 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARRS: Multimodal Reference Resolution System
Nov 03, 2023



Successfully handling context is essential for any dialog understanding task. This context maybe be conversational (relying on previous user queries or system responses), visual (relying on what the user sees, for example, on their screen), or background (based on signals such as a ringing alarm or playing music). In this work, we present an overview of MARRS, or Multimodal Reference Resolution System, an on-device framework within a Natural Language Understanding system, responsible for handling conversational, visual and background context. In particular, we present different machine learning models to enable handing contextual queries; specifically, one to enable reference resolution, and one to handle context via query rewriting. We also describe how these models complement each other to form a unified, coherent, lightweight system that can understand context while preserving user privacy.
User-Initiated Repetition-Based Recovery in Multi-Utterance Dialogue Systems
Aug 02, 2021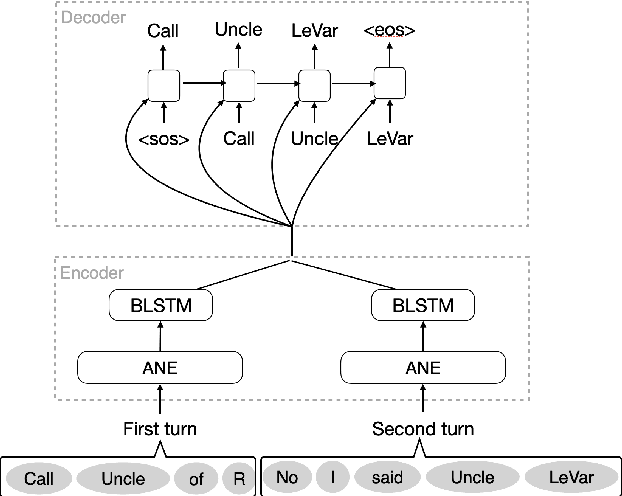
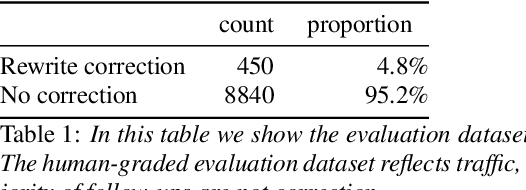
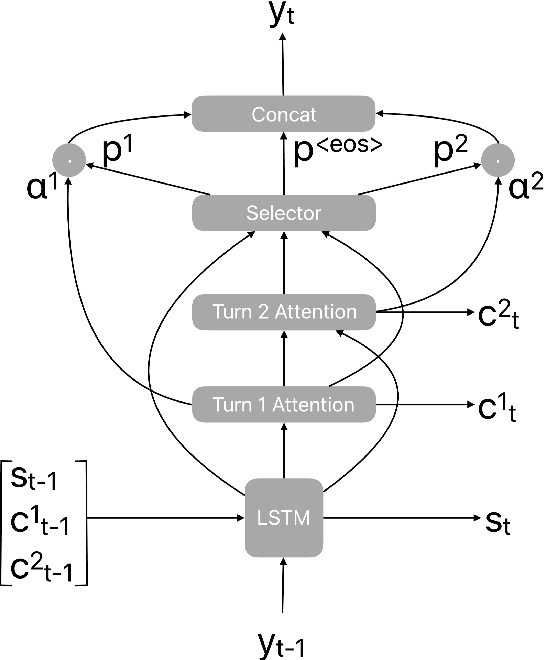

Recognition errors are common in human communication. Similar errors often lead to unwanted behaviour in dialogue systems or virtual assistants. In human communication, we can recover from them by repeating misrecognized words or phrases; however in human-machine communication this recovery mechanism is not available. In this paper, we attempt to bridge this gap and present a system that allows a user to correct speech recognition errors in a virtual assistant by repeating misunderstood words. When a user repeats part of the phrase the system rewrites the original query to incorporate the correction. This rewrite allows the virtual assistant to understand the original query successfully. We present an end-to-end 2-step attention pointer network that can generate the the rewritten query by merging together the incorrectly understood utterance with the correction follow-up. We evaluate the model on data collected for this task and compare the proposed model to a rule-based baseline and a standard pointer network. We show that rewriting the original query is an effective way to handle repetition-based recovery and that the proposed model outperforms the rule based baseline, reducing Word Error Rate by 19% relative at 2% False Alarm Rate on annotated data.