 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-to-Speech Translation For A Real-world Unwritten Language
Paper and Code
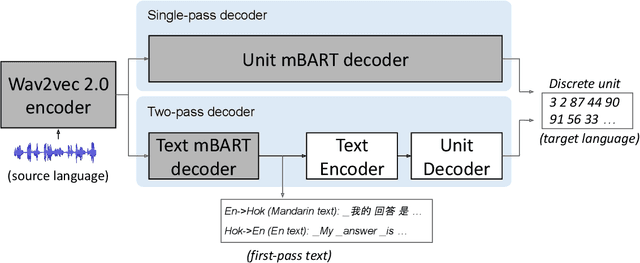
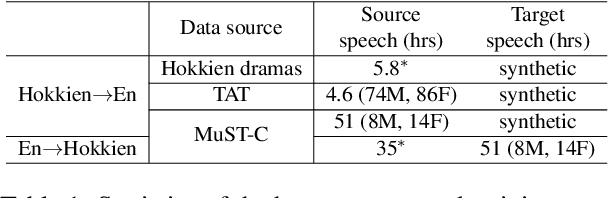
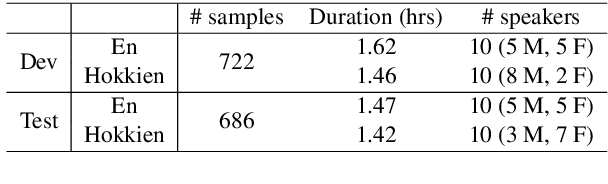
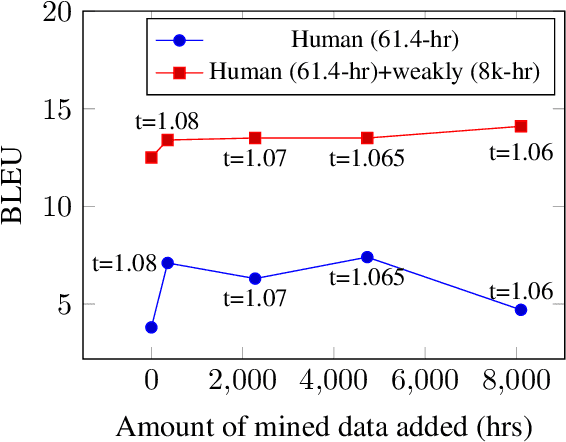
We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .