 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Then Embed: Generative Context Improves Multimodal Embedding
Oct 06, 2025There is a growing interest in Universal Multimodal Embeddings (UME), where models are required to generate task-specific representations. While recent studies show that Multimodal Large Language Models (MLLMs) perform well on such tasks, they treat MLLMs solely as encoders, overlooking their generative capacity. However, such an encoding paradigm becomes less effective as instructions become more complex and require compositional reasoning. Inspired by the proven effectiveness of chain-of-thought reasoning, we propose a general Think-Then-Embed (TTE) framework for UME, composed of a reasoner and an embedder. The reasoner MLLM first generates reasoning traces that explain complex queries, followed by an embedder that produces representations conditioned on both the original query and the intermediate reasoning. This explicit reasoning step enables more nuanced understanding of complex multimodal instructions. Our contributions are threefold. First, by leveraging a powerful MLLM reasoner, we achieve state-of-the-art performance on the MMEB-V2 benchmark, surpassing proprietary models trained on massive in-house datasets. Second, to reduce the dependency on large MLLM reasoners, we finetune a smaller MLLM reasoner using high-quality embedding-centric reasoning traces, achieving the best performance among open-source models with a 7% absolute gain over recently proposed models. Third, we investigate strategies for integrating the reasoner and embedder into a unified model for improved efficiency without sacrificing performance.
CAMPHOR: Collaborative Agents for Multi-input Planning and High-Order Reasoning On Device
Oct 12, 2024While server-side Large Language Models (LLMs) demonstrate proficiency in function calling and complex reasoning, deploying Small Language Models (SLMs) directly on devices brings opportunities to improve latency and privacy but also introduces unique challenges for accuracy and memory. We introduce CAMPHOR, an innovative on-device SLM multi-agent framework designed to handle multiple user inputs and reason over personal context locally, ensuring privacy is maintained. CAMPHOR employs a hierarchical architecture where a high-order reasoning agent decomposes complex tasks and coordinates expert agents responsible for personal context retrieval, tool interaction, and dynamic plan generation. By implementing parameter sharing across agents and leveraging prompt compression, we significantly reduce model size, latency, and memory usage. To validate our approach, we present a novel dataset capturing multi-agent task trajectories centered on personalized mobile assistant use-cases. Our experiments reveal that fine-tuned SLM agents not only surpass closed-source LLMs in task completion F1 by~35\% but also eliminate the need for server-device communication, all while enhancing privacy.
UI-JEPA: Towards Active Perception of User Intent through Onscreen User Activity
Sep 06, 2024
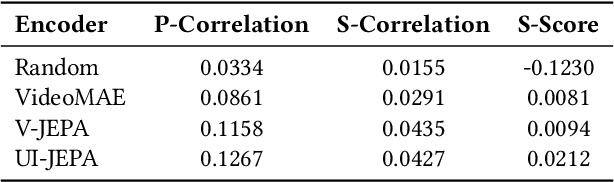


Generating user intent from a sequence of user interface (UI) actions is a core challenge in comprehensive UI understanding. Recent advancements in multimodal large language models (MLLMs) have led to substantial progress in this area, but their demands for extensive model parameters, computing power, and high latency makes them impractical for scenarios requiring lightweight, on-device solutions with low latency or heightened privacy. Additionally, the lack of high-quality datasets has hindered the development of such lightweight models. To address these challenges, we propose UI-JEPA, a novel framework that employs masking strategies to learn abstract UI embeddings from unlabeled data through self-supervised learning, combined with an LLM decoder fine-tuned for user intent prediction. We also introduce two new UI-grounded multimodal datasets, "Intent in the Wild" (IIW) and "Intent in the Tame" (IIT), designed for few-shot and zero-shot UI understanding tasks. IIW consists of 1.7K videos across 219 intent categories, while IIT contains 914 videos across 10 categories. We establish the first baselines for these datasets, showing that representations learned using a JEPA-style objective, combined with an LLM decoder, can achieve user intent predictions that match the performance of state-of-the-art large MLLMs, but with significantly reduced annotation and deployment resources. Measured by intent similarity scores, UI-JEPA outperforms GPT-4 Turbo and Claude 3.5 Sonnet by 10.0% and 7.2% respectively, averaged across two datasets. Notably, UI-JEPA accomplishes the performance with a 50.5x reduction in computational cost and a 6.6x improvement in latency in the IIW dataset. These results underscore the effectiveness of UI-JEPA, highlighting its potential for lightweight, high-performance UI understanding.
LUCID: LLM-Generated Utterances for Complex and Interesting Dialogues
Mar 01, 2024Virtual assistants are poised to take a dramatic leap forward in terms of their dialogue capabilities, spurred by recent advances in transformer-based Large Language Models (LLMs). Yet a major bottleneck to achieving genuinely transformative task-oriented dialogue capabilities remains the scarcity of high quality and linguistically sophisticated data. Existing datasets, while impressive in scale, have limited domain coverage and contain few genuinely challenging conversational phenomena; those which are present are typically unlabelled, making it difficult to assess the strengths and weaknesses of models without time-consuming and costly human evaluation. Moreover, creating high quality dialogue data has until now required considerable human input, limiting both the scale of these datasets and the ability to rapidly bootstrap data for a new target domain. We aim to overcome these issues with LUCID, a modularised and highly automated LLM-driven data generation system that produces realistic, diverse and challenging dialogues. We use LUCID to generate a seed dataset of 4,277 multi-domain, multi-intent conversations across 100 intents to demonstrate its capabilities. The generated conversations include a wide range of challenging phenomena and diverse user behaviour, conveniently identifiable via a set of turn-level tags. Finally, we provide separate test sets for seen and unseen intents, allowing for convenient out-of-distribution evaluation. We release both the data generation code and the dataset itself.
Effective and Efficient Conversation Retrieval for Dialogue State Tracking with Implicit Text Summaries
Feb 21, 2024Few-shot dialogue state tracking (DST) with Large Language Models (LLM) relies on an effective and efficient conversation retriever to find similar in-context examples for prompt learning. Previous works use raw dialogue context as search keys and queries, and a retriever is fine-tuned with annotated dialogues to achieve superior performance. However, the approach is less suited for scaling to new domains or new annotation languages, where fine-tuning data is unavailable. To address this problem, we handle the task of conversation retrieval based on text summaries of the conversations. A LLM-based conversation summarizer is adopted for query and key generation, which enables effective maximum inner product search. To avoid the extra inference cost brought by LLM-based conversation summarization, we further distill a light-weight conversation encoder which produces query embeddings without decoding summaries for test conversations. We validate our retrieval approach on MultiWOZ datasets with GPT-Neo-2.7B and LLaMA-7B/30B. The experimental results show a significant improvement over relevant baselines in real few-shot DST settings.
Intelligent Assistant Language Understanding On Device
Aug 07, 2023
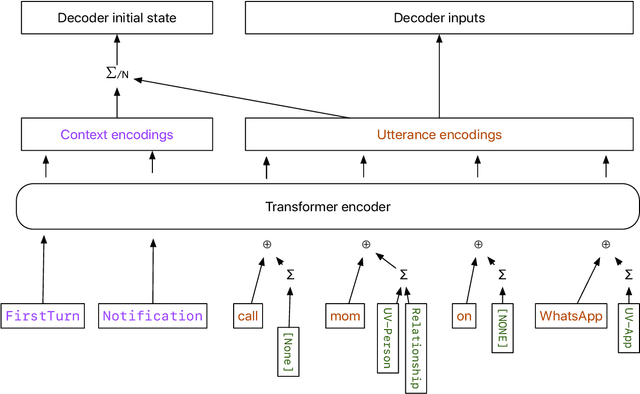
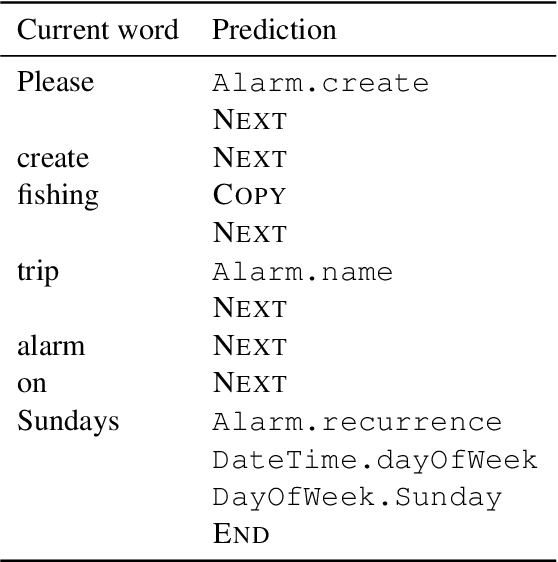

It has recently become feasible to run personal digital assistants on phones and other personal devices. In this paper we describe a design for a natural language understanding system that runs on device. In comparison to a server-based assistant, this system is more private, more reliable, faster, more expressive, and more accurate. We describe what led to key choices about architecture and technologies. For example, some approaches in the dialog systems literature are difficult to maintain over time in a deployment setting. We hope that sharing learnings from our practical experiences may help inform future work in the research community.
Conversational Semantic Parsing for Dialog State Tracking
Oct 24, 2020
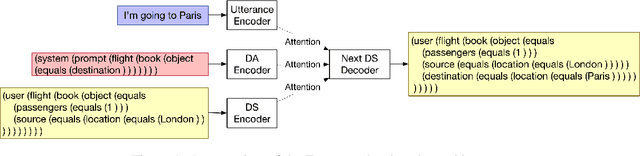

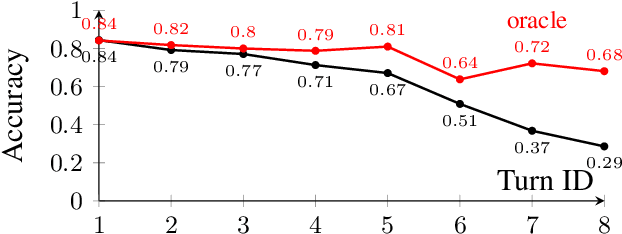
We consider a new perspective on dialog state tracking (DST), the task of estimating a user's goal through the course of a dialog. By formulating DST as a semantic parsing task over hierarchical representations, we can incorporate semantic compositionality, cross-domain knowledge sharing and co-reference. We present TreeDST, a dataset of 27k conversations annotated with tree-structured dialog states and system acts. We describe an encoder-decoder framework for DST with hierarchical representations, which leads to 20% improvement over state-of-the-art DST approaches that operate on a flat meaning space of slot-value pairs.
A Generative Model for Joint Natural Language Understanding and Generation
Jun 12, 2020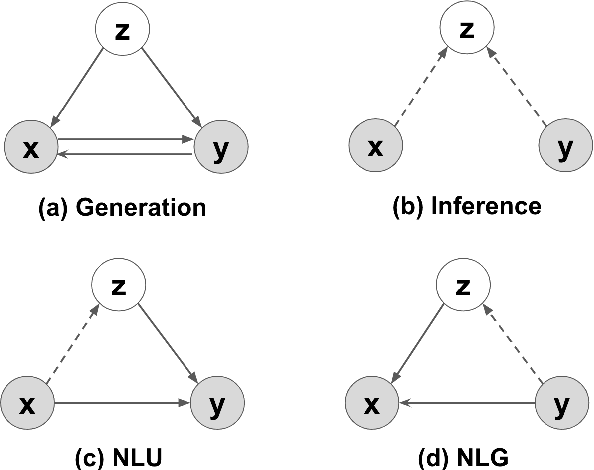


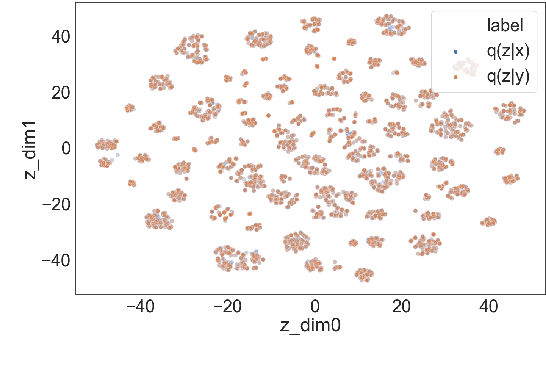
Natural language understanding (NLU) and natural language generation (NLG) are two fundamental and related tasks in building task-oriented dialogue systems with opposite objectives: NLU tackles the transformation from natural language to formal representations, whereas NLG does the reverse. A key to success in either task is parallel training data which is expensive to obtain at a large scale. In this work, we propose a generative model which couples NLU and NLG through a shared latent variable. This approach allows us to explore both spaces of natural language and formal representations, and facilitates information sharing through the latent space to eventually benefit NLU and NLG. Our model achieves state-of-the-art performance on two dialogue datasets with both flat and tree-structured formal representations. We also show that the model can be trained in a semi-supervised fashion by utilising unlabelled data to boost its performance.
Building a Neural Semantic Parser from a Domain Ontology
Dec 25, 2018



Semantic parsing is the task of converting natural language utterances into machine interpretable meaning representations which can be executed against a real-world environment such as a database. Scaling semantic parsing to arbitrary domains faces two interrelated challenges: obtaining broad coverage training data effectively and cheaply; and developing a model that generalizes to compositional utterances and complex intentions. We address these challenges with a framework which allows to elicit training data from a domain ontology and bootstrap a neural parser which recursively builds derivations of logical forms. In our framework meaning representations are described by sequences of natural language templates, where each template corresponds to a decomposed fragment of the underlying meaning representation. Although artificial, templates can be understood and paraphrased by humans to create natural utterances, resulting in parallel triples of utterances, meaning representations, and their decompositions. These allow us to train a neural semantic parser which learns to compose rules in deriving meaning representations. We crowdsource training data on six domains, covering both single-turn utterances which exhibit rich compositionality, and sequential utterances where a complex task is procedurally performed in steps. We then develop neural semantic parsers which perform such compositional tasks. In general, our approach allows to deploy neural semantic parsers quickly and cheaply from a given domain ontology.
Dependency Grammar Induction with a Neural Variational Transition-based Parser
Nov 14, 2018



Dependency grammar induction is the task of learning dependency syntax without annotated training data. Traditional graph-based models with global inference achieve state-of-the-art results on this task but they require $O(n^3)$ run time. Transition-based models enable faster inference with $O(n)$ time complexity, but their performance still lags behind. In this work, we propose a neural transition-based parser for dependency grammar induction, whose inference procedure utilizes rich neural features with $O(n)$ time complexity. We train the parser with an integration of variational inference, posterior regularization and variance reduction techniques. The resulting framework outperforms previous unsupervised transition-based dependency parsers and achieves performance comparable to graph-based models, both on the English Penn Treebank and on the Universal Dependency Treebank. In an empirical comparison, we show that our approach substantially increases parsing speed over graph-based models.