 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring to Screen Texts with Voice Assistants
Jun 10, 2023

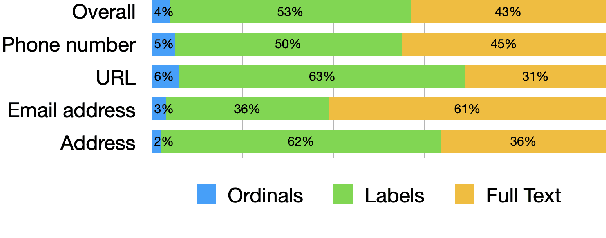

Voice assistants help users make phone calls, send messages, create events, navigate, and do a lot more. However, assistants have limited capacity to understand their users' context. In this work, we aim to take a step in this direction. Our work dives into a new experience for users to refer to phone numbers, addresses, email addresses, URLs, and dates on their phone screens. Our focus lies in reference understanding, which becomes particularly interesting when multiple similar texts are present on screen, similar to visual grounding. We collect a dataset and propose a lightweight general-purpose model for this novel experience. Due to the high cost of consuming pixels directly, our system is designed to rely on the extracted text from the UI. Our model is modular, thus offering flexibility, improved interpretability, and efficient runtime memory utilization.
User-Initiated Repetition-Based Recovery in Multi-Utterance Dialogue Systems
Aug 02, 2021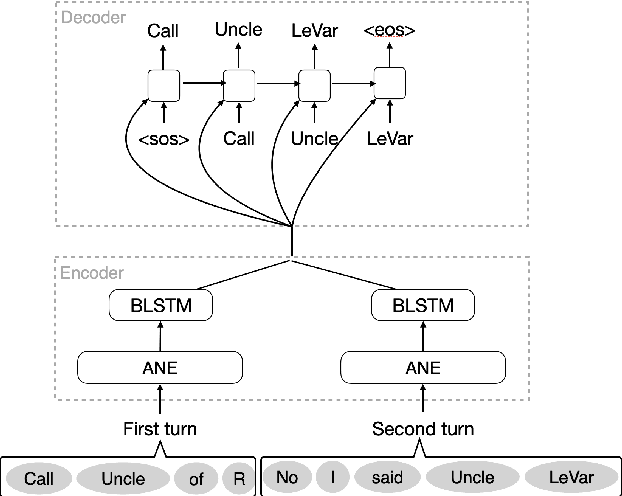
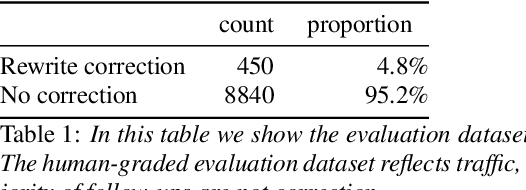
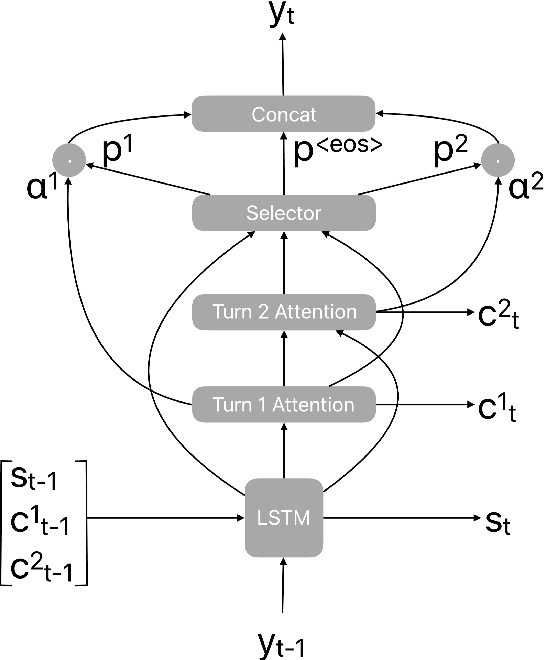

Recognition errors are common in human communication. Similar errors often lead to unwanted behaviour in dialogue systems or virtual assistants. In human communication, we can recover from them by repeating misrecognized words or phrases; however in human-machine communication this recovery mechanism is not available. In this paper, we attempt to bridge this gap and present a system that allows a user to correct speech recognition errors in a virtual assistant by repeating misunderstood words. When a user repeats part of the phrase the system rewrites the original query to incorporate the correction. This rewrite allows the virtual assistant to understand the original query successfully. We present an end-to-end 2-step attention pointer network that can generate the the rewritten query by merging together the incorrectly understood utterance with the correction follow-up. We evaluate the model on data collected for this task and compare the proposed model to a rule-based baseline and a standard pointer network. We show that rewriting the original query is an effective way to handle repetition-based recovery and that the proposed model outperforms the rule based baseline, reducing Word Error Rate by 19% relative at 2% False Alarm Rate on annotated data.
Google Trends Analysis of COVID-19
Nov 07, 2020
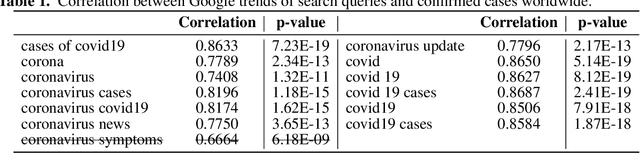
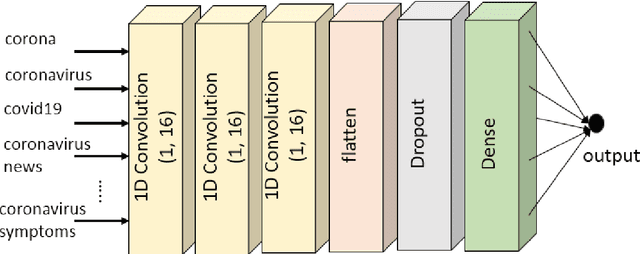
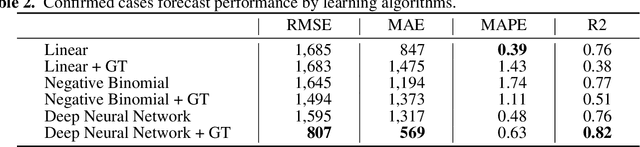
The World Health Organization (WHO) announced that COVID-19 was a pandemic disease on the 11th of March as there were 118K cases in several countries and territories. Numerous researchers worked on forecasting the number of confirmed cases since anticipating the growth of the cases helps governments adopting knotty decisions to ease the lockdowns orders for their countries. These orders help several people who have lost their jobs and support gravely impacted businesses. Our research aims to investigate the relation between Google search trends and the spreading of the novel coronavirus (COVID-19) over countries worldwide, to predict the number of cases. We perform a correlation analysis on the keywords of the related Google search trends according to the number of confirmed cases reported by the WHO. After that, we applied several machine learning techniques (Multiple Linear Regression, Non-negative Integer Regression, Deep Neural Network), to forecast the number of confirmed cases globally based on historical data as well as the hybrid data (Google search trends). Our results show that Google search trends are highly associated with the number of reported confirmed cases, where the Deep Learning approach outperforms other forecasting techniques. We believe that it is not only a promising approach for forecasting the confirmed cases of COVID-19, but also for similar forecasting problems that are associated with the related Google trends.
Alquist: The Alexa Prize Socialbot
Apr 18, 2018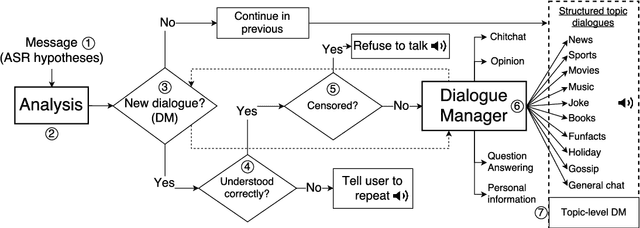
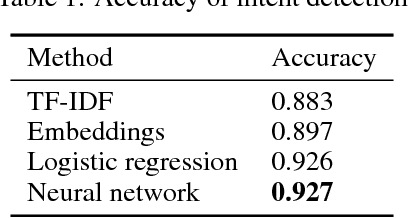
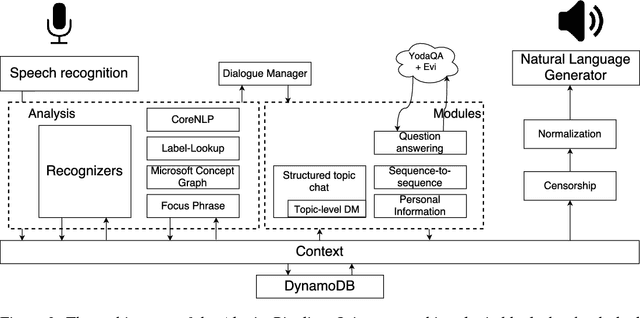
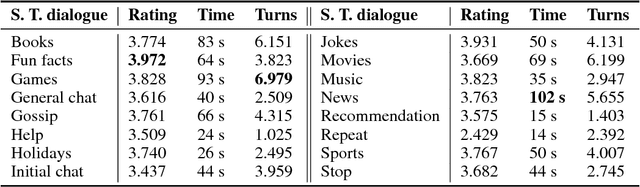
This paper describes a new open domain dialogue system Alquist developed as part of the Alexa Prize competition for the Amazon Echo line of products. The Alquist dialogue system is designed to conduct a coherent and engaging conversation on popular topics. We are presenting a hybrid system combining several machine learning and rule based approaches. We discuss and describe the Alquist pipeline, data acquisition, and processing, dialogue manager, NLG, knowledge aggregation and hierarchy of sub-dialogs. We present some of the experimental results.