 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMix: Automatically Mixing Language Models
Oct 19, 2023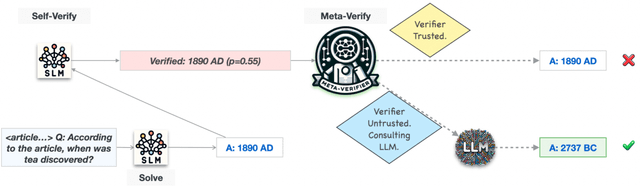
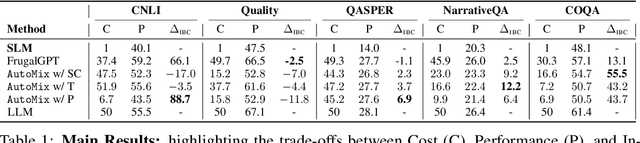
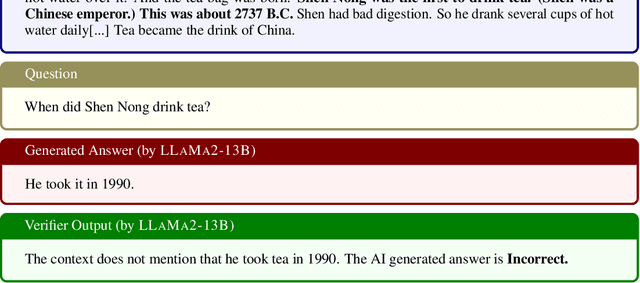

Large language models (LLMs) are now available in various sizes and configurations from cloud API providers. While this diversity offers a broad spectrum of choices, effectively leveraging the options to optimize computational cost and performance remains challenging. In this work, we present AutoMix, an approach that strategically routes queries to larger LMs, based on the approximate correctness of outputs from a smaller LM. Central to AutoMix is a few-shot self-verification mechanism, which estimates the reliability of its own outputs without requiring training. Given that verifications can be noisy, we employ a meta verifier in AutoMix to refine the accuracy of these assessments. Our experiments using LLAMA2-13/70B, on five context-grounded reasoning datasets demonstrate that AutoMix surpasses established baselines, improving the incremental benefit per cost by up to 89%. Our code and data are available at https://github.com/automix-llm/automix.
How FaR Are Large Language Models From Agents with Theory-of-Mind?
Oct 04, 2023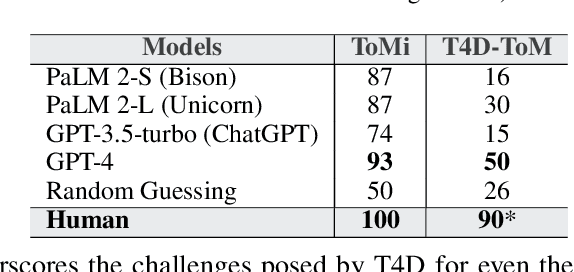


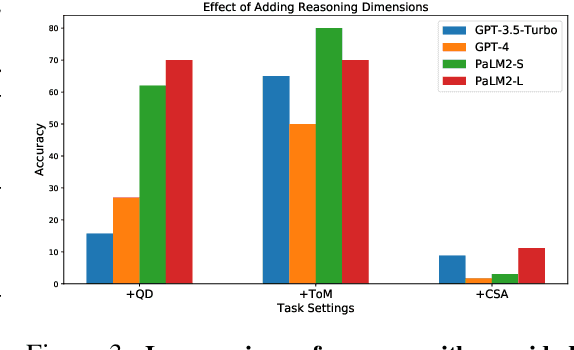
"Thinking is for Doing." Humans can infer other people's mental states from observations--an ability called Theory-of-Mind (ToM)--and subsequently act pragmatically on those inferences. Existing question answering benchmarks such as ToMi ask models questions to make inferences about beliefs of characters in a story, but do not test whether models can then use these inferences to guide their actions. We propose a new evaluation paradigm for large language models (LLMs): Thinking for Doing (T4D), which requires models to connect inferences about others' mental states to actions in social scenarios. Experiments on T4D demonstrate that LLMs such as GPT-4 and PaLM 2 seemingly excel at tracking characters' beliefs in stories, but they struggle to translate this capability into strategic action. Our analysis reveals the core challenge for LLMs lies in identifying the implicit inferences about mental states without being explicitly asked about as in ToMi, that lead to choosing the correct action in T4D. To bridge this gap, we introduce a zero-shot prompting framework, Foresee and Reflect (FaR), which provides a reasoning structure that encourages LLMs to anticipate future challenges and reason about potential actions. FaR boosts GPT-4's performance from 50% to 71% on T4D, outperforming other prompting methods such as Chain-of-Thought and Self-Ask. Moreover, FaR generalizes to diverse out-of-distribution story structures and scenarios that also require ToM inferences to choose an action, consistently outperforming other methods including few-shot in-context learning.
User-Initiated Repetition-Based Recovery in Multi-Utterance Dialogue Systems
Aug 02, 2021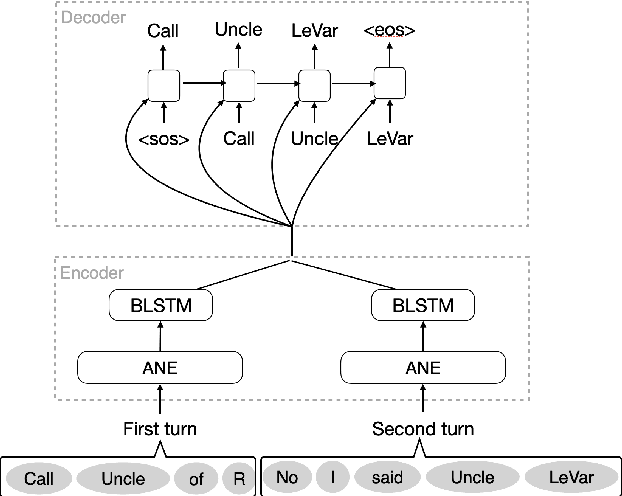
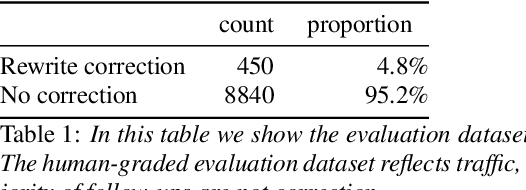
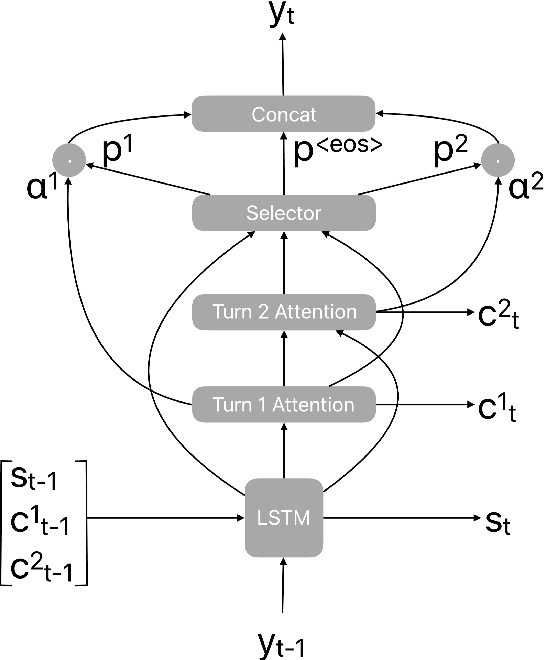

Recognition errors are common in human communication. Similar errors often lead to unwanted behaviour in dialogue systems or virtual assistants. In human communication, we can recover from them by repeating misrecognized words or phrases; however in human-machine communication this recovery mechanism is not available. In this paper, we attempt to bridge this gap and present a system that allows a user to correct speech recognition errors in a virtual assistant by repeating misunderstood words. When a user repeats part of the phrase the system rewrites the original query to incorporate the correction. This rewrite allows the virtual assistant to understand the original query successfully. We present an end-to-end 2-step attention pointer network that can generate the the rewritten query by merging together the incorrectly understood utterance with the correction follow-up. We evaluate the model on data collected for this task and compare the proposed model to a rule-based baseline and a standard pointer network. We show that rewriting the original query is an effective way to handle repetition-based recovery and that the proposed model outperforms the rule based baseline, reducing Word Error Rate by 19% relative at 2% False Alarm Rate on annotated data.
Tartan: A retrieval-based socialbot powered by a dynamic finite-state machine architecture
Dec 04, 2018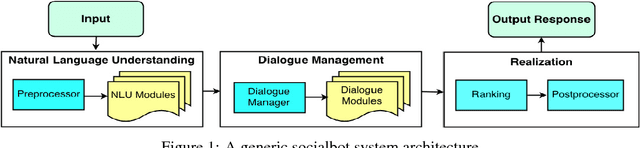
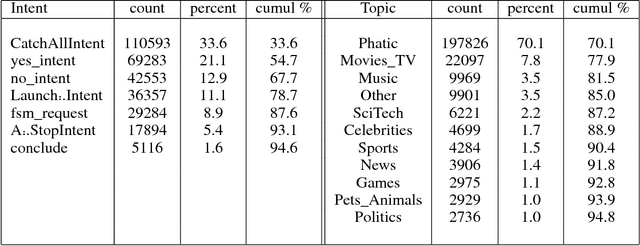
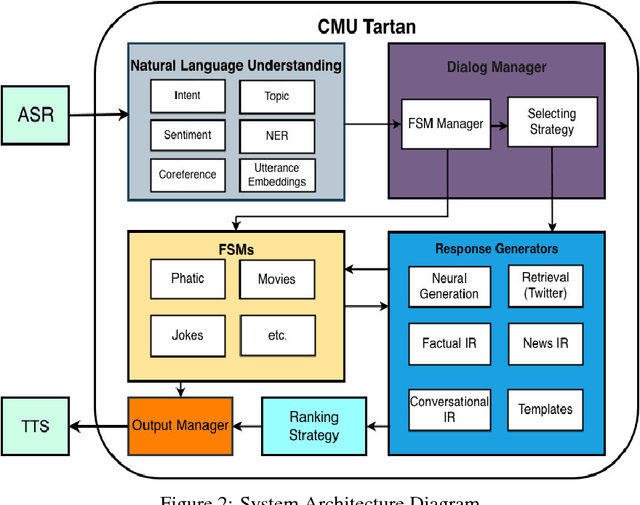
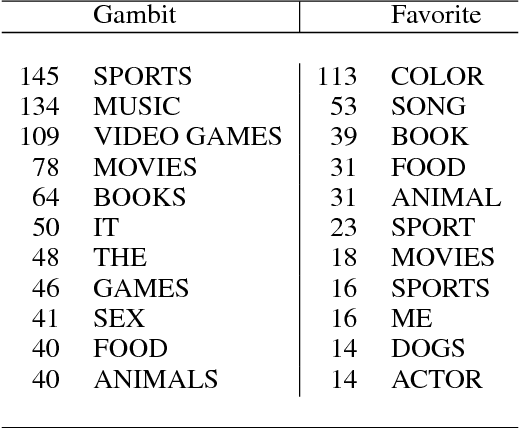
This paper describes the Tartan conversational agent built for the 2018 Alexa Prize Competition. Tartan is a non-goal-oriented socialbot focused around providing users with an engaging and fluent casual conversation. Tartan's key features include an emphasis on structured conversation based on flexible finite-state models and an approach focused on understanding and using conversational acts. To provide engaging conversations, Tartan blends script-like yet dynamic responses with data-based generative and retrieval models. Unique to Tartan is that our dialog manager is modeled as a dynamic Finite State Machine. To our knowledge, no other conversational agent implementation has followed this specific structure.