 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025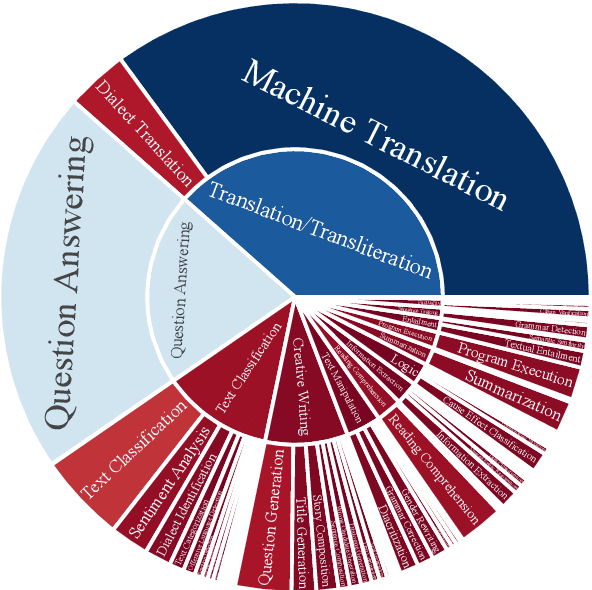



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
XLAVS-R: Cross-Lingual Audio-Visual Speech Representation Learning for Noise-Robust Speech Perception
Mar 21, 2024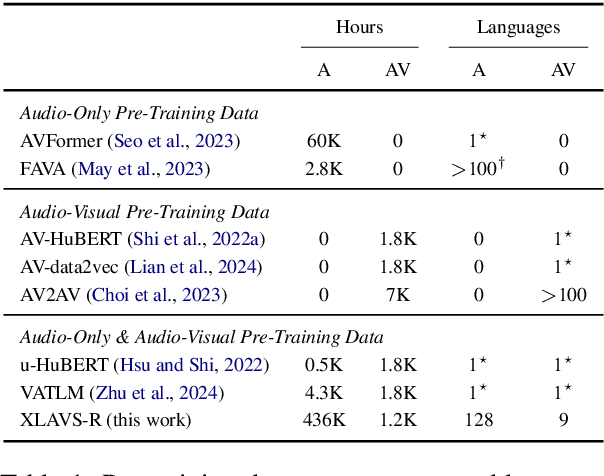
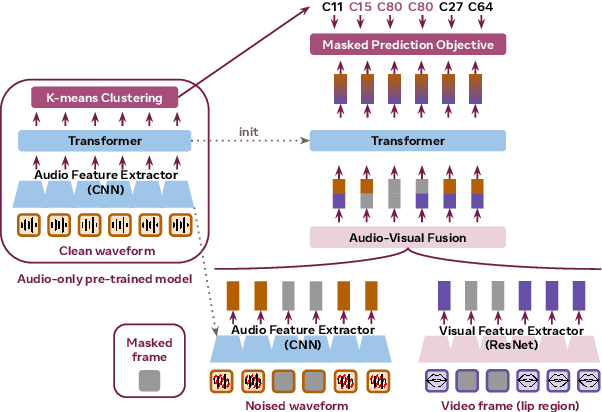
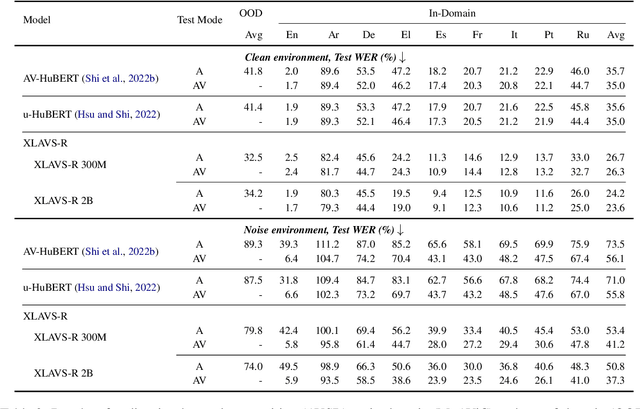
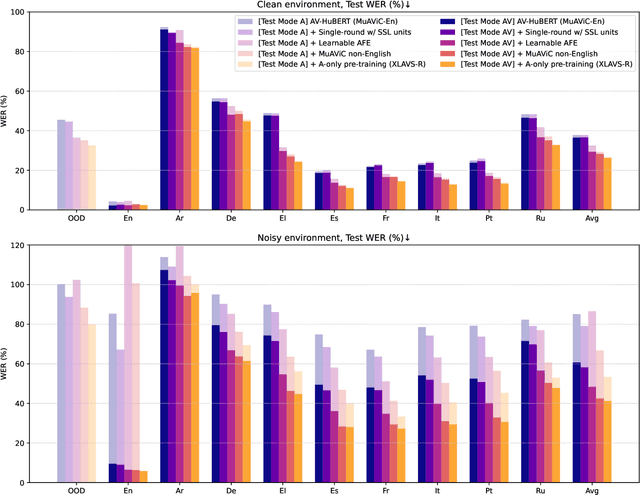
Speech recognition and translation systems perform poorly on noisy inputs, which are frequent in realistic environments. Augmenting these systems with visual signals has the potential to improve robustness to noise. However, audio-visual (AV) data is only available in limited amounts and for fewer languages than audio-only resources. To address this gap, we present XLAVS-R, a cross-lingual audio-visual speech representation model for noise-robust speech recognition and translation in over 100 languages. It is designed to maximize the benefits of limited multilingual AV pre-training data, by building on top of audio-only multilingual pre-training and simplifying existing pre-training schemes. Extensive evaluation on the MuAViC benchmark shows the strength of XLAVS-R on downstream audio-visual speech recognition and translation tasks, where it outperforms the previous state of the art by up to 18.5% WER and 4.7 BLEU given noisy AV inputs, and enables strong zero-shot audio-visual ability with audio-only fine-tuning.
The Effect of Alignment Objectives on Code-Switching Translation
Sep 10, 2023
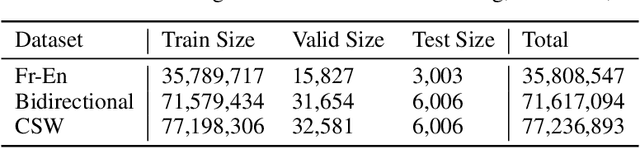

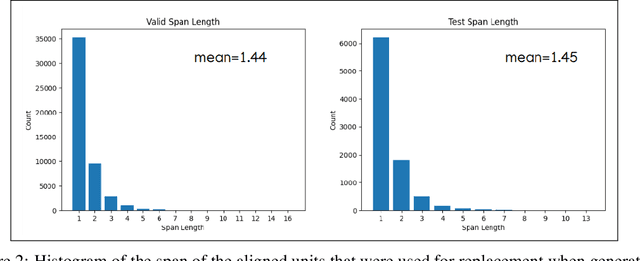
One of the things that need to change when it comes to machine translation is the models' ability to translate code-switching content, especially with the rise of social media and user-generated content. In this paper, we are proposing a way of training a single machine translation model that is able to translate monolingual sentences from one language to another, along with translating code-switched sentences to either language. This model can be considered a bilingual model in the human sense. For better use of parallel data, we generated synthetic code-switched (CSW) data along with an alignment loss on the encoder to align representations across languages. Using the WMT14 English-French (En-Fr) dataset, the trained model strongly outperforms bidirectional baselines on code-switched translation while maintaining quality for non-code-switched (monolingual) data.
MuAViC: A Multilingual Audio-Visual Corpus for Robust Speech Recognition and Robust Speech-to-Text Translation
Mar 07, 2023We introduce MuAViC, a multilingual audio-visual corpus for robust speech recognition and robust speech-to-text translation providing 1200 hours of audio-visual speech in 9 languages. It is fully transcribed and covers 6 English-to-X translation as well as 6 X-to-English translation directions. To the best of our knowledge, this is the first open benchmark for audio-visual speech-to-text translation and the largest open benchmark for multilingual audio-visual speech recognition. Our baseline results show that MuAViC is effective for building noise-robust speech recognition and translation models. We make the corpus available at https://github.com/facebookresearch/muavic.