 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpty Shelves or Lost Keys? Recall Is the Bottleneck for Parametric Factuality
Feb 15, 2026Standard factuality evaluations of LLMs treat all errors alike, obscuring whether failures arise from missing knowledge (empty shelves) or from limited access to encoded facts (lost keys). We propose a behavioral framework that profiles factual knowledge at the level of facts rather than questions, characterizing each fact by whether it is encoded, and then by how accessible it is: cannot be recalled, can be directly recalled, or can only be recalled with inference-time computation (thinking). To support such profiling, we introduce WikiProfile, a new benchmark constructed via an automated pipeline with a prompted LLM grounded in web search. Across 4 million responses from 13 LLMs, we find that encoding is nearly saturated in frontier models on our benchmark, with GPT-5 and Gemini-3 encoding 95--98% of facts. However, recall remains a major bottleneck: many errors previously attributed to missing knowledge instead stem from failures to access it. These failures are systematic and disproportionately affect long-tail facts and reverse questions. Finally, we show that thinking improves recall and can recover a substantial fraction of failures, indicating that future gains may rely less on scaling and more on methods that improve how models utilize what they already encode.
SimpleQA Verified: A Reliable Factuality Benchmark to Measure Parametric Knowledge
Sep 09, 2025



We introduce SimpleQA Verified, a 1,000-prompt benchmark for evaluating Large Language Model (LLM) short-form factuality based on OpenAI's SimpleQA. It addresses critical limitations in OpenAI's benchmark, including noisy and incorrect labels, topical biases, and question redundancy. SimpleQA Verified was created through a rigorous multi-stage filtering process involving de-duplication, topic balancing, and source reconciliation to produce a more reliable and challenging evaluation set, alongside improvements in the autorater prompt. On this new benchmark, Gemini 2.5 Pro achieves a state-of-the-art F1-score of 55.6, outperforming other frontier models, including GPT-5. This work provides the research community with a higher-fidelity tool to track genuine progress in parametric model factuality and to mitigate hallucinations. The benchmark dataset, evaluation code, and leaderboard are available at: https://www.kaggle.com/benchmarks/deepmind/simpleqa-verified.
MetaFaith: Faithful Natural Language Uncertainty Expression in LLMs
May 30, 2025A critical component in the trustworthiness of LLMs is reliable uncertainty communication, yet LLMs often use assertive language when conveying false claims, leading to over-reliance and eroded trust. We present the first systematic study of $\textit{faithful confidence calibration}$ of LLMs, benchmarking models' ability to use linguistic expressions of uncertainty that $\textit{faithfully reflect}$ their intrinsic uncertainty, across a comprehensive array of models, datasets, and prompting strategies. Our results demonstrate that LLMs largely fail at this task, and that existing interventions are insufficient: standard prompt approaches provide only marginal gains, and existing, factuality-based calibration techniques can even harm faithful calibration. To address this critical gap, we introduce MetaFaith, a novel prompt-based calibration approach inspired by human metacognition. We show that MetaFaith robustly improves faithful calibration across diverse models and task domains, enabling up to 61% improvement in faithfulness and achieving an 83% win rate over original generations as judged by humans.
Neural Descriptors: Self-Supervised Learning of Robust Local Surface Descriptors Using Polynomial Patches
Mar 05, 2025Classical shape descriptors such as Heat Kernel Signature (HKS), Wave Kernel Signature (WKS), and Signature of Histograms of OrienTations (SHOT), while widely used in shape analysis, exhibit sensitivity to mesh connectivity, sampling patterns, and topological noise. While differential geometry offers a promising alternative through its theory of differential invariants, which are theoretically guaranteed to be robust shape descriptors, the computation of these invariants on discrete meshes often leads to unstable numerical approximations, limiting their practical utility. We present a self-supervised learning approach for extracting geometric features from 3D surfaces. Our method combines synthetic data generation with a neural architecture designed to learn sampling-invariant features. By integrating our features into existing shape correspondence frameworks, we demonstrate improved performance on standard benchmarks including FAUST, SCAPE, TOPKIDS, and SHREC'16, showing particular robustness to topological noise and partial shapes.
Confidence Improves Self-Consistency in LLMs
Feb 10, 2025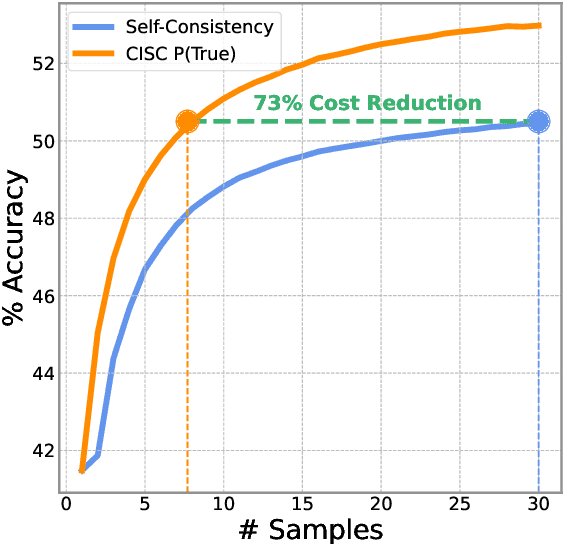
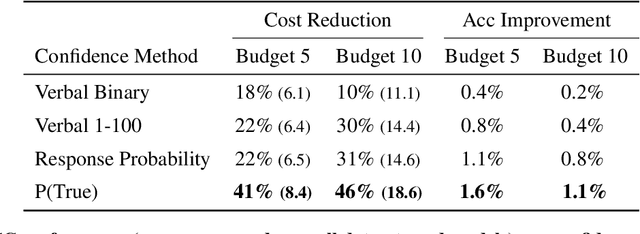

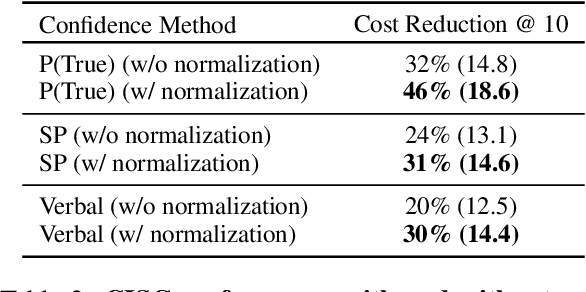
Self-consistency decoding enhances LLMs' performance on reasoning tasks by sampling diverse reasoning paths and selecting the most frequent answer. However, it is computationally expensive, as sampling many of these (lengthy) paths is required to increase the chances that the correct answer emerges as the most frequent one. To address this, we introduce Confidence-Informed Self-Consistency (CISC). CISC performs a weighted majority vote based on confidence scores obtained directly from the model. By prioritizing high-confidence paths, it can identify the correct answer with a significantly smaller sample size. When tested on nine models and four datasets, CISC outperforms self-consistency in nearly all configurations, reducing the required number of reasoning paths by over 40% on average. In addition, we introduce the notion of within-question confidence evaluation, after showing that standard evaluation methods are poor predictors of success in distinguishing correct and incorrect answers to the same question. In fact, the most calibrated confidence method proved to be the least effective for CISC. Lastly, beyond these practical implications, our results and analyses show that LLMs can effectively judge the correctness of their own outputs, contributing to the ongoing debate on this topic.
Pathways on the Image Manifold: Image Editing via Video Generation
Nov 25, 2024
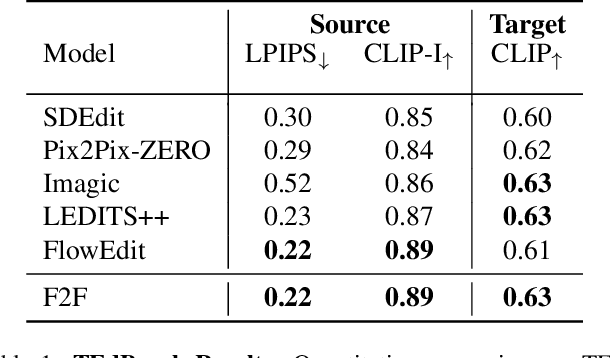
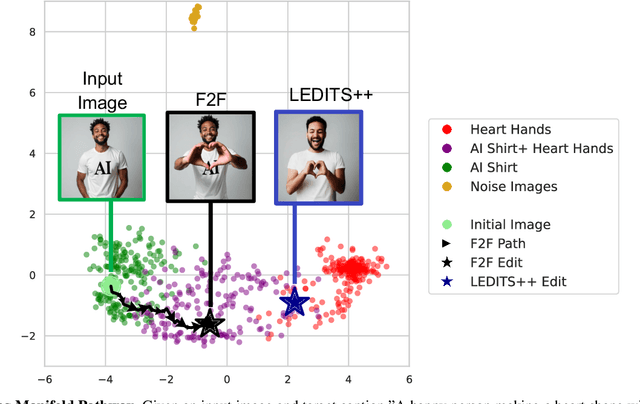
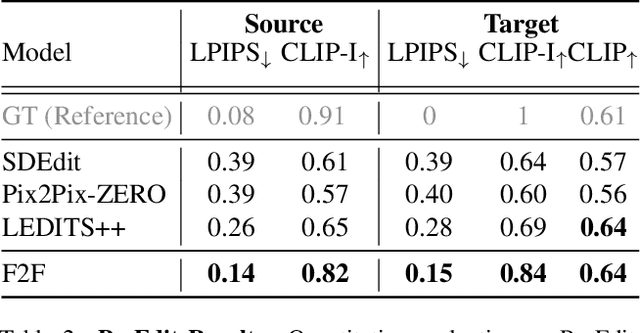
Recent advances in image editing, driven by image diffusion models, have shown remarkable progress. However, significant challenges remain, as these models often struggle to follow complex edit instructions accurately and frequently compromise fidelity by altering key elements of the original image. Simultaneously, video generation has made remarkable strides, with models that effectively function as consistent and continuous world simulators. In this paper, we propose merging these two fields by utilizing image-to-video models for image editing. We reformulate image editing as a temporal process, using pretrained video models to create smooth transitions from the original image to the desired edit. This approach traverses the image manifold continuously, ensuring consistent edits while preserving the original image's key aspects. Our approach achieves state-of-the-art results on text-based image editing, demonstrating significant improvements in both edit accuracy and image preservation.
Keep Guessing? When Considering Inference Scaling, Mind the Baselines
Oct 20, 2024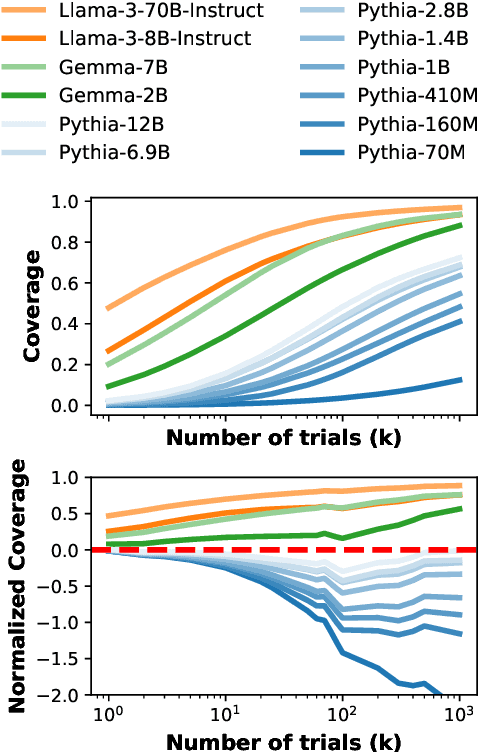
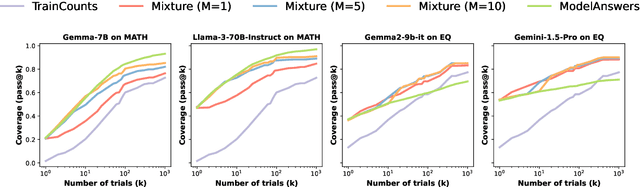
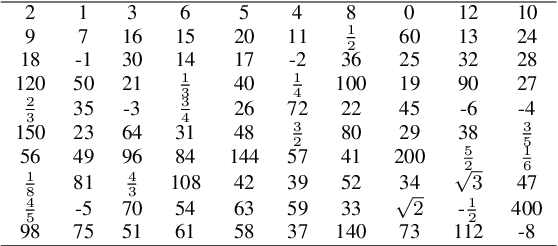

Scaling inference compute in large language models (LLMs) through repeated sampling consistently increases the coverage (fraction of problems solved) as the number of samples increases. We conjecture that this observed improvement is partially due to the answer distribution of standard evaluation benchmarks, which is skewed towards a relatively small set of common answers. To test this conjecture, we define a baseline that enumerates answers according to their prevalence in the training set. Experiments spanning two domains -- mathematical reasoning and factual knowledge -- reveal that this baseline outperforms repeated model sampling for some LLMs, while the coverage for others is on par with that of a mixture strategy that obtains $k$ answers by using only $10$ model samples and similarly guessing the remaining $k-10$ attempts via enumeration. Our baseline enables a more accurate measurement of how much repeated sampling improves coverage in such settings beyond prompt-agnostic guessing.
Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
May 27, 2024We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., "I'm not sure, but I think..."). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
May 09, 2024

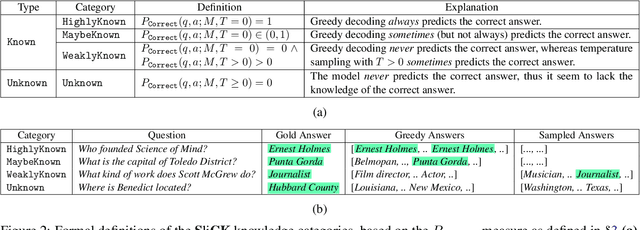
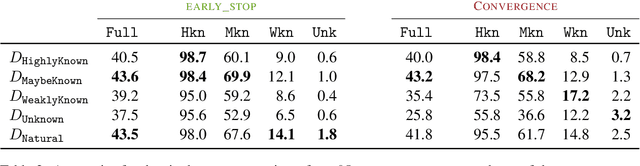
When large language models are aligned via supervised fine-tuning, they may encounter new factual information that was not acquired through pre-training. It is often conjectured that this can teach the model the behavior of hallucinating factually incorrect responses, as the model is trained to generate facts that are not grounded in its pre-existing knowledge. In this work, we study the impact of such exposure to new knowledge on the capability of the fine-tuned model to utilize its pre-existing knowledge. To this end, we design a controlled setup, focused on closed-book QA, where we vary the proportion of the fine-tuning examples that introduce new knowledge. We demonstrate that large language models struggle to acquire new factual knowledge through fine-tuning, as fine-tuning examples that introduce new knowledge are learned significantly slower than those consistent with the model's knowledge. However, we also find that as the examples with new knowledge are eventually learned, they linearly increase the model's tendency to hallucinate. Taken together, our results highlight the risk in introducing new factual knowledge through fine-tuning, and support the view that large language models mostly acquire factual knowledge through pre-training, whereas fine-tuning teaches them to use it more efficiently.
Narrowing the Knowledge Evaluation Gap: Open-Domain Question Answering with Multi-Granularity Answers
Jan 09, 2024Factual questions typically can be answered correctly at different levels of granularity. For example, both ``August 4, 1961'' and ``1961'' are correct answers to the question ``When was Barack Obama born?''. Standard question answering (QA) evaluation protocols, however, do not explicitly take this into account and compare a predicted answer against answers of a single granularity level. In this work, we propose GRANOLA QA, a novel evaluation setting where a predicted answer is evaluated in terms of accuracy and informativeness against a set of multi-granularity answers. We present a simple methodology for enriching existing datasets with multi-granularity answers, and create GRANOLA-EQ, a multi-granularity version of the EntityQuestions dataset. We evaluate a range of decoding methods on GRANOLA-EQ, including a new algorithm, called Decoding with Response Aggregation (DRAG), that is geared towards aligning the response granularity with the model's uncertainty. Our experiments show that large language models with standard decoding tend to generate specific answers, which are often incorrect. In contrast, when evaluated on multi-granularity answers, DRAG yields a nearly 20 point increase in accuracy on average, which further increases for rare entities. Overall, this reveals that standard evaluation and decoding schemes may significantly underestimate the knowledge encapsulated in LMs.