 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaFaith: Faithful Natural Language Uncertainty Expression in LLMs
May 30, 2025A critical component in the trustworthiness of LLMs is reliable uncertainty communication, yet LLMs often use assertive language when conveying false claims, leading to over-reliance and eroded trust. We present the first systematic study of $\textit{faithful confidence calibration}$ of LLMs, benchmarking models' ability to use linguistic expressions of uncertainty that $\textit{faithfully reflect}$ their intrinsic uncertainty, across a comprehensive array of models, datasets, and prompting strategies. Our results demonstrate that LLMs largely fail at this task, and that existing interventions are insufficient: standard prompt approaches provide only marginal gains, and existing, factuality-based calibration techniques can even harm faithful calibration. To address this critical gap, we introduce MetaFaith, a novel prompt-based calibration approach inspired by human metacognition. We show that MetaFaith robustly improves faithful calibration across diverse models and task domains, enabling up to 61% improvement in faithfulness and achieving an 83% win rate over original generations as judged by humans.
MDCure: A Scalable Pipeline for Multi-Document Instruction-Following
Oct 30, 2024


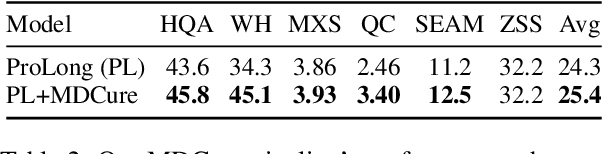
Multi-document (MD) processing is crucial for LLMs to handle real-world tasks such as summarization and question-answering across large sets of documents. While LLMs have improved at processing long inputs, MD contexts still present challenges, such as managing inter-document dependencies, redundancy, and incoherent structures. We introduce MDCure, a scalable and effective fine-tuning pipeline to enhance the MD capabilities of LLMs without the computational cost of pre-training or reliance on human annotated data. MDCure is based on generation of high-quality synthetic MD instruction data from sets of related articles via targeted prompts. We further introduce MDCureRM, a multi-objective reward model which filters generated data based on their training utility for MD settings. With MDCure, we fine-tune a variety of LLMs, from the FlanT5, Qwen2, and LLAMA3.1 model families, up to 70B parameters in size. Extensive evaluations on a wide range of MD and long-context benchmarks spanning various tasks show MDCure consistently improves performance over pre-trained baselines and over corresponding base models by up to 75.5%. Our code, datasets, and models are available at https://github.com/yale-nlp/MDCure.
Perspectives on the Social Impacts of Reinforcement Learning with Human Feedback
Mar 06, 2023
Is it possible for machines to think like humans? And if it is, how should we go about teaching them to do so? As early as 1950, Alan Turing stated that we ought to teach machines in the way of teaching a child. Reinforcement learning with human feedback (RLHF) has emerged as a strong candidate toward allowing agents to learn from human feedback in a naturalistic manner. RLHF is distinct from traditional reinforcement learning as it provides feedback from a human teacher in addition to a reward signal. It has been catapulted into public view by multiple high-profile AI applications, including OpenAI's ChatGPT, DeepMind's Sparrow, and Anthropic's Claude. These highly capable chatbots are already overturning our understanding of how AI interacts with humanity. The wide applicability and burgeoning success of RLHF strongly motivate the need to evaluate its social impacts. In light of recent developments, this paper considers an important question: can RLHF be developed and used without negatively affecting human societies? Our objectives are threefold: to provide a systematic study of the social effects of RLHF; to identify key social and ethical issues of RLHF; and to discuss social impacts for stakeholders. Although text-based applications of RLHF have received much attention, it is crucial to consider when evaluating its social implications the diverse range of areas to which it may be deployed. We describe seven primary ways in which RLHF-based technologies will affect society by positively transforming human experiences with AI. This paper ultimately proposes that RLHF has potential to net positively impact areas of misinformation, AI value-alignment, bias, AI access, cross-cultural dialogue, industry, and workforce. As RLHF raises concerns that echo those of existing AI technologies, it will be important for all to be aware and intentional in the adoption of RLHF.
Streaming Inference for Infinite Non-Stationary Clustering
May 02, 2022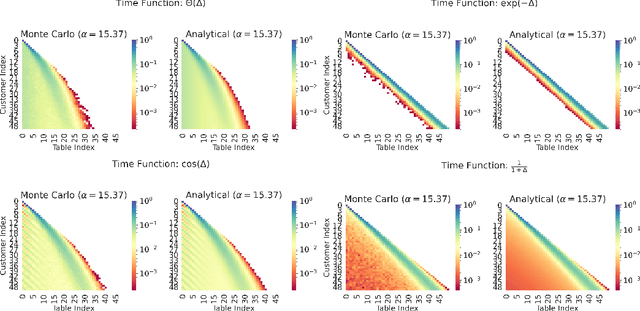



Learning from a continuous stream of non-stationary data in an unsupervised manner is arguably one of the most common and most challenging settings facing intelligent agents. Here, we attack learning under all three conditions (unsupervised, streaming, non-stationary) in the context of clustering, also known as mixture modeling. We introduce a novel clustering algorithm that endows mixture models with the ability to create new clusters online, as demanded by the data, in a probabilistic, time-varying, and principled manner. To achieve this, we first define a novel stochastic process called the Dynamical Chinese Restaurant Process (Dynamical CRP), which is a non-exchangeable distribution over partitions of a set; next, we show that the Dynamical CRP provides a non-stationary prior over cluster assignments and yields an efficient streaming variational inference algorithm. We conclude with experiments showing that the Dynamical CRP can be applied on diverse synthetic and real data with Gaussian and non-Gaussian likelihoods.