 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM Audio Judge: A Unified Multimodal Framework for Perceptual Evaluation of Audio Separation
Jan 27, 2026The performance evaluation remains a complex challenge in audio separation, and existing evaluation metrics are often misaligned with human perception, course-grained, relying on ground truth signals. On the other hand, subjective listening tests remain the gold standard for real-world evaluation, but they are expensive, time-consuming, and difficult to scale. This paper addresses the growing need for automated systems capable of evaluating audio separation without human intervention. The proposed evaluation metric, SAM Audio Judge (SAJ), is a multimodal fine-grained reference-free objective metric, which shows highly alignment with human perceptions. SAJ supports three audio domains (speech, music and general sound events) and three prompt inputs (text, visual and span), covering four different dimensions of evaluation (recall, percision, faithfulness, and overall). SAM Audio Judge also shows potential applications in data filtering, pseudo-labeling large datasets and reranking in audio separation models. We release our code and pre-trained models at: https://github.com/facebookresearch/sam-audio.
Pushing the Frontier of Audiovisual Perception with Large-Scale Multimodal Correspondence Learning
Dec 22, 2025We introduce Perception Encoder Audiovisual, PE-AV, a new family of encoders for audio and video understanding trained with scaled contrastive learning. Built on PE, PE-AV makes several key contributions to extend representations to audio, and natively support joint embeddings across audio-video, audio-text, and video-text modalities. PE-AV's unified cross-modal embeddings enable novel tasks such as speech retrieval, and set a new state of the art across standard audio and video benchmarks. We unlock this by building a strong audiovisual data engine that synthesizes high-quality captions for O(100M) audio-video pairs, enabling large-scale supervision consistent across modalities. Our audio data includes speech, music, and general sound effects-avoiding single-domain limitations common in prior work. We exploit ten pairwise contrastive objectives, showing that scaling cross-modality and caption-type pairs strengthens alignment and improves zero-shot performance. We further develop PE-A-Frame by fine-tuning PE-AV with frame-level contrastive objectives, enabling fine-grained audio-frame-to-text alignment for tasks such as sound event detection.
SAM Audio: Segment Anything in Audio
Dec 19, 2025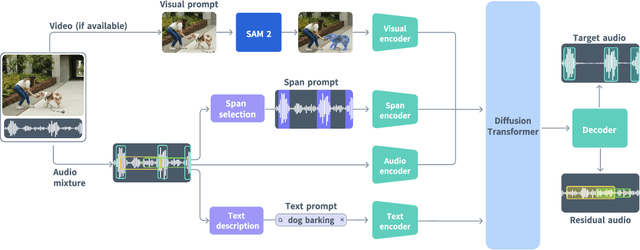

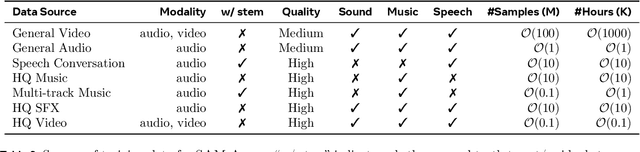
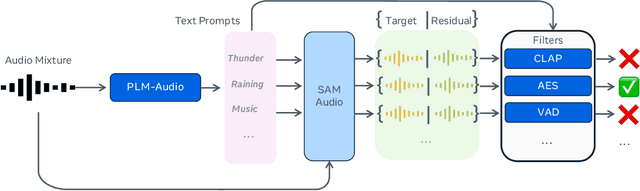
General audio source separation is a key capability for multimodal AI systems that can perceive and reason about sound. Despite substantial progress in recent years, existing separation models are either domain-specific, designed for fixed categories such as speech or music, or limited in controllability, supporting only a single prompting modality such as text. In this work, we present SAM Audio, a foundation model for general audio separation that unifies text, visual, and temporal span prompting within a single framework. Built on a diffusion transformer architecture, SAM Audio is trained with flow matching on large-scale audio data spanning speech, music, and general sounds, and can flexibly separate target sources described by language, visual masks, or temporal spans. The model achieves state-of-the-art performance across a diverse suite of benchmarks, including general sound, speech, music, and musical instrument separation in both in-the-wild and professionally produced audios, substantially outperforming prior general-purpose and specialized systems. Furthermore, we introduce a new real-world separation benchmark with human-labeled multimodal prompts and a reference-free evaluation model that correlates strongly with human judgment.
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Feb 07, 2025



The quantification of audio aesthetics remains a complex challenge in audio processing, primarily due to its subjective nature, which is influenced by human perception and cultural context. Traditional methods often depend on human listeners for evaluation, leading to inconsistencies and high resource demands. This paper addresses the growing need for automated systems capable of predicting audio aesthetics without human intervention. Such systems are crucial for applications like data filtering, pseudo-labeling large datasets, and evaluating generative audio models, especially as these models become more sophisticated. In this work, we introduce a novel approach to audio aesthetic evaluation by proposing new annotation guidelines that decompose human listening perspectives into four distinct axes. We develop and train no-reference, per-item prediction models that offer a more nuanced assessment of audio quality. Our models are evaluated against human mean opinion scores (MOS) and existing methods, demonstrating comparable or superior performance. This research not only advances the field of audio aesthetics but also provides open-source models and datasets to facilitate future work and benchmarking. We release our code and pre-trained model at: https://github.com/facebookresearch/audiobox-aesthetics
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Textless Acoustic Model with Self-Supervised Distillation for Noise-Robust Expressive Speech-to-Speech Translation
Jun 04, 2024In this paper, we propose a textless acoustic model with a self-supervised distillation strategy for noise-robust expressive speech-to-speech translation (S2ST). Recently proposed expressive S2ST systems have achieved impressive expressivity preservation performances by cascading unit-to-speech (U2S) generator to the speech-to-unit translation model. However, these systems are vulnerable to the presence of noise in input speech, which is an assumption in real-world translation scenarios. To address this limitation, we propose a U2S generator that incorporates a distillation with no label (DINO) self-supervised training strategy into it's pretraining process. Because the proposed method captures noise-agnostic expressivity representation, it can generate qualified speech even in noisy environment. Objective and subjective evaluation results verified that the proposed method significantly improved the performance of the expressive S2ST system in noisy environments while maintaining competitive performance in clean environments.
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
Multilingual Speech-to-Speech Translation into Multiple Target Languages
Jul 17, 2023

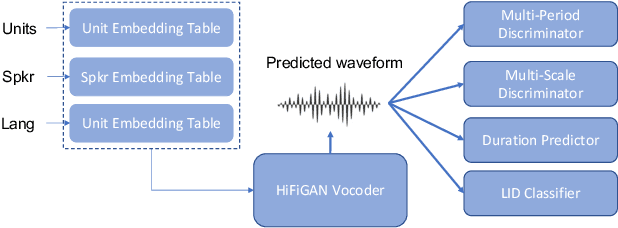

Speech-to-speech translation (S2ST) enables spoken communication between people talking in different languages. Despite a few studies on multilingual S2ST, their focus is the multilinguality on the source side, i.e., the translation from multiple source languages to one target language. We present the first work on multilingual S2ST supporting multiple target languages. Leveraging recent advance in direct S2ST with speech-to-unit and vocoder, we equip these key components with multilingual capability. Speech-to-masked-unit (S2MU) is the multilingual extension of S2U, which applies masking to units which don't belong to the given target language to reduce the language interference. We also propose multilingual vocoder which is trained with language embedding and the auxiliary loss of language identification. On benchmark translation testsets, our proposed multilingual model shows superior performance than bilingual models in the translation from English into $16$ target languages.
Enhancing Speech-to-Speech Translation with Multiple TTS Targets
Apr 10, 2023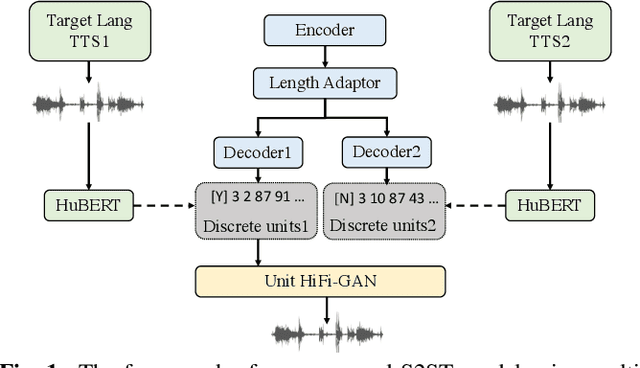



It has been known that direct speech-to-speech translation (S2ST) models usually suffer from the data scarcity issue because of the limited existing parallel materials for both source and target speech. Therefore to train a direct S2ST system, previous works usually utilize text-to-speech (TTS) systems to generate samples in the target language by augmenting the data from speech-to-text translation (S2TT). However, there is a limited investigation into how the synthesized target speech would affect the S2ST models. In this work, we analyze the effect of changing synthesized target speech for direct S2ST models. We find that simply combining the target speech from different TTS systems can potentially improve the S2ST performances. Following that, we also propose a multi-task framework that jointly optimizes the S2ST system with multiple targets from different TTS systems. Extensive experiments demonstrate that our proposed framework achieves consistent improvements (2.8 BLEU) over the baselines on the Fisher Spanish-English dataset.