 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMix: Automatically Mixing Language Models
Oct 19, 2023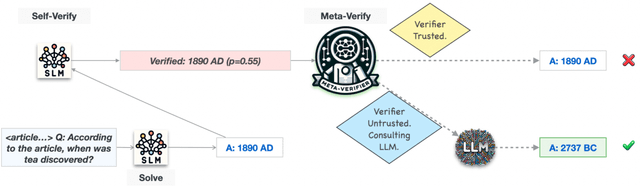
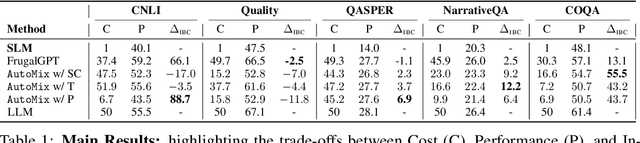
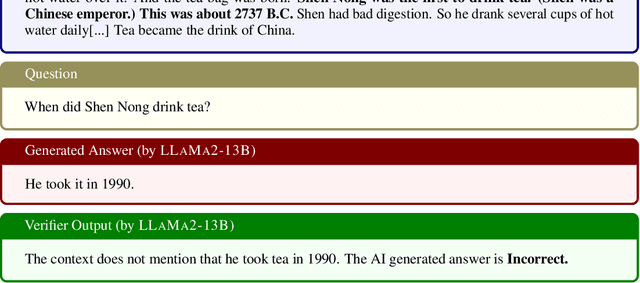

Large language models (LLMs) are now available in various sizes and configurations from cloud API providers. While this diversity offers a broad spectrum of choices, effectively leveraging the options to optimize computational cost and performance remains challenging. In this work, we present AutoMix, an approach that strategically routes queries to larger LMs, based on the approximate correctness of outputs from a smaller LM. Central to AutoMix is a few-shot self-verification mechanism, which estimates the reliability of its own outputs without requiring training. Given that verifications can be noisy, we employ a meta verifier in AutoMix to refine the accuracy of these assessments. Our experiments using LLAMA2-13/70B, on five context-grounded reasoning datasets demonstrate that AutoMix surpasses established baselines, improving the incremental benefit per cost by up to 89%. Our code and data are available at https://github.com/automix-llm/automix.
A Multi-Modal Approach to Infer Image Affect
Mar 13, 2018


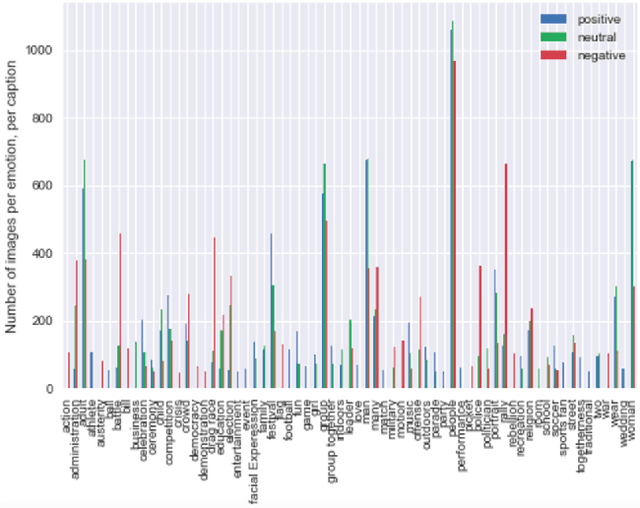
The group affect or emotion in an image of people can be inferred by extracting features about both the people in the picture and the overall makeup of the scene. The state-of-the-art on this problem investigates a combination of facial features, scene extraction and even audio tonality. This paper combines three additional modalities, namely, human pose, text-based tagging and CNN extracted features / predictions. To the best of our knowledge, this is the first time all of the modalities were extracted using deep neural networks. We evaluate the performance of our approach against baselines and identify insights throughout this paper.