 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
A Holistic Cascade System, benchmark, and Human Evaluation Protocol for Expressive Speech-to-Speech Translation
Jan 25, 2023



Expressive speech-to-speech translation (S2ST) aims to transfer prosodic attributes of source speech to target speech while maintaining translation accuracy. Existing research in expressive S2ST is limited, typically focusing on a single expressivity aspect at a time. Likewise, this research area lacks standard evaluation protocols and well-curated benchmark datasets. In this work, we propose a holistic cascade system for expressive S2ST, combining multiple prosody transfer techniques previously considered only in isolation. We curate a benchmark expressivity test set in the TV series domain and explored a second dataset in the audiobook domain. Finally, we present a human evaluation protocol to assess multiple expressive dimensions across speech pairs. Experimental results indicate that bi-lingual annotators can assess the quality of expressive preservation in S2ST systems, and the holistic modeling approach outperforms single-aspect systems. Audio samples can be accessed through our demo webpage: https://facebookresearch.github.io/speech_translation/cascade_expressive_s2st.
BLASER: A Text-Free Speech-to-Speech Translation Evaluation Metric
Dec 16, 2022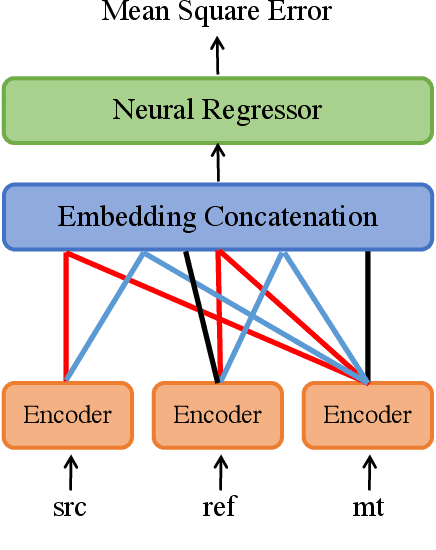
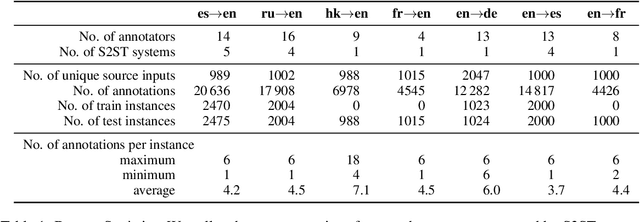
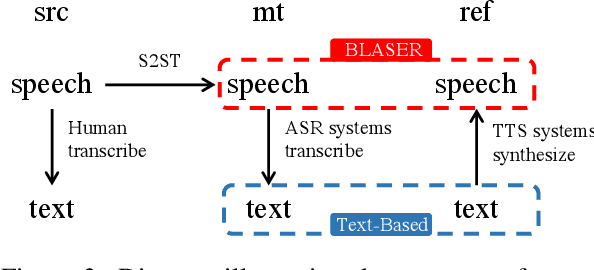

End-to-End speech-to-speech translation (S2ST) is generally evaluated with text-based metrics. This means that generated speech has to be automatically transcribed, making the evaluation dependent on the availability and quality of automatic speech recognition (ASR) systems. In this paper, we propose a text-free evaluation metric for end-to-end S2ST, named BLASER, to avoid the dependency on ASR systems. BLASER leverages a multilingual multimodal encoder to directly encode the speech segments for source input, translation output and reference into a shared embedding space and computes a score of the translation quality that can be used as a proxy to human evaluation. To evaluate our approach, we construct training and evaluation sets from more than 40k human annotations covering seven language directions. The best results of BLASER are achieved by training with supervision from human rating scores. We show that when evaluated at the sentence level, BLASER correlates significantly better with human judgment compared to ASR-dependent metrics including ASR-SENTBLEU in all translation directions and ASR-COMET in five of them. Our analysis shows combining speech and text as inputs to BLASER does not increase the correlation with human scores, but best correlations are achieved when using speech, which motivates the goal of our research. Moreover, we show that using ASR for references is detrimental for text-based metrics.
Speech-to-Speech Translation For A Real-world Unwritten Language
Nov 11, 2022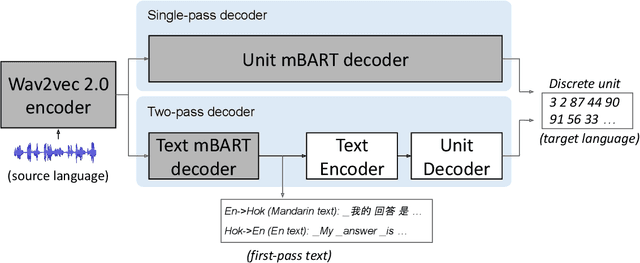
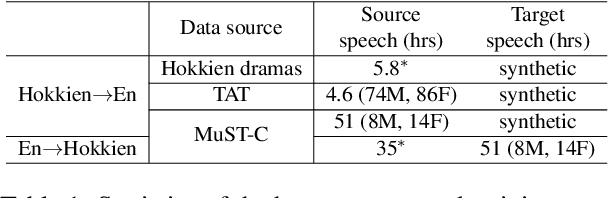
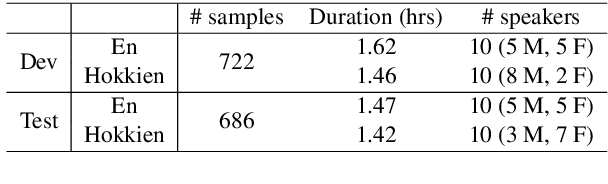
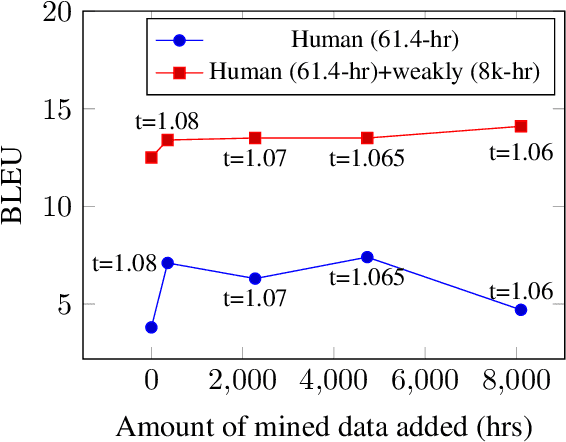
We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .
Noise-robust Named Entity Understanding for Virtual Assistants
May 29, 2020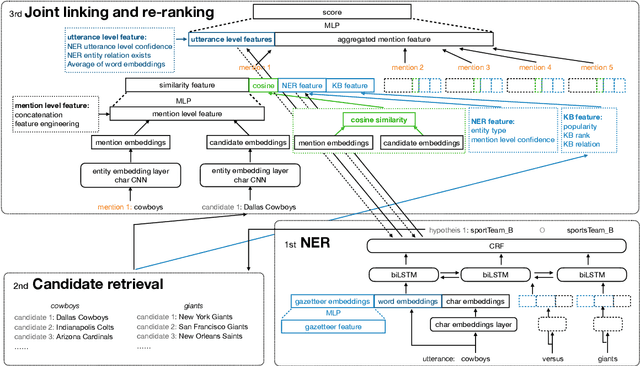
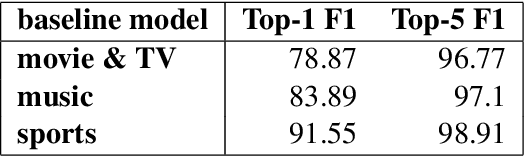
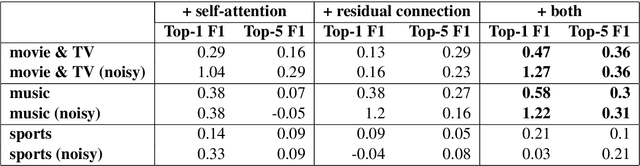
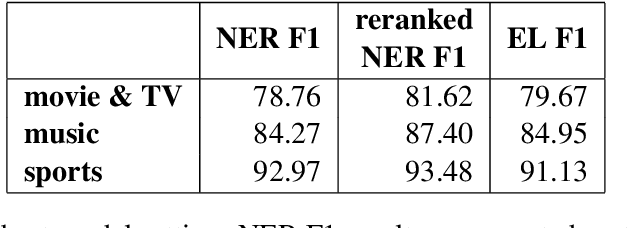
Named Entity Understanding (NEU) plays an essential role in interactions between users and voice assistants, since successfully identifying entities and correctly linking them to their standard forms is crucial to understanding the user's intent. NEU is a challenging task in voice assistants due to the ambiguous nature of natural language and because noise introduced by speech transcription and user errors occur frequently in spoken natural language queries. In this paper, we propose an architecture with novel features that jointly solves the recognition of named entities (a.k.a. Named Entity Recognition, or NER) and the resolution to their canonical forms (a.k.a. Entity Linking, or EL). We show that by combining NER and EL information in a joint reranking module, our proposed framework improves accuracy in both tasks. This improved performance and the features that enable it, also lead to better accuracy in downstream tasks, such as domain classification and semantic parsing.
Leveraging User Engagement Signals For Entity Labeling in a Virtual Assistant
Sep 18, 2019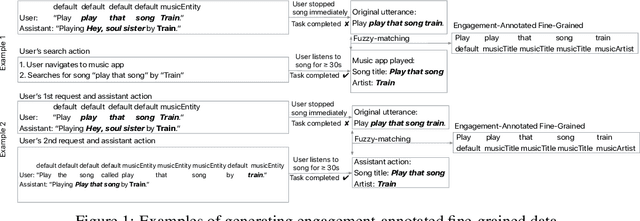
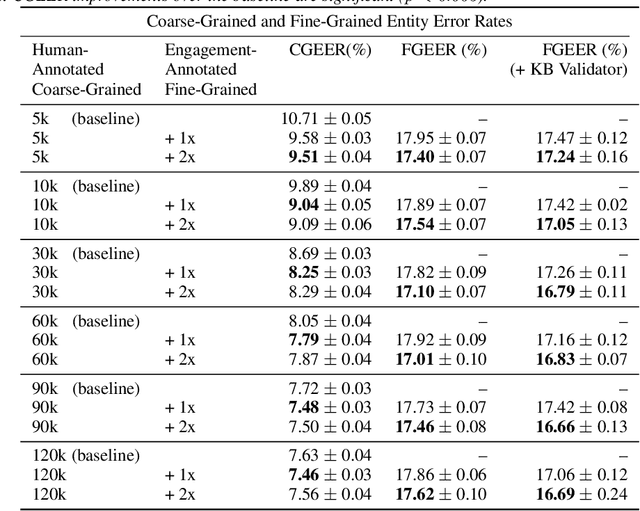
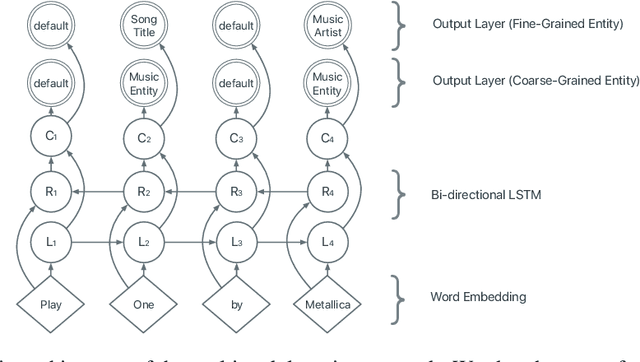
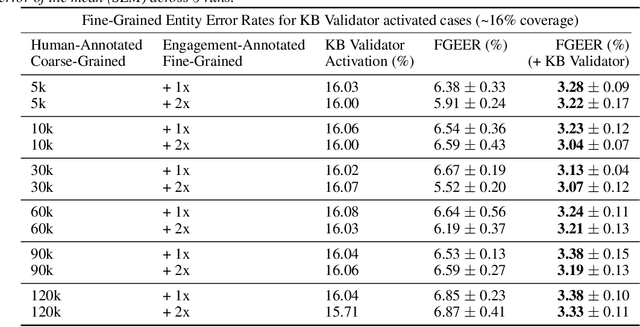
Personal assistant AI systems such as Siri, Cortana, and Alexa have become widely used as a means to accomplish tasks through natural language commands. However, components in these systems generally rely on supervised machine learning algorithms that require large amounts of hand-annotated training data, which is expensive and time consuming to collect. The ability to incorporate unsupervised, weakly supervised, or distantly supervised data holds significant promise in overcoming this bottleneck. In this paper, we describe a framework that leverages user engagement signals (user behaviors that demonstrate a positive or negative response to content) to automatically create granular entity labels for training data augmentation. Strategies such as multi-task learning and validation using an external knowledge base are employed to incorporate the engagement annotated data and to boost the model's accuracy on a sequence labeling task. Our results show that learning from data automatically labeled by user engagement signals achieves significant accuracy gains in a production deep learning system, when measured on both the sequence labeling task as well as on user facing results produced by the system end-to-end. We believe this is the first use of user engagement signals to help generate training data for a sequence labeling task on a large scale, and can be applied in practical settings to speed up new feature deployment when little human annotated data is available.