 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Evaluation Metrics -- The Mirage of Hallucination Detection
Apr 25, 2025Hallucinations pose a significant obstacle to the reliability and widespread adoption of language models, yet their accurate measurement remains a persistent challenge. While many task- and domain-specific metrics have been proposed to assess faithfulness and factuality concerns, the robustness and generalization of these metrics are still untested. In this paper, we conduct a large-scale empirical evaluation of 6 diverse sets of hallucination detection metrics across 4 datasets, 37 language models from 5 families, and 5 decoding methods. Our extensive investigation reveals concerning gaps in current hallucination evaluation: metrics often fail to align with human judgments, take an overtly myopic view of the problem, and show inconsistent gains with parameter scaling. Encouragingly, LLM-based evaluation, particularly with GPT-4, yields the best overall results, and mode-seeking decoding methods seem to reduce hallucinations, especially in knowledge-grounded settings. These findings underscore the need for more robust metrics to understand and quantify hallucinations, and better strategies to mitigate them.
SynthDST: Synthetic Data is All You Need for Few-Shot Dialog State Tracking
Feb 03, 2024



In-context learning with Large Language Models (LLMs) has emerged as a promising avenue of research in Dialog State Tracking (DST). However, the best-performing in-context learning methods involve retrieving and adding similar examples to the prompt, requiring access to labeled training data. Procuring such training data for a wide range of domains and applications is time-consuming, expensive, and, at times, infeasible. While zero-shot learning requires no training data, it significantly lags behind the few-shot setup. Thus, `\textit{Can we efficiently generate synthetic data for any dialogue schema to enable few-shot prompting?}' Addressing this question, we propose \method, a data generation framework tailored for DST, utilizing LLMs. Our approach only requires the dialogue schema and a few hand-crafted dialogue templates to synthesize natural, coherent, and free-flowing dialogues with DST annotations. Few-shot learning using data from {\method} results in $4-5%$ improvement in Joint Goal Accuracy over the zero-shot baseline on MultiWOZ 2.1 and 2.4. Remarkably, our few-shot learning approach recovers nearly $98%$ of the performance compared to the few-shot setup using human-annotated training data. Our synthetic data and code can be accessed at https://github.com/apple/ml-synthdst
Can Large Language Models Understand Context?
Feb 01, 2024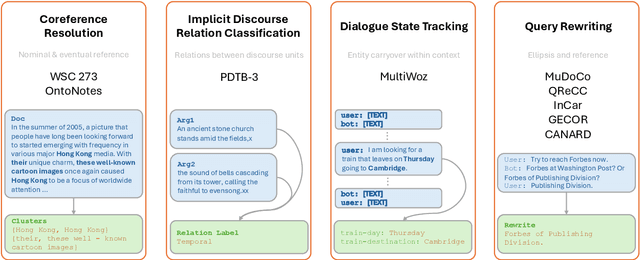


Understanding context is key to understanding human language, an ability which Large Language Models (LLMs) have been increasingly seen to demonstrate to an impressive extent. However, though the evaluation of LLMs encompasses various domains within the realm of Natural Language Processing, limited attention has been paid to probing their linguistic capability of understanding contextual features. This paper introduces a context understanding benchmark by adapting existing datasets to suit the evaluation of generative models. This benchmark comprises of four distinct tasks and nine datasets, all featuring prompts designed to assess the models' ability to understand context. First, we evaluate the performance of LLMs under the in-context learning pretraining scenario. Experimental results indicate that pre-trained dense models struggle with understanding more nuanced contextual features when compared to state-of-the-art fine-tuned models. Second, as LLM compression holds growing significance in both research and real-world applications, we assess the context understanding of quantized models under in-context-learning settings. We find that 3-bit post-training quantization leads to varying degrees of performance reduction on our benchmark. We conduct an extensive analysis of these scenarios to substantiate our experimental results.
MARRS: Multimodal Reference Resolution System
Nov 03, 2023



Successfully handling context is essential for any dialog understanding task. This context maybe be conversational (relying on previous user queries or system responses), visual (relying on what the user sees, for example, on their screen), or background (based on signals such as a ringing alarm or playing music). In this work, we present an overview of MARRS, or Multimodal Reference Resolution System, an on-device framework within a Natural Language Understanding system, responsible for handling conversational, visual and background context. In particular, we present different machine learning models to enable handing contextual queries; specifically, one to enable reference resolution, and one to handle context via query rewriting. We also describe how these models complement each other to form a unified, coherent, lightweight system that can understand context while preserving user privacy.
Grounding Description-Driven Dialogue State Trackers with Knowledge-Seeking Turns
Sep 23, 2023Schema-guided dialogue state trackers can generalise to new domains without further training, yet they are sensitive to the writing style of the schemata. Augmenting the training set with human or synthetic schema paraphrases improves the model robustness to these variations but can be either costly or difficult to control. We propose to circumvent these issues by grounding the state tracking model in knowledge-seeking turns collected from the dialogue corpus as well as the schema. Including these turns in prompts during finetuning and inference leads to marked improvements in model robustness, as demonstrated by large average joint goal accuracy and schema sensitivity improvements on SGD and SGD-X.
5IDER: Unified Query Rewriting for Steering, Intent Carryover, Disfluencies, Entity Carryover and Repair
Jun 02, 2023
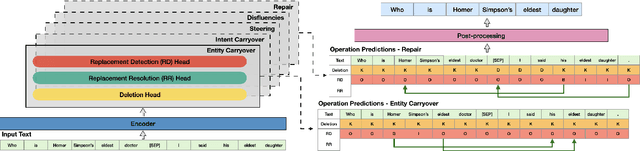
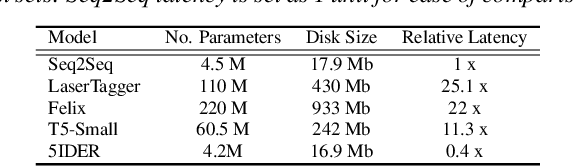
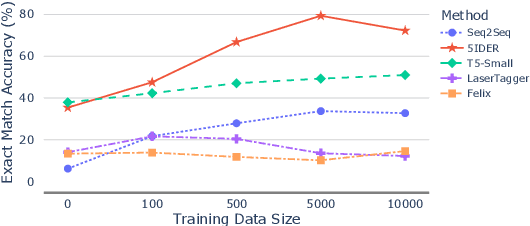
Providing voice assistants the ability to navigate multi-turn conversations is a challenging problem. Handling multi-turn interactions requires the system to understand various conversational use-cases, such as steering, intent carryover, disfluencies, entity carryover, and repair. The complexity of this problem is compounded by the fact that these use-cases mix with each other, often appearing simultaneously in natural language. This work proposes a non-autoregressive query rewriting architecture that can handle not only the five aforementioned tasks, but also complex compositions of these use-cases. We show that our proposed model has competitive single task performance compared to the baseline approach, and even outperforms a fine-tuned T5 model in use-case compositions, despite being 15 times smaller in parameters and 25 times faster in latency.
Transferable Dialogue Systems and User Simulators
Jul 25, 2021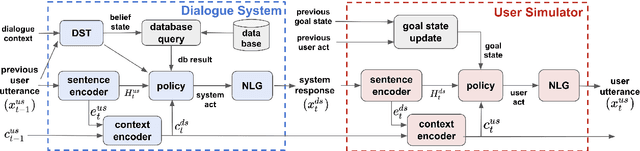
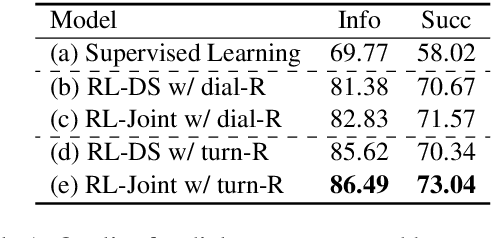
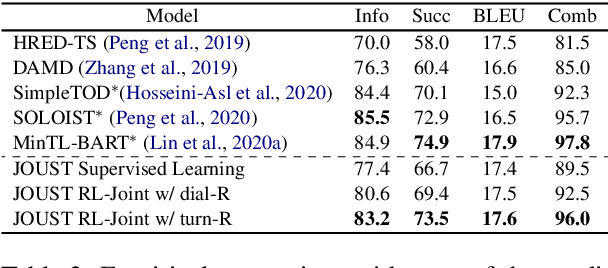
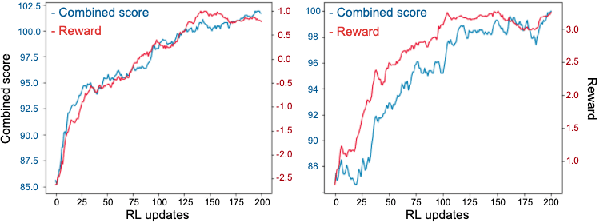
One of the difficulties in training dialogue systems is the lack of training data. We explore the possibility of creating dialogue data through the interaction between a dialogue system and a user simulator. Our goal is to develop a modelling framework that can incorporate new dialogue scenarios through self-play between the two agents. In this framework, we first pre-train the two agents on a collection of source domain dialogues, which equips the agents to converse with each other via natural language. With further fine-tuning on a small amount of target domain data, the agents continue to interact with the aim of improving their behaviors using reinforcement learning with structured reward functions. In experiments on the MultiWOZ dataset, two practical transfer learning problems are investigated: 1) domain adaptation and 2) single-to-multiple domain transfer. We demonstrate that the proposed framework is highly effective in bootstrapping the performance of the two agents in transfer learning. We also show that our method leads to improvements in dialogue system performance on complete datasets.
CREAD: Combined Resolution of Ellipses and Anaphora in Dialogues
May 20, 2021
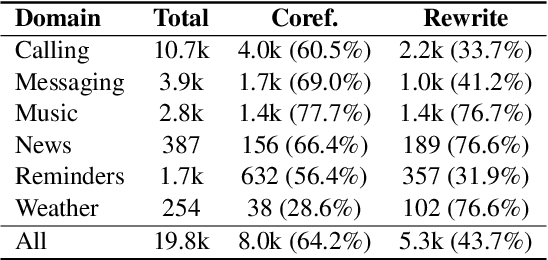

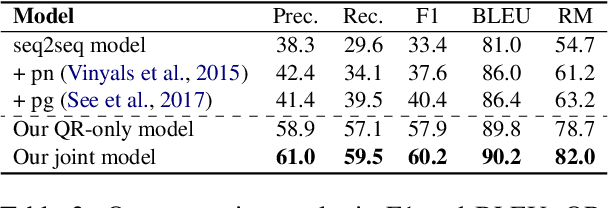
Anaphora and ellipses are two common phenomena in dialogues. Without resolving referring expressions and information omission, dialogue systems may fail to generate consistent and coherent responses. Traditionally, anaphora is resolved by coreference resolution and ellipses by query rewrite. In this work, we propose a novel joint learning framework of modeling coreference resolution and query rewriting for complex, multi-turn dialogue understanding. Given an ongoing dialogue between a user and a dialogue assistant, for the user query, our joint learning model first predicts coreference links between the query and the dialogue context, and then generates a self-contained rewritten user query. To evaluate our model, we annotate a dialogue based coreference resolution dataset, MuDoCo, with rewritten queries. Results show that the performance of query rewrite can be substantially boosted (+2.3% F1) with the aid of coreference modeling. Furthermore, our joint model outperforms the state-of-the-art coreference resolution model (+2% F1) on this dataset.
A Generative Model for Joint Natural Language Understanding and Generation
Jun 12, 2020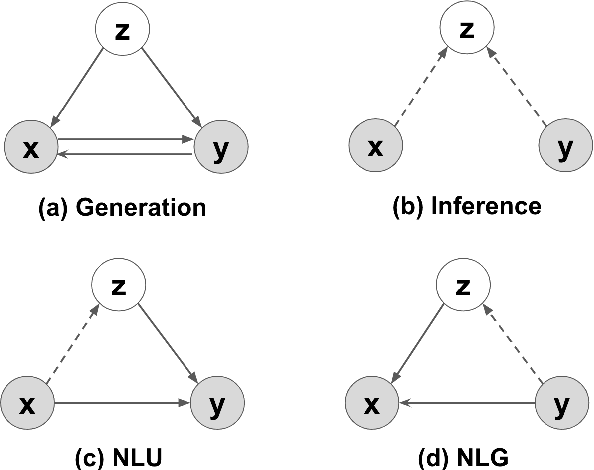


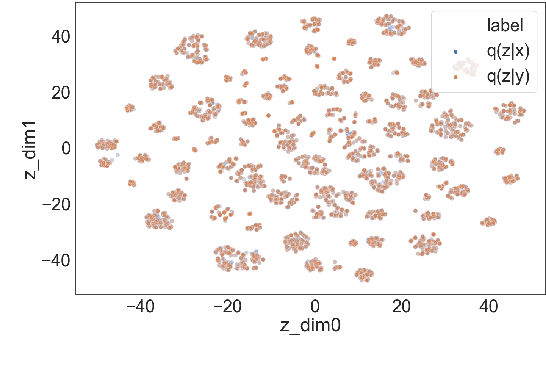
Natural language understanding (NLU) and natural language generation (NLG) are two fundamental and related tasks in building task-oriented dialogue systems with opposite objectives: NLU tackles the transformation from natural language to formal representations, whereas NLG does the reverse. A key to success in either task is parallel training data which is expensive to obtain at a large scale. In this work, we propose a generative model which couples NLU and NLG through a shared latent variable. This approach allows us to explore both spaces of natural language and formal representations, and facilitates information sharing through the latent space to eventually benefit NLU and NLG. Our model achieves state-of-the-art performance on two dialogue datasets with both flat and tree-structured formal representations. We also show that the model can be trained in a semi-supervised fashion by utilising unlabelled data to boost its performance.
Semi-supervised Bootstrapping of Dialogue State Trackers for Task Oriented Modelling
Nov 26, 2019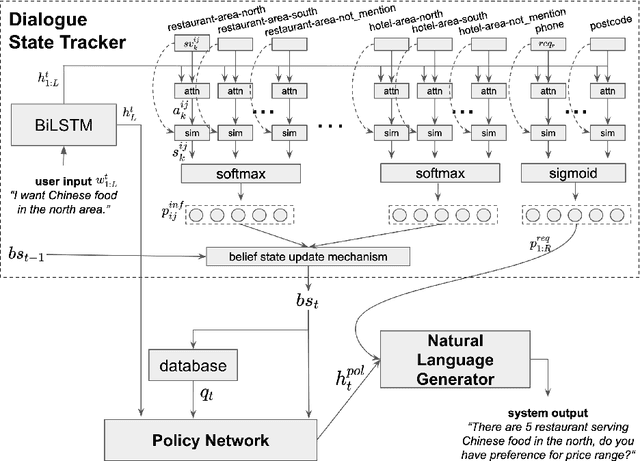

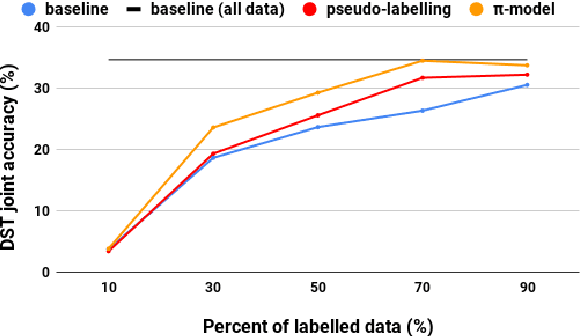
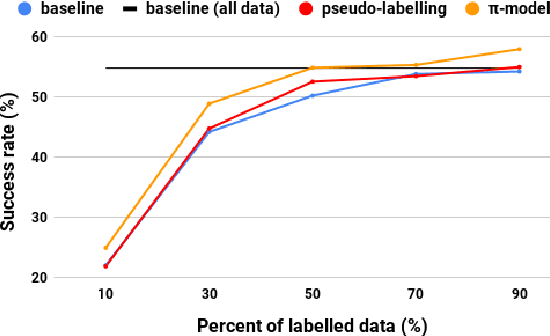
Dialogue systems benefit greatly from optimizing on detailed annotations, such as transcribed utterances, internal dialogue state representations and dialogue act labels. However, collecting these annotations is expensive and time-consuming, holding back development in the area of dialogue modelling. In this paper, we investigate semi-supervised learning methods that are able to reduce the amount of required intermediate labelling. We find that by leveraging un-annotated data instead, the amount of turn-level annotations of dialogue state can be significantly reduced when building a neural dialogue system. Our analysis on the MultiWOZ corpus, covering a range of domains and topics, finds that annotations can be reduced by up to 30\% while maintaining equivalent system performance. We also describe and evaluate the first end-to-end dialogue model created for the MultiWOZ corpus.