 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM Audio Judge: A Unified Multimodal Framework for Perceptual Evaluation of Audio Separation
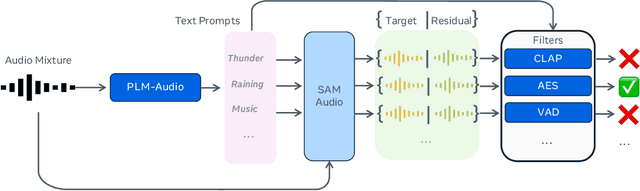
Jan 27, 2026The performance evaluation remains a complex challenge in audio separation, and existing evaluation metrics are often misaligned with human perception, course-grained, relying on ground truth signals. On the other hand, subjective listening tests remain the gold standard for real-world evaluation, but they are expensive, time-consuming, and difficult to scale. This paper addresses the growing need for automated systems capable of evaluating audio separation without human intervention. The proposed evaluation metric, SAM Audio Judge (SAJ), is a multimodal fine-grained reference-free objective metric, which shows highly alignment with human perceptions. SAJ supports three audio domains (speech, music and general sound events) and three prompt inputs (text, visual and span), covering four different dimensions of evaluation (recall, percision, faithfulness, and overall). SAM Audio Judge also shows potential applications in data filtering, pseudo-labeling large datasets and reranking in audio separation models. We release our code and pre-trained models at: https://github.com/facebookresearch/sam-audio.
Mosaic: Unlocking Long-Context Inference for Diffusion LLMs via Global Memory Planning and Dynamic Peak Taming
Jan 10, 2026Diffusion-based large language models (dLLMs) have emerged as a promising paradigm, utilizing simultaneous denoising to enable global planning and iterative refinement. While these capabilities are particularly advantageous for long-context generation, deploying such models faces a prohibitive memory capacity barrier stemming from severe system inefficiencies. We identify that existing inference systems are ill-suited for this paradigm: unlike autoregressive models constrained by the cumulative KV-cache, dLLMs are bottlenecked by transient activations recomputed at every step. Furthermore, general-purpose memory reuse mechanisms lack the global visibility to adapt to dLLMs' dynamic memory peaks, which toggle between logits and FFNs. To address these mismatches, we propose Mosaic, a memory-efficient inference system that shifts from local, static management to a global, dynamic paradigm. Mosaic integrates a mask-only logits kernel to eliminate redundancy, a lazy chunking optimizer driven by an online heuristic search to adaptively mitigate dynamic peaks, and a global memory manager to resolve fragmentation via virtual addressing. Extensive evaluations demonstrate that Mosaic achieves an average 2.71$\times$ reduction in the memory peak-to-average ratio and increases the maximum inference sequence length supportable on identical hardware by 15.89-32.98$\times$. This scalability is achieved without compromising accuracy and speed, and in fact reducing latency by 4.12%-23.26%.
SAM Audio: Segment Anything in Audio
Dec 19, 2025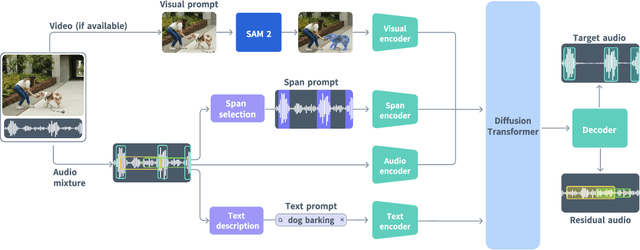

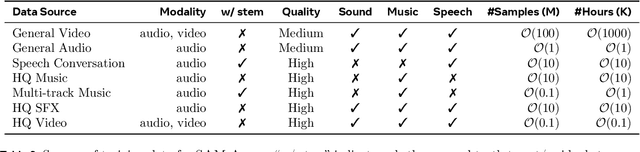
General audio source separation is a key capability for multimodal AI systems that can perceive and reason about sound. Despite substantial progress in recent years, existing separation models are either domain-specific, designed for fixed categories such as speech or music, or limited in controllability, supporting only a single prompting modality such as text. In this work, we present SAM Audio, a foundation model for general audio separation that unifies text, visual, and temporal span prompting within a single framework. Built on a diffusion transformer architecture, SAM Audio is trained with flow matching on large-scale audio data spanning speech, music, and general sounds, and can flexibly separate target sources described by language, visual masks, or temporal spans. The model achieves state-of-the-art performance across a diverse suite of benchmarks, including general sound, speech, music, and musical instrument separation in both in-the-wild and professionally produced audios, substantially outperforming prior general-purpose and specialized systems. Furthermore, we introduce a new real-world separation benchmark with human-labeled multimodal prompts and a reference-free evaluation model that correlates strongly with human judgment.
NeuroBreak: Unveil Internal Jailbreak Mechanisms in Large Language Models
Sep 04, 2025In deployment and application, large language models (LLMs) typically undergo safety alignment to prevent illegal and unethical outputs. However, the continuous advancement of jailbreak attack techniques, designed to bypass safety mechanisms with adversarial prompts, has placed increasing pressure on the security defenses of LLMs. Strengthening resistance to jailbreak attacks requires an in-depth understanding of the security mechanisms and vulnerabilities of LLMs. However, the vast number of parameters and complex structure of LLMs make analyzing security weaknesses from an internal perspective a challenging task. This paper presents NeuroBreak, a top-down jailbreak analysis system designed to analyze neuron-level safety mechanisms and mitigate vulnerabilities. We carefully design system requirements through collaboration with three experts in the field of AI security. The system provides a comprehensive analysis of various jailbreak attack methods. By incorporating layer-wise representation probing analysis, NeuroBreak offers a novel perspective on the model's decision-making process throughout its generation steps. Furthermore, the system supports the analysis of critical neurons from both semantic and functional perspectives, facilitating a deeper exploration of security mechanisms. We conduct quantitative evaluations and case studies to verify the effectiveness of our system, offering mechanistic insights for developing next-generation defense strategies against evolving jailbreak attacks.
METEOR: Multi-Encoder Collaborative Token Pruning for Efficient Vision Language Models
Jul 28, 2025Vision encoders serve as the cornerstone of multimodal understanding. Single-encoder architectures like CLIP exhibit inherent constraints in generalizing across diverse multimodal tasks, while recent multi-encoder fusion methods introduce prohibitive computational overhead to achieve superior performance using complementary visual representations from multiple vision encoders. To address this, we propose a progressive pruning framework, namely Multi-Encoder collaboraTivE tOken pRuning (METEOR), that eliminates redundant visual tokens across the encoding, fusion, and decoding stages for multi-encoder MLLMs. For multi-vision encoding, we discard redundant tokens within each encoder via a rank guided collaborative token assignment strategy. Subsequently, for multi-vision fusion, we combine the visual features from different encoders while reducing cross-encoder redundancy with cooperative pruning. Finally, we propose an adaptive token pruning method in the LLM decoding stage to further discard irrelevant tokens based on the text prompts with dynamically adjusting pruning ratios for specific task demands. To our best knowledge, this is the first successful attempt that achieves an efficient multi-encoder based vision language model with multi-stage pruning strategies. Extensive experiments on 11 benchmarks demonstrate the effectiveness of our proposed approach. Compared with EAGLE, a typical multi-encoder MLLMs, METEOR reduces 76% visual tokens with only 0.3% performance drop in average. The code is available at https://github.com/YuchenLiu98/METEOR.
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Feb 07, 2025



The quantification of audio aesthetics remains a complex challenge in audio processing, primarily due to its subjective nature, which is influenced by human perception and cultural context. Traditional methods often depend on human listeners for evaluation, leading to inconsistencies and high resource demands. This paper addresses the growing need for automated systems capable of predicting audio aesthetics without human intervention. Such systems are crucial for applications like data filtering, pseudo-labeling large datasets, and evaluating generative audio models, especially as these models become more sophisticated. In this work, we introduce a novel approach to audio aesthetic evaluation by proposing new annotation guidelines that decompose human listening perspectives into four distinct axes. We develop and train no-reference, per-item prediction models that offer a more nuanced assessment of audio quality. Our models are evaluated against human mean opinion scores (MOS) and existing methods, demonstrating comparable or superior performance. This research not only advances the field of audio aesthetics but also provides open-source models and datasets to facilitate future work and benchmarking. We release our code and pre-trained model at: https://github.com/facebookresearch/audiobox-aesthetics
Molecular Graph Contrastive Learning with Line Graph
Jan 15, 2025Trapped by the label scarcity in molecular property prediction and drug design, graph contrastive learning (GCL) came forward. Leading contrastive learning works show two kinds of view generators, that is, random or learnable data corruption and domain knowledge incorporation. While effective, the two ways also lead to molecular semantics altering and limited generalization capability, respectively. To this end, we relate the \textbf{L}in\textbf{E} graph with \textbf{MO}lecular graph co\textbf{N}trastive learning and propose a novel method termed \textit{LEMON}. Specifically, by contrasting the given graph with the corresponding line graph, the graph encoder can freely encode the molecular semantics without omission. Furthermore, we present a new patch with edge attribute fusion and two local contrastive losses enhance information transmission and tackle hard negative samples. Compared with state-of-the-art (SOTA) methods for view generation, superior performance on molecular property prediction suggests the effectiveness of our proposed framework.
Audiobox TTA-RAG: Improving Zero-Shot and Few-Shot Text-To-Audio with Retrieval-Augmented Generation
Nov 07, 2024Current leading Text-To-Audio (TTA) generation models suffer from degraded performance on zero-shot and few-shot settings. It is often challenging to generate high-quality audio for audio events that are unseen or uncommon in the training set. Inspired by the success of Retrieval-Augmented Generation (RAG) in Large Language Model (LLM)-based knowledge-intensive tasks, we extend the TTA process with additional conditioning contexts. We propose Audiobox TTA-RAG, a novel retrieval-augmented TTA approach based on Audiobox, a conditional flow-matching audio generation model. Unlike the vanilla Audiobox TTA solution which generates audio conditioned on text, we augmented the conditioning input with retrieved audio samples that provide additional acoustic information to generate the target audio. Our retrieval method does not require the external database to have labeled audio, offering more practical use cases. To evaluate our proposed method, we curated test sets in zero-shot and few-shot settings. Our empirical results show that the proposed model can effectively leverage the retrieved audio samples and significantly improve zero-shot and few-shot TTA performance, with large margins on multiple evaluation metrics, while maintaining the ability to generate semantically aligned audio for the in-domain setting. In addition, we investigate the effect of different retrieval methods and data sources.
MDCure: A Scalable Pipeline for Multi-Document Instruction-Following
Oct 30, 2024


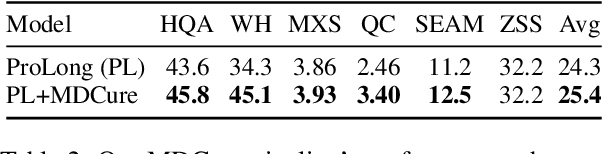
Multi-document (MD) processing is crucial for LLMs to handle real-world tasks such as summarization and question-answering across large sets of documents. While LLMs have improved at processing long inputs, MD contexts still present challenges, such as managing inter-document dependencies, redundancy, and incoherent structures. We introduce MDCure, a scalable and effective fine-tuning pipeline to enhance the MD capabilities of LLMs without the computational cost of pre-training or reliance on human annotated data. MDCure is based on generation of high-quality synthetic MD instruction data from sets of related articles via targeted prompts. We further introduce MDCureRM, a multi-objective reward model which filters generated data based on their training utility for MD settings. With MDCure, we fine-tune a variety of LLMs, from the FlanT5, Qwen2, and LLAMA3.1 model families, up to 70B parameters in size. Extensive evaluations on a wide range of MD and long-context benchmarks spanning various tasks show MDCure consistently improves performance over pre-trained baselines and over corresponding base models by up to 75.5%. Our code, datasets, and models are available at https://github.com/yale-nlp/MDCure.
MusicFlow: Cascaded Flow Matching for Text Guided Music Generation
Oct 27, 2024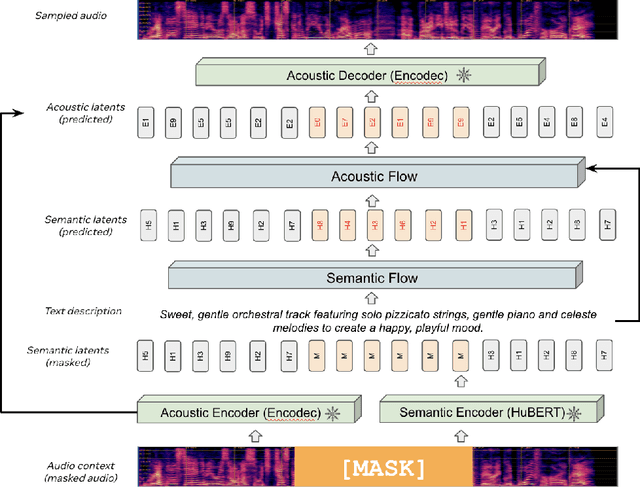
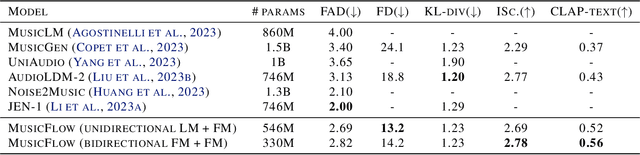
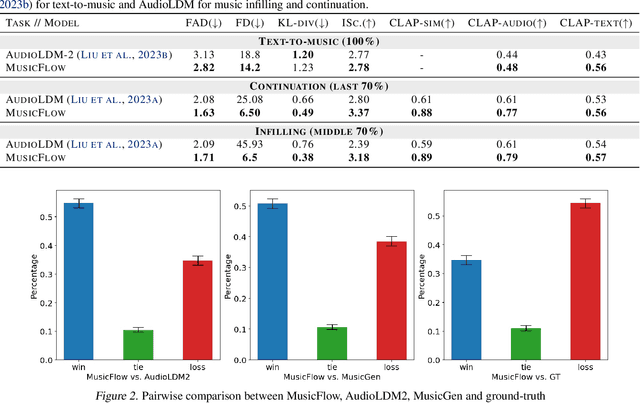
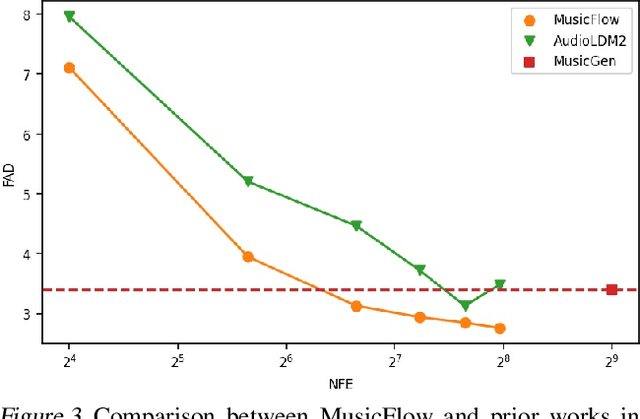
We introduce MusicFlow, a cascaded text-to-music generation model based on flow matching. Based on self-supervised representations to bridge between text descriptions and music audios, we construct two flow matching networks to model the conditional distribution of semantic and acoustic features. Additionally, we leverage masked prediction as the training objective, enabling the model to generalize to other tasks such as music infilling and continuation in a zero-shot manner. Experiments on MusicCaps reveal that the music generated by MusicFlow exhibits superior quality and text coherence despite being over $2\sim5$ times smaller and requiring $5$ times fewer iterative steps. Simultaneously, the model can perform other music generation tasks and achieves competitive performance in music infilling and continuation. Our code and model will be publicly available.