 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Design Space of Tri-Modal Masked Diffusion Models
Feb 25, 2026Discrete diffusion models have emerged as strong alternatives to autoregressive language models, with recent work initializing and fine-tuning a base unimodal model for bimodal generation. Diverging from previous approaches, we introduce the first tri-modal masked diffusion model pretrained from scratch on text, image-text, and audio-text data. We systematically analyze multimodal scaling laws, modality mixing ratios, noise schedules, and batch-size effects, and we provide optimized inference sampling defaults. Our batch-size analysis yields a novel stochastic differential equation (SDE)-based reparameterization that eliminates the need for tuning the optimal batch size as reported in recent work. This reparameterization decouples the physical batch size, often chosen based on compute constraints (GPU saturation, FLOP efficiency, wall-clock time), from the logical batch size, chosen to balance gradient variance during stochastic optimization. Finally, we pretrain a preliminary 3B-parameter tri-modal model on 6.4T tokens, demonstrating the capabilities of a unified design and achieving strong results in text generation, text-to-image tasks, and text-to-speech tasks. Our work represents the largest-scale systematic open study of multimodal discrete diffusion models conducted to date, providing insights into scaling behaviors across multiple modalities.
M2R2: Mixture of Multi-Rate Residuals for Efficient Transformer Inference
Feb 04, 2025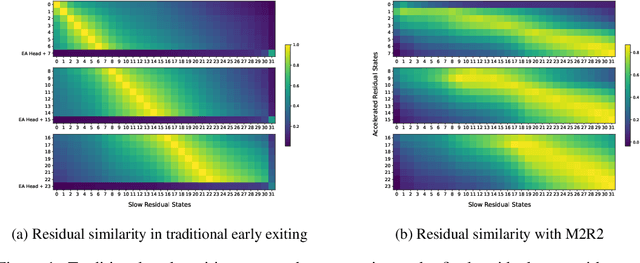
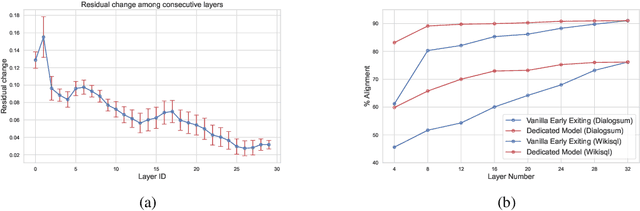
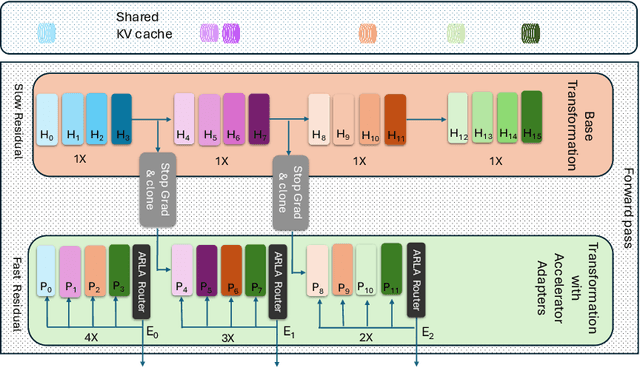
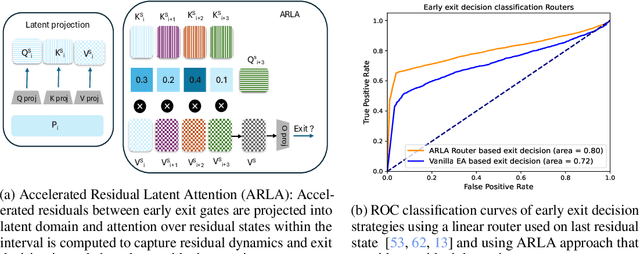
Residual transformations enhance the representational depth and expressive power of large language models (LLMs). However, applying static residual transformations across all tokens in auto-regressive generation leads to a suboptimal trade-off between inference efficiency and generation fidelity. Existing methods, including Early Exiting, Skip Decoding, and Mixture-of-Depth address this by modulating the residual transformation based on token-level complexity. Nevertheless, these approaches predominantly consider the distance traversed by tokens through the model layers, neglecting the underlying velocity of residual evolution. We introduce Mixture of Multi-rate Residuals (M2R2), a framework that dynamically modulates residual velocity to improve early alignment, enhancing inference efficiency. Evaluations on reasoning oriented tasks such as Koala, Self-Instruct, WizardLM, and MT-Bench show M2R2 surpasses state-of-the-art distance-based strategies, balancing generation quality and speedup. In self-speculative decoding setup, M2R2 achieves up to 2.8x speedups on MT-Bench, outperforming methods like 2-model speculative decoding, Medusa, LookAhead Decoding, and DEED. In Mixture-of-Experts (MoE) architectures, integrating early residual alignment with ahead-of-time expert loading into high-bandwidth memory (HBM) accelerates decoding, reduces expert-switching bottlenecks, and achieves a 2.9x speedup, making it highly effective in resource-constrained environments.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Speculative Streaming: Fast LLM Inference without Auxiliary Models
Feb 16, 2024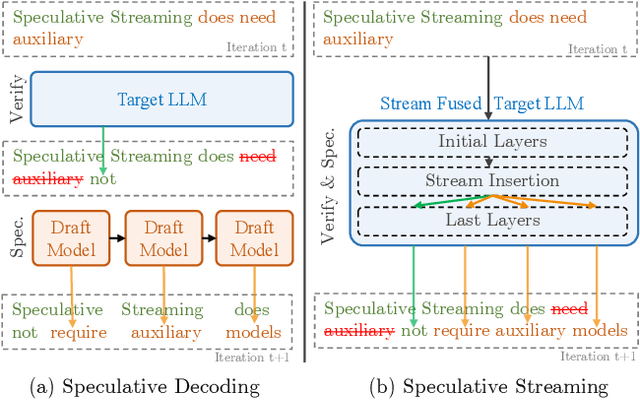
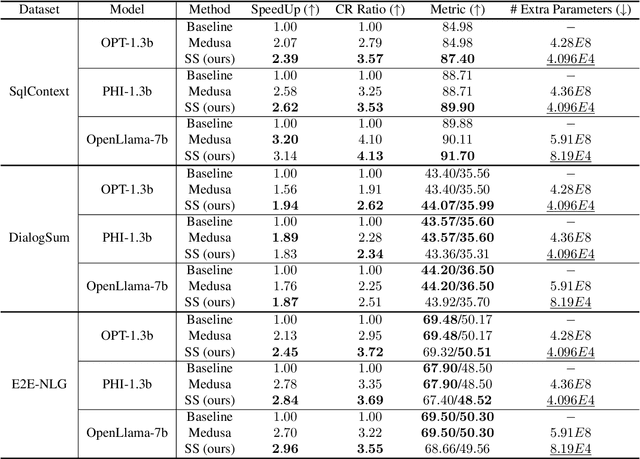
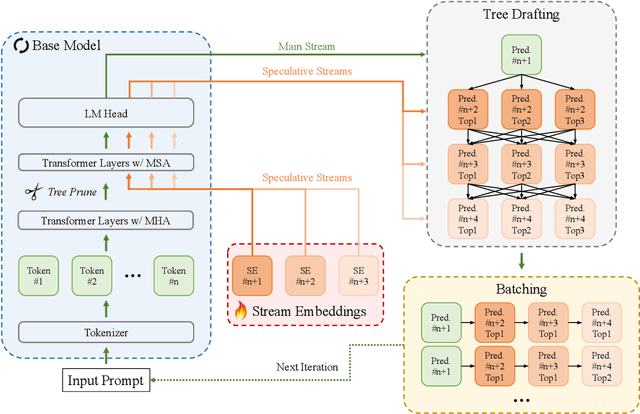
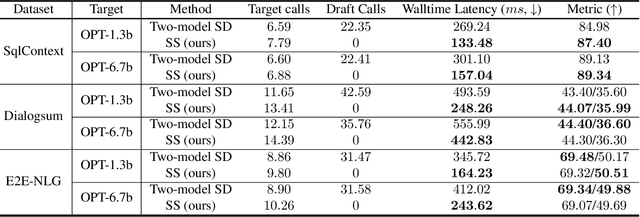
Speculative decoding is a prominent technique to speed up the inference of a large target language model based on predictions of an auxiliary draft model. While effective, in application-specific settings, it often involves fine-tuning both draft and target models to achieve high acceptance rates. As the number of downstream tasks grows, these draft models add significant complexity to inference systems. We propose Speculative Streaming, a single-model speculative decoding method that fuses drafting into the target model by changing the fine-tuning objective from next token prediction to future n-gram prediction. Speculative Streaming speeds up decoding by 1.8 - 3.1X in a diverse set of tasks, such as Summarization, Structured Queries, and Meaning Representation, without sacrificing generation quality. Additionally, Speculative Streaming is parameter-efficient. It achieves on-par/higher speed-ups than Medusa-style architectures while using ~10000X fewer extra parameters, making it well-suited for resource-constrained devices.
Intelligent Assistant Language Understanding On Device
Aug 07, 2023
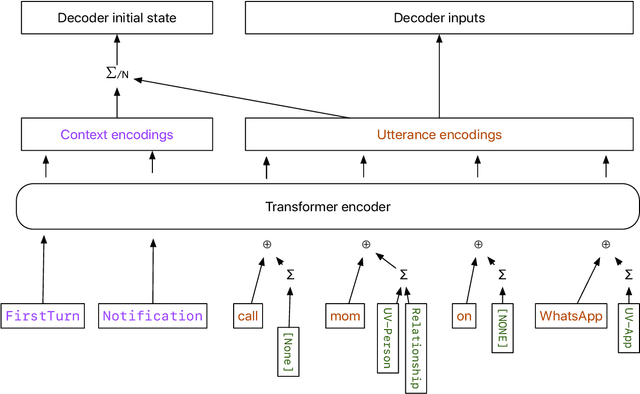
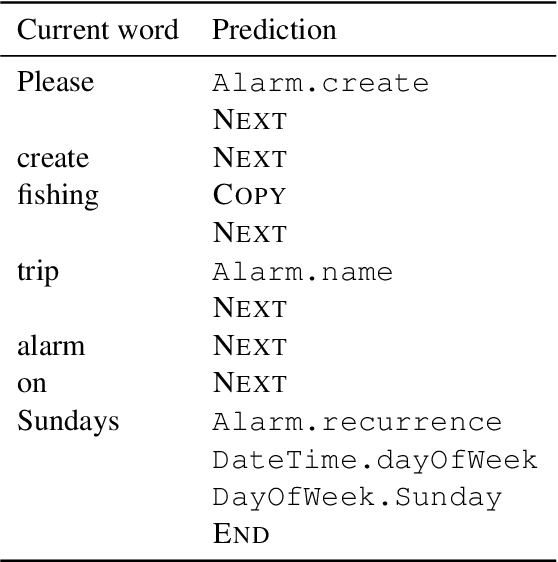

It has recently become feasible to run personal digital assistants on phones and other personal devices. In this paper we describe a design for a natural language understanding system that runs on device. In comparison to a server-based assistant, this system is more private, more reliable, faster, more expressive, and more accurate. We describe what led to key choices about architecture and technologies. For example, some approaches in the dialog systems literature are difficult to maintain over time in a deployment setting. We hope that sharing learnings from our practical experiences may help inform future work in the research community.