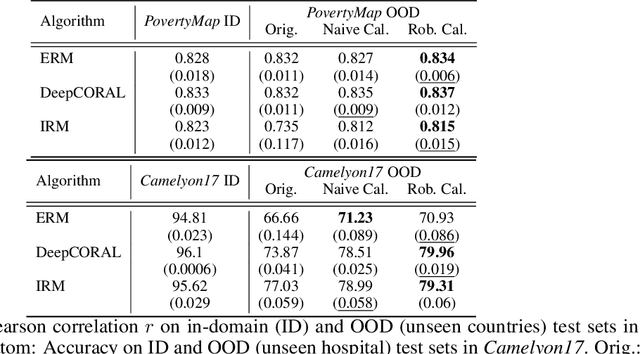
Out-of-domain (OOD) generalization is a significant challenge for machine learning models. To overcome it, many novel techniques have been proposed, often focused on learning models with certain invariance properties. In this work, we draw a link between OOD performance and model calibration, arguing that calibration across multiple domains can be viewed as a special case of an invariant representation leading to better OOD generalization. Specifically, we prove in a simplified setting that models which achieve multi-domain calibration are free of spurious correlations. This leads us to propose multi-domain calibration as a measurable surrogate for the OOD performance of a classifier. An important practical benefit of calibration is that there are many effective tools for calibrating classifiers. We show that these tools are easy to apply and adapt for a multi-domain setting. Using five datasets from the recently proposed WILDS OOD benchmark we demonstrate that simply re-calibrating models across multiple domains in a validation set leads to significantly improved performance on unseen test domains. We believe this intriguing connection between calibration and OOD generalization is promising from a practical point of view and deserves further research from a theoretical point of view.