 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Domain Classification in a Commercial Spoken Personal Assistant
Paper and Code
Aug 29, 2019
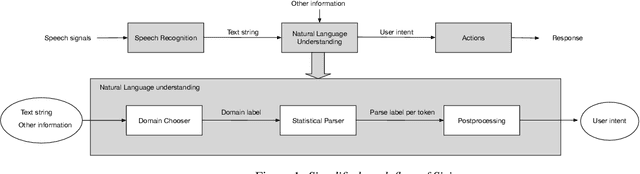
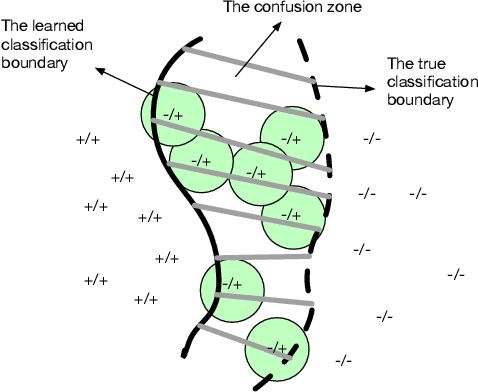
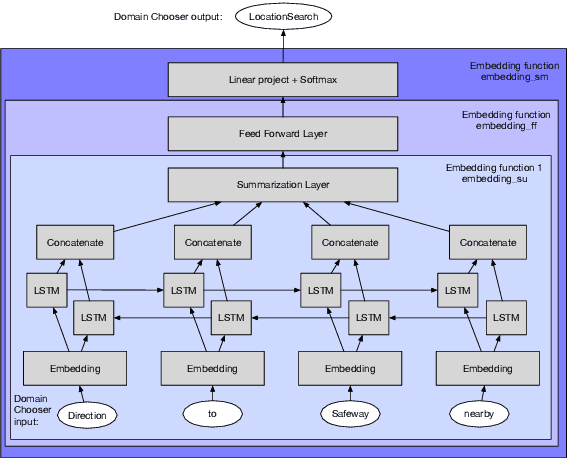
We describe a method for selecting relevant new training data for the LSTM-based domain selection component of our personal assistant system. Adding more annotated training data for any ML system typically improves accuracy, but only if it provides examples not already adequately covered in the existing data. However, obtaining, selecting, and labeling relevant data is expensive. This work presents a simple technique that automatically identifies new helpful examples suitable for human annotation. Our experimental results show that the proposed method, compared with random-selection and entropy-based methods, leads to higher accuracy improvements given a fixed annotation budget. Although developed and tested in the setting of a commercial intelligent assistant, the technique is of wider applicability.