 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOAD: Task-Oriented Automatic Dialogs with Diverse Response Styles
Feb 16, 2024In light of recent advances in large language models (LLMs), the expectations for the next generation of virtual assistants include enhanced naturalness and adaptability across diverse usage scenarios. However, the creation of high-quality annotated data for Task-Oriented Dialog (TOD) is recognized to be slow and costly. To address these challenges, we introduce Task-Oriented Automatic Dialogs (TOAD), a novel and scalable TOD dataset along with its automatic generation pipeline. The TOAD dataset simulates realistic app context interaction and provide a variety of system response style options. Two aspects of system response styles are considered, verbosity level and users' expression mirroring. We benchmark TOAD on two response generation tasks and the results show that modelling more verbose or responses without user expression mirroring is more challenging.
Prompting for a conversation: How to control a dialog model?
Sep 22, 2022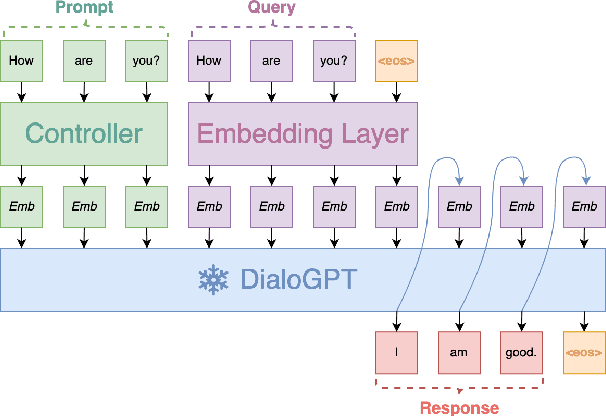
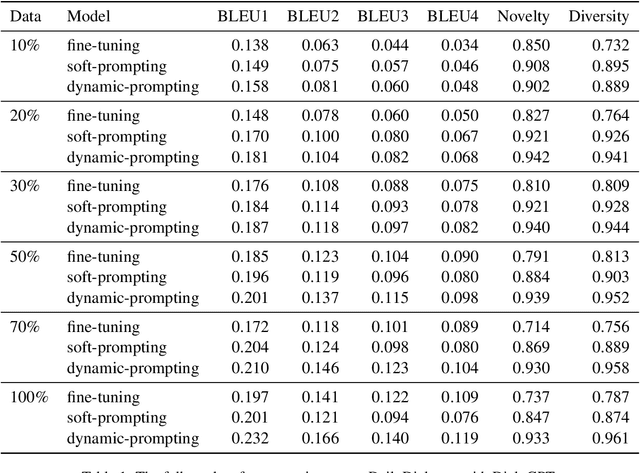
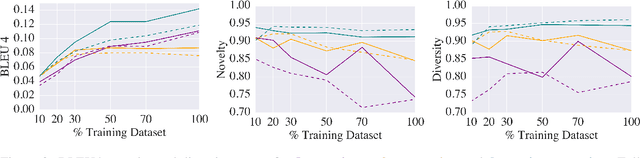
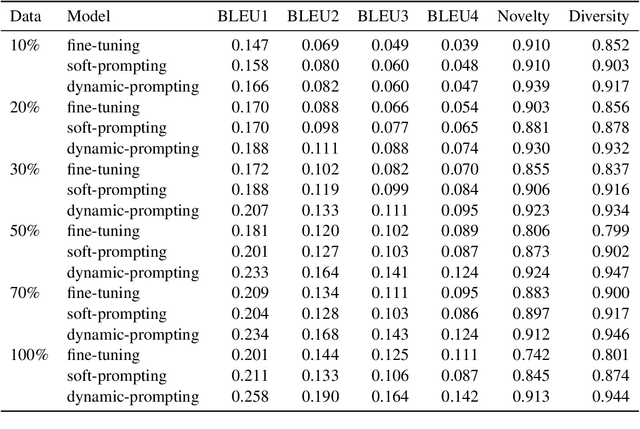
Dialog modelling faces a difficult trade-off. Models are trained on a large amount of text, yet their responses need to be limited to a desired scope and style of a dialog agent. Because the datasets used to achieve the former contain language that is not compatible with the latter, pre-trained dialog models are fine-tuned on smaller curated datasets. However, the fine-tuning process robs them of the ability to produce diverse responses, eventually reducing them to dull conversation partners. In this paper we investigate if prompting can mitigate the above trade-off. Specifically, we experiment with conditioning the prompt on the query, rather than training a single prompt for all queries. By following the intuition that freezing the pre-trained language model will conserve its expressivity, we find that compared to fine-tuning, prompting can achieve a higher BLEU score and substantially improve the diversity and novelty of the responses.
Plan-then-Generate: Controlled Data-to-Text Generation via Planning
Aug 31, 2021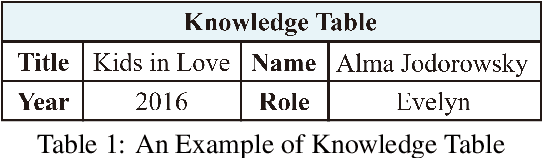
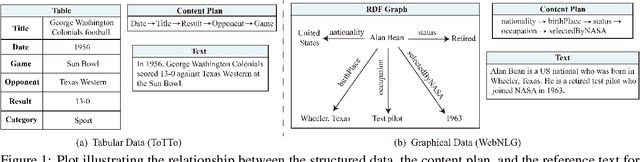
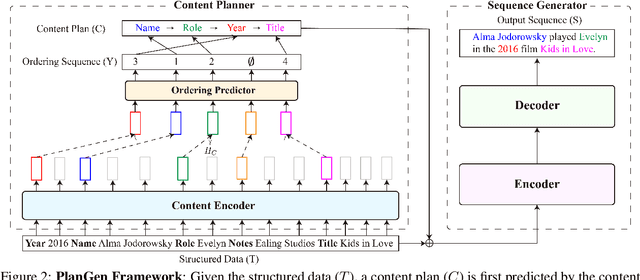
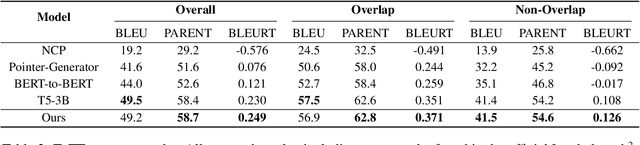
Recent developments in neural networks have led to the advance in data-to-text generation. However, the lack of ability of neural models to control the structure of generated output can be limiting in certain real-world applications. In this study, we propose a novel Plan-then-Generate (PlanGen) framework to improve the controllability of neural data-to-text models. Extensive experiments and analyses are conducted on two benchmark datasets, ToTTo and WebNLG. The results show that our model is able to control both the intra-sentence and inter-sentence structure of the generated output. Furthermore, empirical comparisons against previous state-of-the-art methods show that our model improves the generation quality as well as the output diversity as judged by human and automatic evaluations.
A Generative Model for Joint Natural Language Understanding and Generation
Jun 12, 2020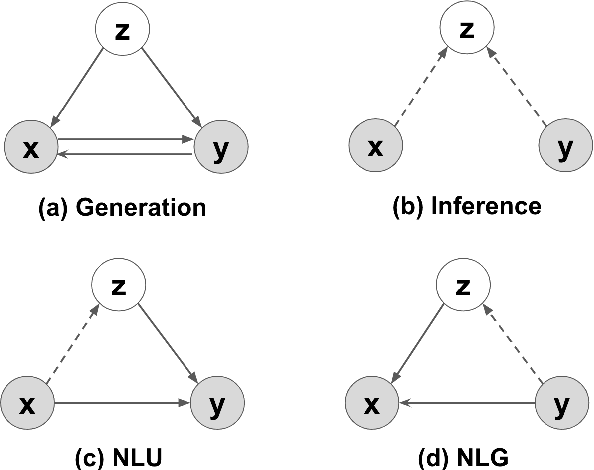


Natural language understanding (NLU) and natural language generation (NLG) are two fundamental and related tasks in building task-oriented dialogue systems with opposite objectives: NLU tackles the transformation from natural language to formal representations, whereas NLG does the reverse. A key to success in either task is parallel training data which is expensive to obtain at a large scale. In this work, we propose a generative model which couples NLU and NLG through a shared latent variable. This approach allows us to explore both spaces of natural language and formal representations, and facilitates information sharing through the latent space to eventually benefit NLU and NLG. Our model achieves state-of-the-art performance on two dialogue datasets with both flat and tree-structured formal representations. We also show that the model can be trained in a semi-supervised fashion by utilising unlabelled data to boost its performance.