 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime After Time: Deep-Q Effect Estimation for Interventions on When and What to do
Mar 20, 2025



Problems in fields such as healthcare, robotics, and finance requires reasoning about the value both of what decision or action to take and when to take it. The prevailing hope is that artificial intelligence will support such decisions by estimating the causal effect of policies such as how to treat patients or how to allocate resources over time. However, existing methods for estimating the effect of a policy struggle with \emph{irregular time}. They either discretize time, or disregard the effect of timing policies. We present a new deep-Q algorithm that estimates the effect of both when and what to do called Earliest Disagreement Q-Evaluation (EDQ). EDQ makes use of recursion for the Q-function that is compatible with flexible sequence models, such as transformers. EDQ provides accurate estimates under standard assumptions. We validate the approach through experiments on survival time and tumor growth tasks.
A causal viewpoint on prediction model performance under changes in case-mix: discrimination and calibration respond differently for prognosis and diagnosis predictions
Sep 02, 2024Prediction models inform important clinical decisions, aiding in diagnosis, prognosis, and treatment planning. The predictive performance of these models is typically assessed through discrimination and calibration. However, changes in the distribution of the data impact model performance. In health-care, a typical change is a shift in case-mix: for example, for cardiovascular risk managment, a general practitioner sees a different mix of patients than a specialist in a tertiary hospital. This work introduces a novel framework that differentiates the effects of case-mix shifts on discrimination and calibration based on the causal direction of the prediction task. When prediction is in the causal direction (often the case for prognosis preditions), calibration remains stable under case-mix shifts, while discrimination does not. Conversely, when predicting in the anti-causal direction (often with diagnosis predictions), discrimination remains stable, but calibration does not. A simulation study and empirical validation using cardiovascular disease prediction models demonstrate the implications of this framework. This framework provides critical insights for evaluating and deploying prediction models across different clinical settings, emphasizing the importance of understanding the causal structure of the prediction task.
When accurate prediction models yield harmful self-fulfilling prophecies
Dec 06, 2023


Prediction models are popular in medical research and practice. By predicting an outcome of interest for specific patients, these models may help inform difficult treatment decisions, and are often hailed as the poster children for personalized, data-driven healthcare. We show however, that using prediction models for decision making can lead to harmful decisions, even when the predictions exhibit good discrimination after deployment. These models are harmful self-fulfilling prophecies: their deployment harms a group of patients but the worse outcome of these patients does not invalidate the predictive power of the model. Our main result is a formal characterization of a set of such prediction models. Next we show that models that are well calibrated before and after deployment are useless for decision making as they made no change in the data distribution. These results point to the need to revise standard practices for validation, deployment and evaluation of prediction models that are used in medical decisions.
Decision making in cancer: Causal questions require causal answers
Sep 15, 2022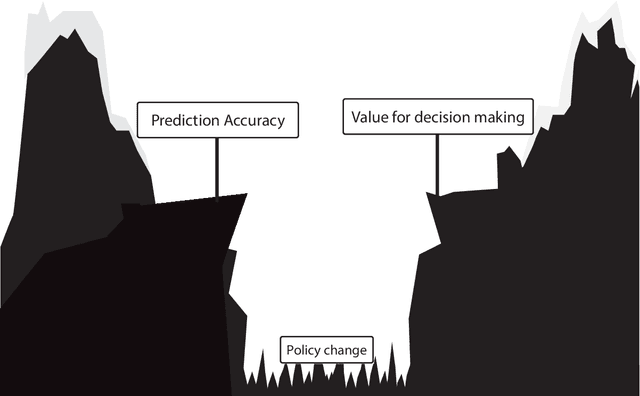
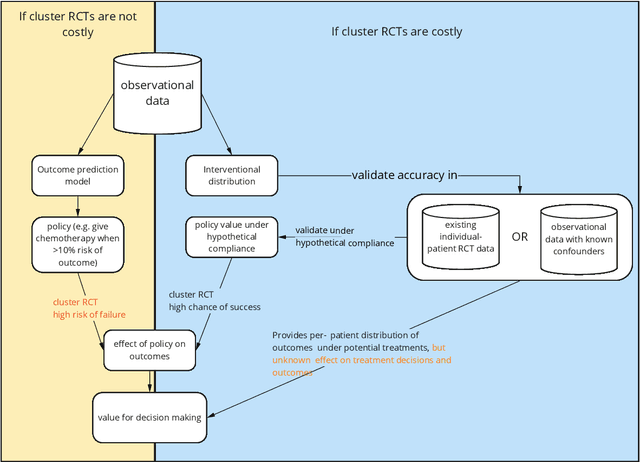
Treatment decisions in cancer care are guided by treatment effect estimates from randomized controlled trials (RCTs). RCTs estimate the average effect of one treatment versus another in a certain population. However, treatments may not be equally effective for every patient in a population. Knowing the effectiveness of treatments tailored to specific patient and tumor characteristics would enable individualized treatment decisions. Getting tailored treatment effects by averaging outcomes in different patient subgroups in RCTs requires an unfeasible number of patients to have sufficient statistical power in all relevant subgroups for all possible treatments. The American Joint Committee on Cancer (AJCC) recommends that researchers develop outcome prediction models (OPMs) in an effort to individualize treatment decisions. OPMs sometimes called risk models or prognosis models, use patient and tumor characteristics to predict a patient outcome such as overall survival. The assumption is that the predictions are useful for treatment decisions using rules such as "prescribe chemotherapy only if the OPM predicts the patient has a high risk of recurrence". Recognizing the importance of reliable predictions, the AJCC published a checklist for OPMs to ensure dependable OPM prediction accuracy in the patient population for which the OPM was designed. However, accurate outcome predictions do not imply that these predictions yield good treatment decisions. In this perspective, we show that OPM rely on a fixed treatment policy which implies that OPM that were found to accurately predict outcomes in validation studies can still lead to patient harm when used to inform treatment decisions. We then give guidance on how to develop models that are useful for individualized treatment decisions and how to evaluate whether a model has value for decision-making.
Controlling for Biasing Signals in Images for Prognostic Models: Survival Predictions for Lung Cancer with Deep Learning
Apr 01, 2019



Deep learning has shown remarkable results for image analysis and is expected to aid individual treatment decisions in health care. To achieve this, deep learning methods need to be promoted from the level of mere associations to being able to answer causal questions. We present a scenario with real-world medical images (CT-scans of lung cancers) and simulated outcome data. Through the sampling scheme, the images contain two distinct factors of variation that represent a collider and a prognostic factor. We show that when this collider can be quantified, unbiased individual prognosis predictions are attainable with deep learning. This is achieved by (1) setting a dual task for the network to predict both the outcome and the collider and (2) enforcing independence of the activation distributions of the last layer with ordinary least squares. Our method provides an example of combining deep learning and structural causal models for unbiased individual prognosis predictions.