 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDELPHI: Data for Evaluating LLMs' Performance in Handling Controversial Issues
Nov 07, 2023



Controversy is a reflection of our zeitgeist, and an important aspect to any discourse. The rise of large language models (LLMs) as conversational systems has increased public reliance on these systems for answers to their various questions. Consequently, it is crucial to systematically examine how these models respond to questions that pertaining to ongoing debates. However, few such datasets exist in providing human-annotated labels reflecting the contemporary discussions. To foster research in this area, we propose a novel construction of a controversial questions dataset, expanding upon the publicly released Quora Question Pairs Dataset. This dataset presents challenges concerning knowledge recency, safety, fairness, and bias. We evaluate different LLMs using a subset of this dataset, illuminating how they handle controversial issues and the stances they adopt. This research ultimately contributes to our understanding of LLMs' interaction with controversial issues, paving the way for improvements in their comprehension and handling of complex societal debates.
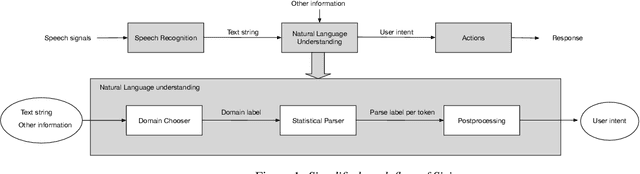
Intelligent Assistant Language Understanding On Device
Aug 07, 2023
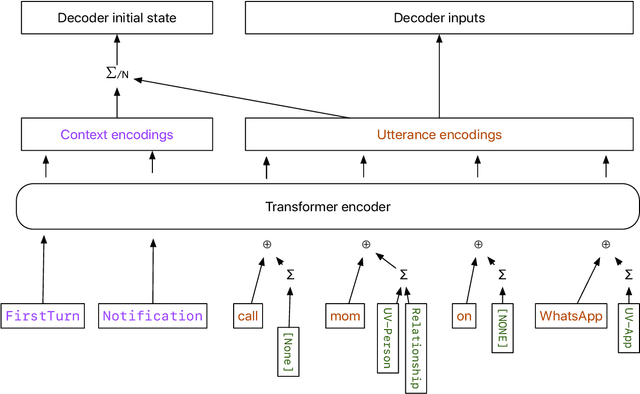

It has recently become feasible to run personal digital assistants on phones and other personal devices. In this paper we describe a design for a natural language understanding system that runs on device. In comparison to a server-based assistant, this system is more private, more reliable, faster, more expressive, and more accurate. We describe what led to key choices about architecture and technologies. For example, some approaches in the dialog systems literature are difficult to maintain over time in a deployment setting. We hope that sharing learnings from our practical experiences may help inform future work in the research community.
Feedback Effect in User Interaction with Intelligent Assistants: Delayed Engagement, Adaption and Drop-out
Mar 17, 2023With the growing popularity of intelligent assistants (IAs), evaluating IA quality becomes an increasingly active field of research. This paper identifies and quantifies the feedback effect, a novel component in IA-user interactions: how the capabilities and limitations of the IA influence user behavior over time. First, we demonstrate that unhelpful responses from the IA cause users to delay or reduce subsequent interactions in the short term via an observational study. Next, we expand the time horizon to examine behavior changes and show that as users discover the limitations of the IA's understanding and functional capabilities, they learn to adjust the scope and wording of their requests to increase the likelihood of receiving a helpful response from the IA. Our findings highlight the impact of the feedback effect at both the micro and meso levels. We further discuss its macro-level consequences: unsatisfactory interactions continuously reduce the likelihood and diversity of future user engagements in a feedback loop.
Improving Human-Labeled Data through Dynamic Automatic Conflict Resolution
Dec 08, 2020
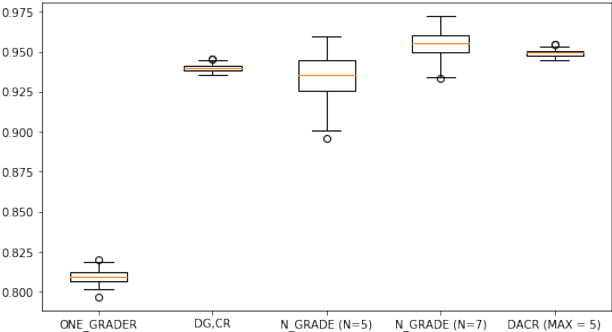

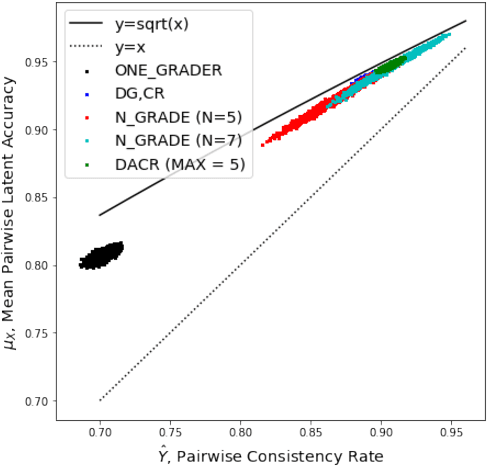
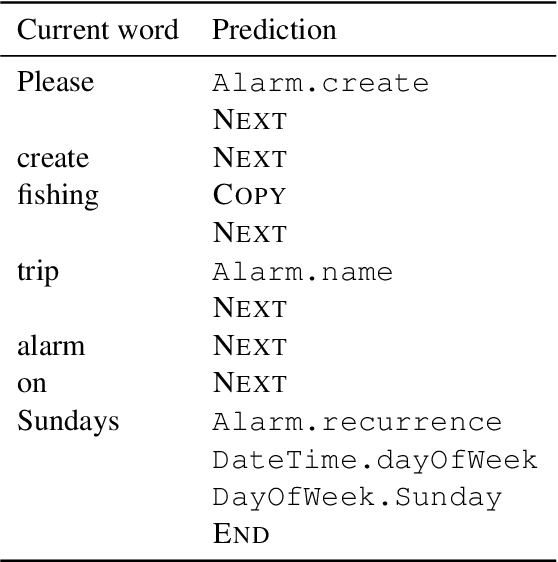
This paper develops and implements a scalable methodology for (a) estimating the noisiness of labels produced by a typical crowdsourcing semantic annotation task, and (b) reducing the resulting error of the labeling process by as much as 20-30% in comparison to other common labeling strategies. Importantly, this new approach to the labeling process, which we name Dynamic Automatic Conflict Resolution (DACR), does not require a ground truth dataset and is instead based on inter-project annotation inconsistencies. This makes DACR not only more accurate but also available to a broad range of labeling tasks. In what follows we present results from a text classification task performed at scale for a commercial personal assistant, and evaluate the inherent ambiguity uncovered by this annotation strategy as compared to other common labeling strategies.
Active Learning for Domain Classification in a Commercial Spoken Personal Assistant
Aug 29, 2019
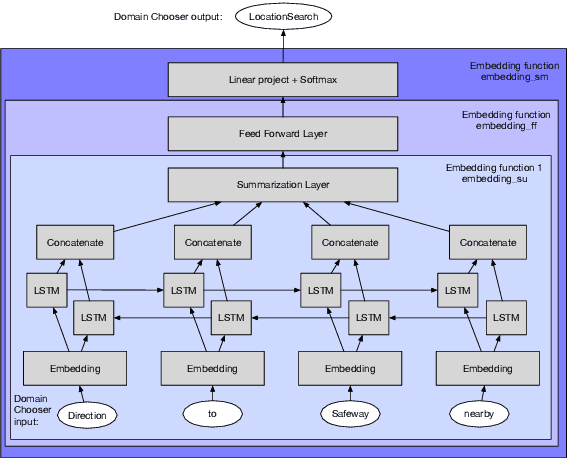
We describe a method for selecting relevant new training data for the LSTM-based domain selection component of our personal assistant system. Adding more annotated training data for any ML system typically improves accuracy, but only if it provides examples not already adequately covered in the existing data. However, obtaining, selecting, and labeling relevant data is expensive. This work presents a simple technique that automatically identifies new helpful examples suitable for human annotation. Our experimental results show that the proposed method, compared with random-selection and entropy-based methods, leads to higher accuracy improvements given a fixed annotation budget. Although developed and tested in the setting of a commercial intelligent assistant, the technique is of wider applicability.
NAIL: A General Interactive Fiction Agent
Feb 14, 2019

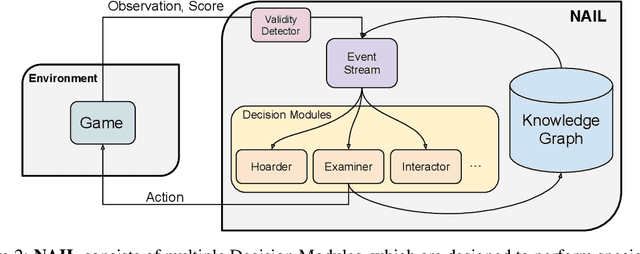
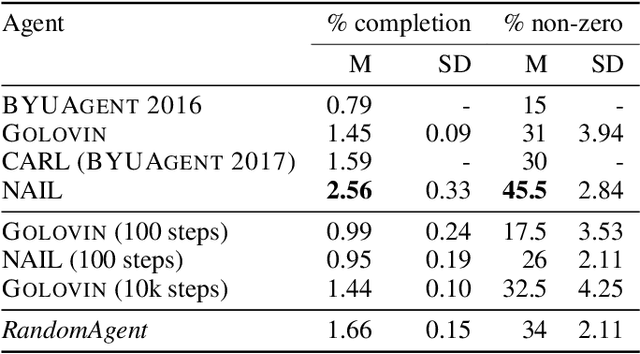
Interactive Fiction (IF) games are complex textual decision making problems. This paper introduces NAIL, an autonomous agent for general parser-based IF games. NAIL won the 2018 Text Adventure AI Competition, where it was evaluated on twenty unseen games. This paper describes the architecture, development, and insights underpinning NAIL's performance.
Learning to Globally Edit Images with Textual Description
Oct 13, 2018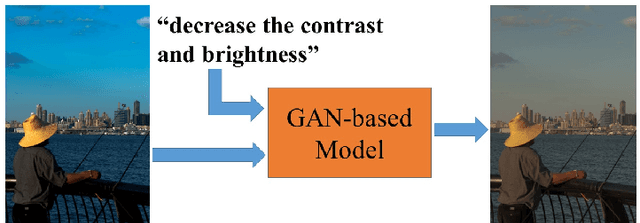


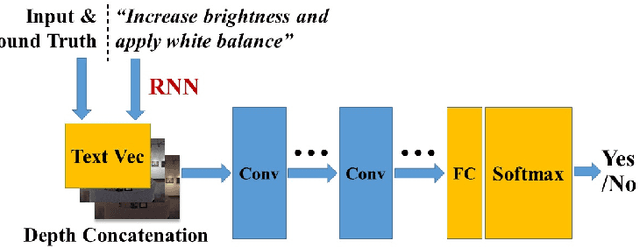
We show how we can globally edit images using textual instructions: given a source image and a textual instruction for the edit, generate a new image transformed under this instruction. To tackle this novel problem, we develop three different trainable models based on RNN and Generative Adversarial Network (GAN). The models (bucket, filter bank, and end-to-end) differ in how much expert knowledge is encoded, with the most general version being purely end-to-end. To train these systems, we use Amazon Mechanical Turk to collect textual descriptions for around 2000 image pairs sampled from several datasets. Experimental results evaluated on our dataset validate our approaches. In addition, given that the filter bank model is a good compromise between generality and performance, we investigate it further by replacing RNN with Graph RNN, and show that Graph RNN improves performance. To the best of our knowledge, this is the first computational photography work on global image editing that is purely based on free-form textual instructions.
Sample-efficient Deep Reinforcement Learning for Dialog Control
Dec 18, 2016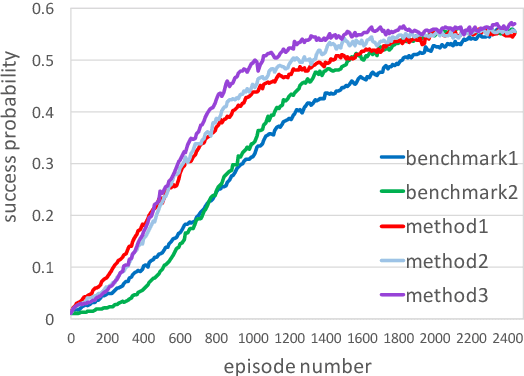
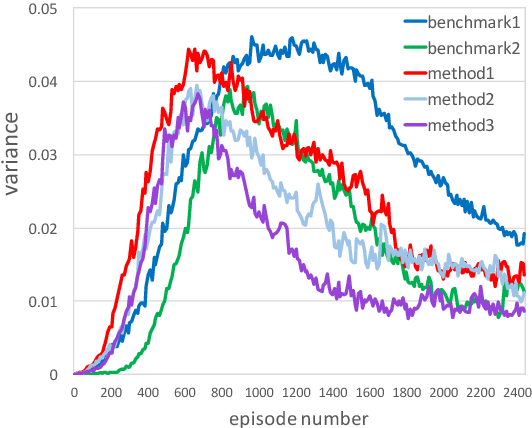
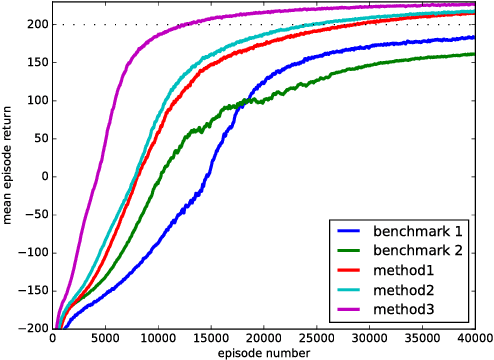
Representing a dialog policy as a recurrent neural network (RNN) is attractive because it handles partial observability, infers a latent representation of state, and can be optimized with supervised learning (SL) or reinforcement learning (RL). For RL, a policy gradient approach is natural, but is sample inefficient. In this paper, we present 3 methods for reducing the number of dialogs required to optimize an RNN-based dialog policy with RL. The key idea is to maintain a second RNN which predicts the value of the current policy, and to apply experience replay to both networks. On two tasks, these methods reduce the number of dialogs/episodes required by about a third, vs. standard policy gradient methods.
End-to-end LSTM-based dialog control optimized with supervised and reinforcement learning
Jun 03, 2016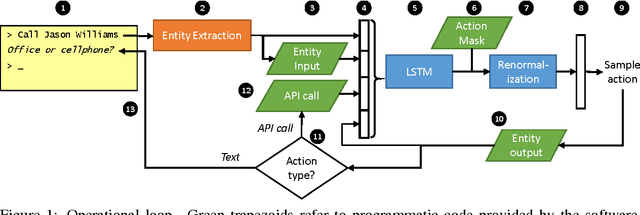
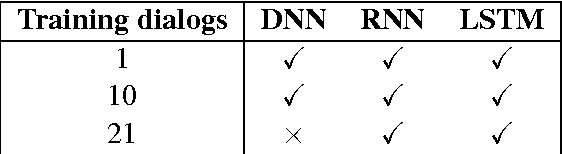

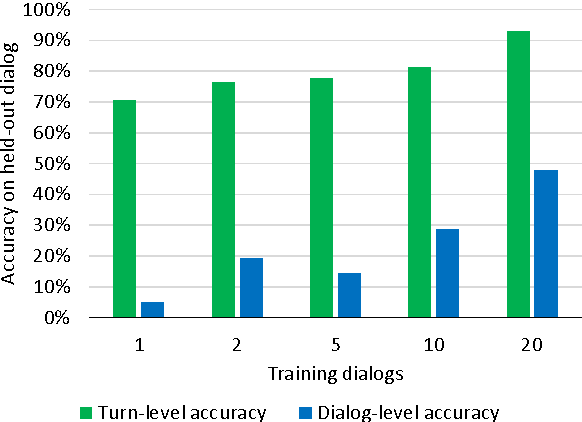
This paper presents a model for end-to-end learning of task-oriented dialog systems. The main component of the model is a recurrent neural network (an LSTM), which maps from raw dialog history directly to a distribution over system actions. The LSTM automatically infers a representation of dialog history, which relieves the system developer of much of the manual feature engineering of dialog state. In addition, the developer can provide software that expresses business rules and provides access to programmatic APIs, enabling the LSTM to take actions in the real world on behalf of the user. The LSTM can be optimized using supervised learning (SL), where a domain expert provides example dialogs which the LSTM should imitate; or using reinforcement learning (RL), where the system improves by interacting directly with end users. Experiments show that SL and RL are complementary: SL alone can derive a reasonable initial policy from a small number of training dialogs; and starting RL optimization with a policy trained with SL substantially accelerates the learning rate of RL.