 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Content-Based and Meta-Data Analysis for Detecting Fake News Infodemic: A case study on COVID-19
Jan 16, 2024



The coronavirus pandemic (COVID-19) is probably the most disruptive global health disaster in recent history. It negatively impacted the whole world and virtually brought the global economy to a standstill. However, as the virus was spreading, infecting people and claiming thousands of lives so was the spread and propagation of fake news, misinformation and disinformation about the event. These included the spread of unconfirmed health advice and remedies on social media. In this paper, false information about the pandemic is identified using a content-based approach and metadata curated from messages posted to online social networks. A content-based approach combined with metadata as well as an initial feature analysis is used and then several supervised learning models are tested for identifying and predicting misleading posts. Our approach shows up to 93% accuracy in the detection of fake news related posts about the COVID-19 pandemic
* 8 pages, 5 figures, 3 tables, International Conference for Pattern Recognition Systems (ICPRS 2022)
Leveraging User Engagement Signals For Entity Labeling in a Virtual Assistant
Sep 18, 2019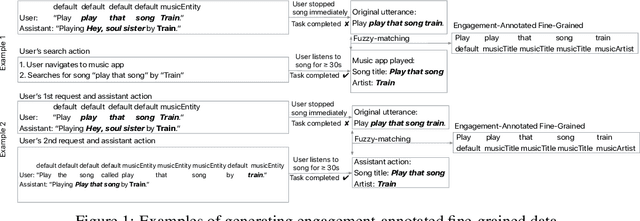
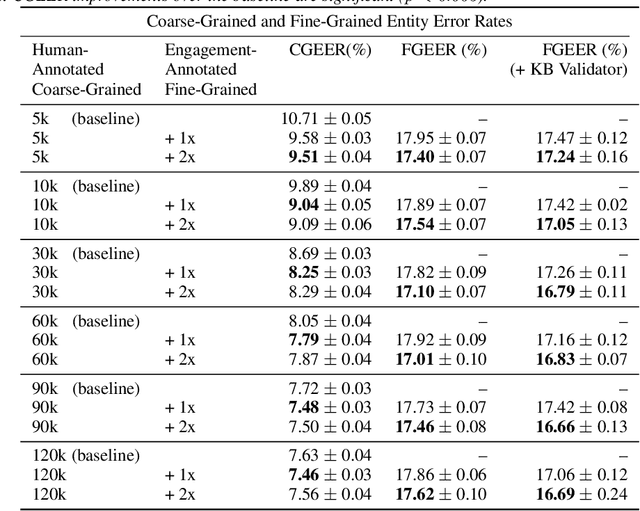
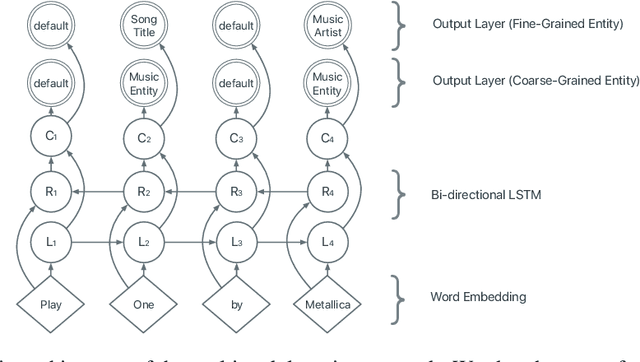
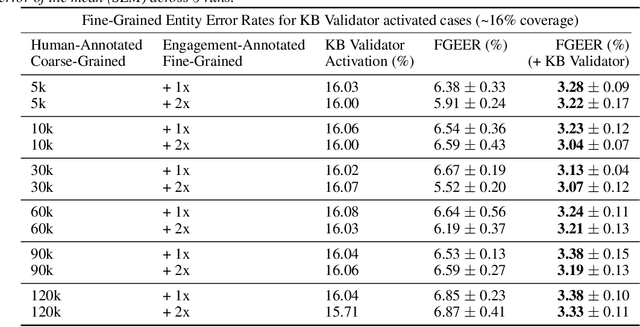
Personal assistant AI systems such as Siri, Cortana, and Alexa have become widely used as a means to accomplish tasks through natural language commands. However, components in these systems generally rely on supervised machine learning algorithms that require large amounts of hand-annotated training data, which is expensive and time consuming to collect. The ability to incorporate unsupervised, weakly supervised, or distantly supervised data holds significant promise in overcoming this bottleneck. In this paper, we describe a framework that leverages user engagement signals (user behaviors that demonstrate a positive or negative response to content) to automatically create granular entity labels for training data augmentation. Strategies such as multi-task learning and validation using an external knowledge base are employed to incorporate the engagement annotated data and to boost the model's accuracy on a sequence labeling task. Our results show that learning from data automatically labeled by user engagement signals achieves significant accuracy gains in a production deep learning system, when measured on both the sequence labeling task as well as on user facing results produced by the system end-to-end. We believe this is the first use of user engagement signals to help generate training data for a sequence labeling task on a large scale, and can be applied in practical settings to speed up new feature deployment when little human annotated data is available.
Active Learning for Domain Classification in a Commercial Spoken Personal Assistant
Aug 29, 2019
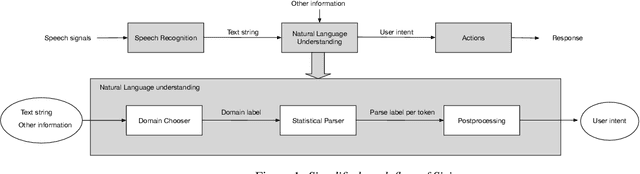
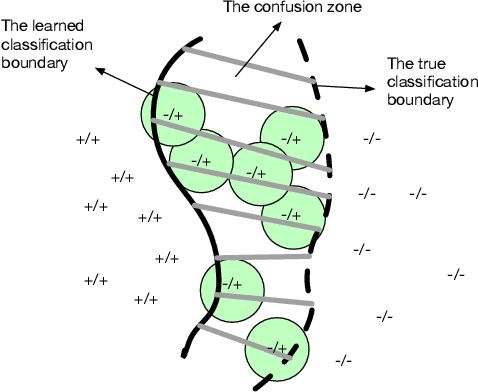
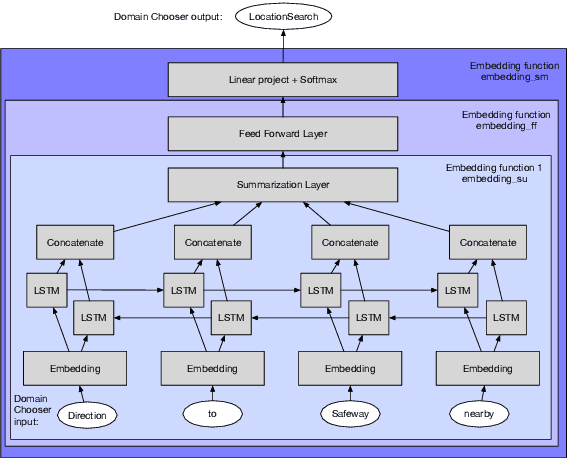
We describe a method for selecting relevant new training data for the LSTM-based domain selection component of our personal assistant system. Adding more annotated training data for any ML system typically improves accuracy, but only if it provides examples not already adequately covered in the existing data. However, obtaining, selecting, and labeling relevant data is expensive. This work presents a simple technique that automatically identifies new helpful examples suitable for human annotation. Our experimental results show that the proposed method, compared with random-selection and entropy-based methods, leads to higher accuracy improvements given a fixed annotation budget. Although developed and tested in the setting of a commercial intelligent assistant, the technique is of wider applicability.
Language Diversity across the Consonant Inventories: A Study in the Framework of Complex Networks
Apr 08, 2009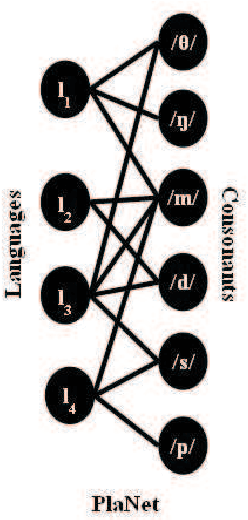

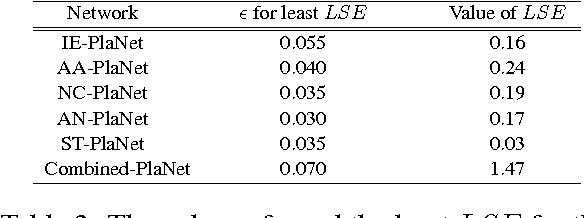
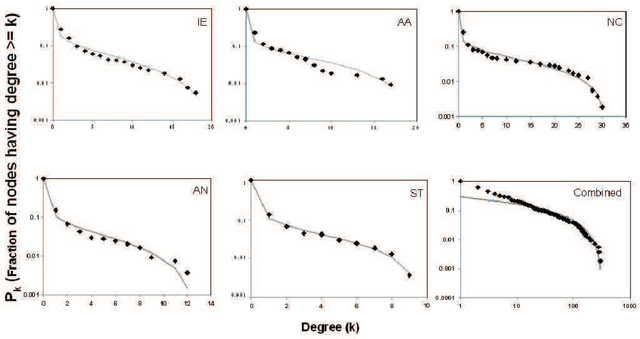
n this paper, we attempt to explain the emergence of the linguistic diversity that exists across the consonant inventories of some of the major language families of the world through a complex network based growth model. There is only a single parameter for this model that is meant to introduce a small amount of randomness in the otherwise preferential attachment based growth process. The experiments with this model parameter indicates that the choice of consonants among the languages within a family are far more preferential than it is across the families. The implications of this result are twofold -- (a) there is an innate preference of the speakers towards acquiring certain linguistic structures over others and (b) shared ancestry propels the stronger preferential connection between the languages within a family than across them. Furthermore, our observations indicate that this parameter might bear a correlation with the period of existence of the language families under investigation.