 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Globally Edit Images with Textual Description
Oct 13, 2018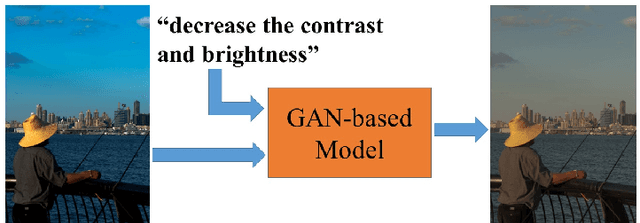


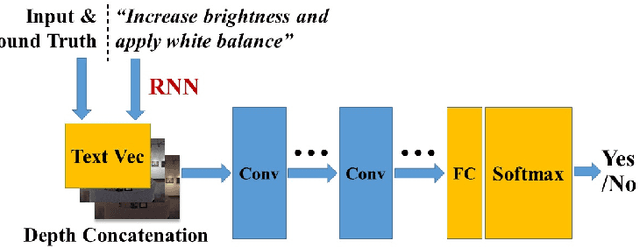
We show how we can globally edit images using textual instructions: given a source image and a textual instruction for the edit, generate a new image transformed under this instruction. To tackle this novel problem, we develop three different trainable models based on RNN and Generative Adversarial Network (GAN). The models (bucket, filter bank, and end-to-end) differ in how much expert knowledge is encoded, with the most general version being purely end-to-end. To train these systems, we use Amazon Mechanical Turk to collect textual descriptions for around 2000 image pairs sampled from several datasets. Experimental results evaluated on our dataset validate our approaches. In addition, given that the filter bank model is a good compromise between generality and performance, we investigate it further by replacing RNN with Graph RNN, and show that Graph RNN improves performance. To the best of our knowledge, this is the first computational photography work on global image editing that is purely based on free-form textual instructions.