 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge5IDER: Unified Query Rewriting for Steering, Intent Carryover, Disfluencies, Entity Carryover and Repair
Jun 02, 2023
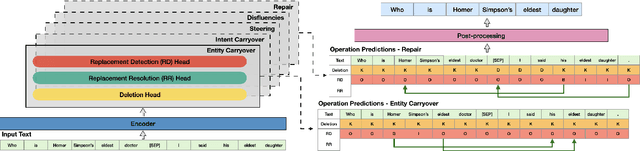
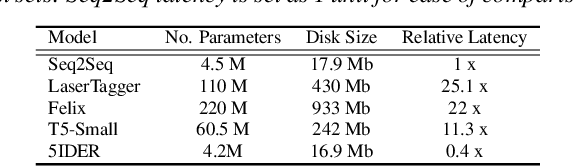
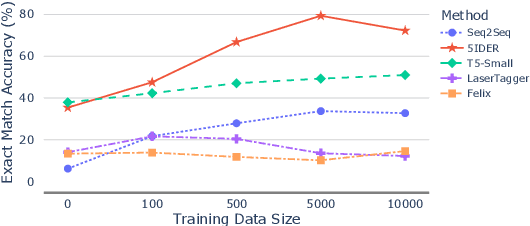
Providing voice assistants the ability to navigate multi-turn conversations is a challenging problem. Handling multi-turn interactions requires the system to understand various conversational use-cases, such as steering, intent carryover, disfluencies, entity carryover, and repair. The complexity of this problem is compounded by the fact that these use-cases mix with each other, often appearing simultaneously in natural language. This work proposes a non-autoregressive query rewriting architecture that can handle not only the five aforementioned tasks, but also complex compositions of these use-cases. We show that our proposed model has competitive single task performance compared to the baseline approach, and even outperforms a fine-tuned T5 model in use-case compositions, despite being 15 times smaller in parameters and 25 times faster in latency.
User-Initiated Repetition-Based Recovery in Multi-Utterance Dialogue Systems
Aug 02, 2021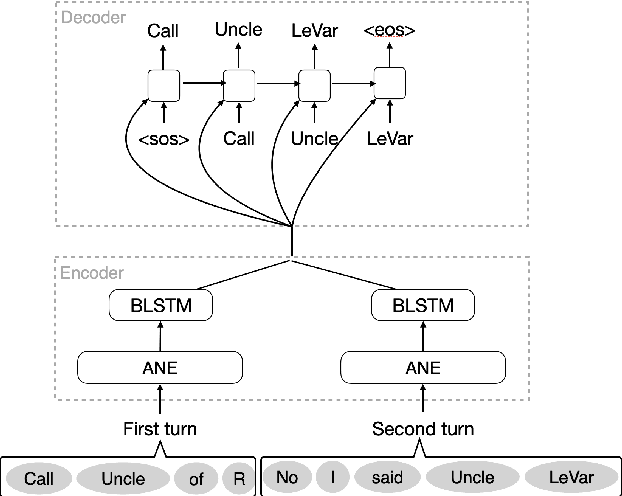
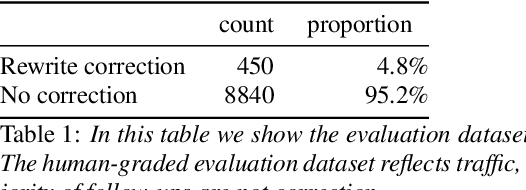
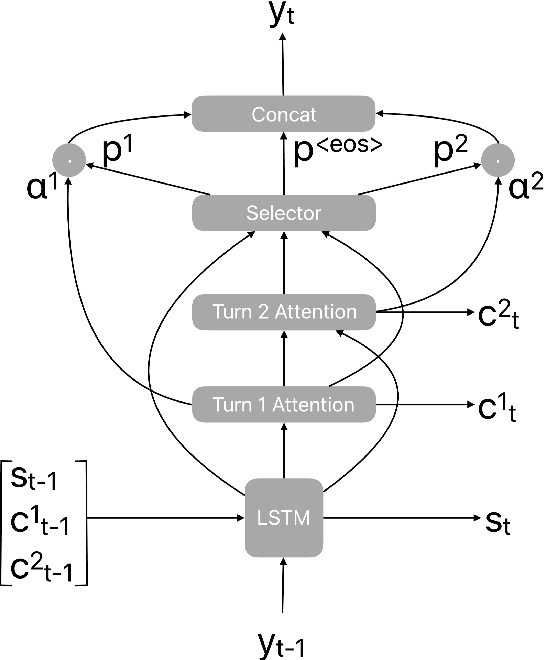

Recognition errors are common in human communication. Similar errors often lead to unwanted behaviour in dialogue systems or virtual assistants. In human communication, we can recover from them by repeating misrecognized words or phrases; however in human-machine communication this recovery mechanism is not available. In this paper, we attempt to bridge this gap and present a system that allows a user to correct speech recognition errors in a virtual assistant by repeating misunderstood words. When a user repeats part of the phrase the system rewrites the original query to incorporate the correction. This rewrite allows the virtual assistant to understand the original query successfully. We present an end-to-end 2-step attention pointer network that can generate the the rewritten query by merging together the incorrectly understood utterance with the correction follow-up. We evaluate the model on data collected for this task and compare the proposed model to a rule-based baseline and a standard pointer network. We show that rewriting the original query is an effective way to handle repetition-based recovery and that the proposed model outperforms the rule based baseline, reducing Word Error Rate by 19% relative at 2% False Alarm Rate on annotated data.