 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning over mathematical objects: on-policy reward modeling and test time aggregation
Mar 19, 2026The ability to precisely derive mathematical objects is a core requirement for downstream STEM applications, including mathematics, physics, and chemistry, where reasoning must culminate in formally structured expressions. Yet, current LM evaluations of mathematical and scientific reasoning rely heavily on simplified answer formats such as numerical values or multiple choice options due to the convenience of automated assessment. In this paper we provide three contributions for improving reasoning over mathematical objects: (i) we build and release training data and benchmarks for deriving mathematical objects, the Principia suite; (ii) we provide training recipes with strong LLM-judges and verifiers, where we show that on-policy judge training boosts performance; (iii) we show how on-policy training can also be used to scale test-time compute via aggregation. We find that strong LMs such as Qwen3-235B and o3 struggle on Principia, while our training recipes can bring significant improvements over different LLM backbones, while simultaneously improving results on existing numerical and MCQA tasks, demonstrating cross-format generalization of reasoning abilities.
Propose, Solve, Verify: Self-Play Through Formal Verification
Dec 20, 2025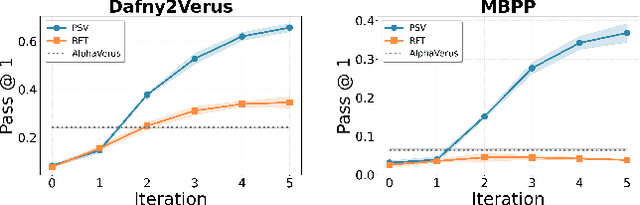
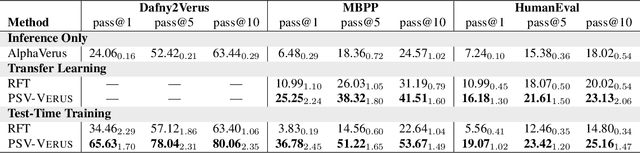
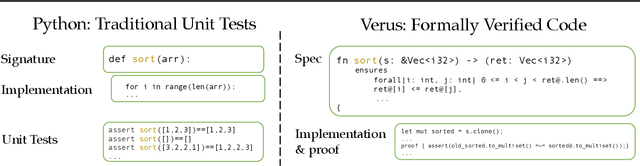

Training models through self-play alone (without any human data) has been a longstanding goal in AI, but its effectiveness for training large language models remains unclear, particularly in code generation where rewards based on unit tests are brittle and prone to error propagation. We study self-play in the verified code generation setting, where formal verification provides reliable correctness signals. We introduce Propose, Solve, Verify (PSV) a simple self-play framework where formal verification signals are used to create a proposer capable of generating challenging synthetic problems and a solver trained via expert iteration. We use PSV to train PSV-Verus, which across three benchmarks improves pass@1 by up to 9.6x over inference-only and expert-iteration baselines. We show that performance scales with the number of generated questions and training iterations, and through ablations identify formal verification and difficulty-aware proposal as essential ingredients for successful self-play.
OptimalThinkingBench: Evaluating Over and Underthinking in LLMs
Aug 18, 2025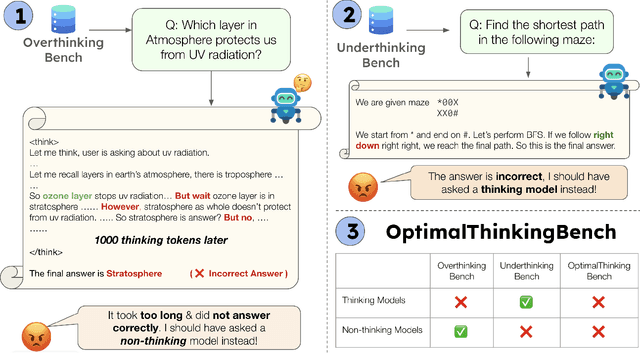
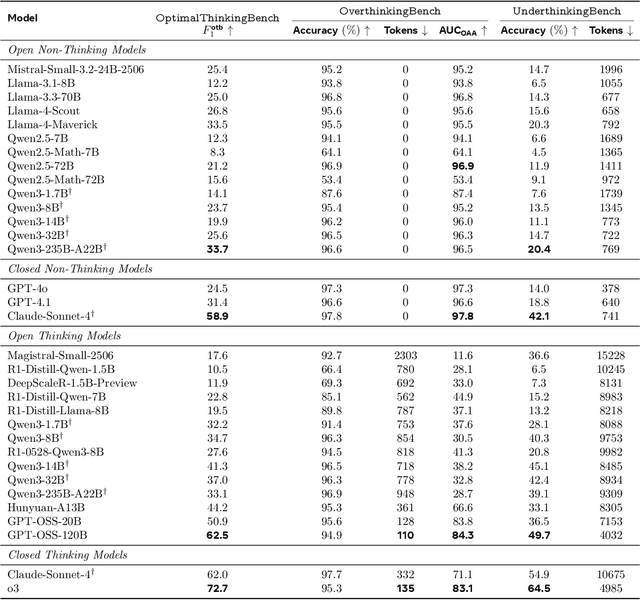

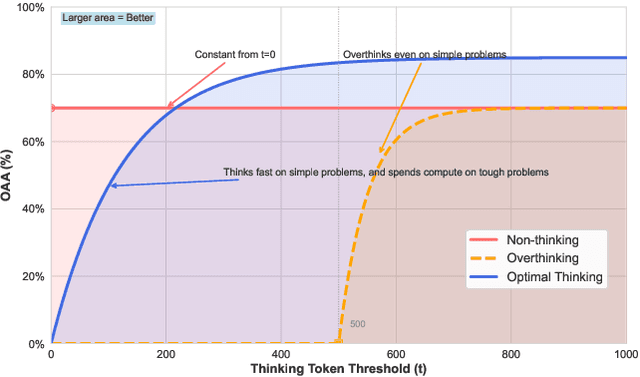
Thinking LLMs solve complex tasks at the expense of increased compute and overthinking on simpler problems, while non-thinking LLMs are faster and cheaper but underthink on harder reasoning problems. This has led to the development of separate thinking and non-thinking LLM variants, leaving the onus of selecting the optimal model for each query on the end user. In this work, we introduce OptimalThinkingBench, a unified benchmark that jointly evaluates overthinking and underthinking in LLMs and also encourages the development of optimally-thinking models that balance performance and efficiency. Our benchmark comprises two sub-benchmarks: OverthinkingBench, featuring simple queries in 72 domains, and UnderthinkingBench, containing 11 challenging reasoning tasks. Using novel thinking-adjusted accuracy metrics, we perform extensive evaluation of 33 different thinking and non-thinking models and show that no model is able to optimally think on our benchmark. Thinking models often overthink for hundreds of tokens on the simplest user queries without improving performance. In contrast, large non-thinking models underthink, often falling short of much smaller thinking models. We further explore several methods to encourage optimal thinking, but find that these approaches often improve on one sub-benchmark at the expense of the other, highlighting the need for better unified and optimal models in the future.
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning
Mar 06, 2025Reasoning language models have shown an uncanny ability to improve performance at test-time by ``thinking longer''-that is, by generating longer chain-of-thought sequences and hence using more compute. However, the length of their chain-of-thought reasoning is not controllable, making it impossible to allocate test-time compute to achieve a desired level of performance. We introduce Length Controlled Policy Optimization (LCPO), a simple reinforcement learning method that optimizes for accuracy and adherence to user-specified length constraints. We use LCPO to train L1, a reasoning language model that produces outputs satisfying a length constraint given in its prompt. L1's length control allows for smoothly trading off computational cost and accuracy on a wide range of tasks, and outperforms the state-of-the-art S1 method for length control. Furthermore, we uncover an unexpected short chain-of-thought capability in models trained with LCPO. For instance, our 1.5B L1 model surpasses GPT-4o at equal reasoning lengths. Overall, LCPO enables precise control over reasoning length, allowing for fine-grained allocation of test-time compute and accuracy. We release code and models at https://www.cmu-l3.github.io/l1
Programming with Pixels: Computer-Use Meets Software Engineering
Feb 24, 2025Recent advancements in software engineering (SWE) agents have largely followed a $\textit{tool-based paradigm}$, where agents interact with hand-engineered tool APIs to perform specific tasks. While effective for specialized tasks, these methods fundamentally lack generalization, as they require predefined tools for each task and do not scale across programming languages and domains. We introduce $\texttt{Programming with Pixels}$ (PwP), an agent environment that unifies software development tasks by enabling $\textit{computer-use agents}$-agents that operate directly within an IDE through visual perception, typing, and clicking, rather than relying on predefined tool APIs. To systematically evaluate these agents, we propose $\texttt{PwP-Bench}$, a benchmark that unifies existing SWE benchmarks spanning tasks across multiple programming languages, modalities, and domains under a task-agnostic state and action space. Our experiments demonstrate that general-purpose computer-use agents can approach or even surpass specialized tool-based agents on a variety of SWE tasks without the need for hand-engineered tools. However, our analysis shows that current models suffer from limited visual grounding and fail to exploit many IDE tools that could simplify their tasks. When agents can directly access IDE tools, without visual interaction, they show significant performance improvements, highlighting the untapped potential of leveraging built-in IDE capabilities. Our results establish PwP as a scalable testbed for building and evaluating the next wave of software engineering agents. We release code and data at https://programmingwithpixels.com
AlphaVerus: Bootstrapping Formally Verified Code Generation through Self-Improving Translation and Treefinement
Dec 09, 2024Automated code generation with large language models has gained significant traction, but there remains no guarantee on the correctness of generated code. We aim to use formal verification to provide mathematical guarantees that the generated code is correct. However, generating formally verified code with LLMs is hindered by the scarcity of training data and the complexity of formal proofs. To tackle this challenge, we introduce AlphaVerus, a self-improving framework that bootstraps formally verified code generation by iteratively translating programs from a higher-resource language and leveraging feedback from a verifier. AlphaVerus operates in three phases: exploration of candidate translations, Treefinement -- a novel tree search algorithm for program refinement using verifier feedback, and filtering misaligned specifications and programs to prevent reward hacking. Through this iterative process, AlphaVerus enables a LLaMA-3.1-70B model to generate verified code without human intervention or model finetuning. AlphaVerus shows an ability to generate formally verified solutions for HumanEval and MBPP, laying the groundwork for truly trustworthy code-generation agents.
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Apr 12, 2024



State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
GEO: Generative Engine Optimization
Nov 16, 2023



The advent of large language models (LLMs) has ushered in a new paradigm of search engines that use generative models to gather and summarize information to answer user queries. This emerging technology, which we formalize under the unified framework of Generative Engines (GEs), has the potential to generate accurate and personalized responses, and is rapidly replacing traditional search engines like Google and Bing. Generative Engines typically satisfy queries by synthesizing information from multiple sources and summarizing them with the help of LLMs. While this shift significantly improves \textit{user} utility and \textit{generative search engine} traffic, it results in a huge challenge for the third stakeholder -- website and content creators. Given the black-box and fast-moving nature of Generative Engines, content creators have little to no control over when and how their content is displayed. With generative engines here to stay, the right tools should be provided to ensure that creator economy is not severely disadvantaged. To address this, we introduce Generative Engine Optimization (GEO), a novel paradigm to aid content creators in improving the visibility of their content in Generative Engine responses through a black-box optimization framework for optimizing and defining visibility metrics. We facilitate systematic evaluation in this new paradigm by introducing GEO-bench, a benchmark of diverse user queries across multiple domains, coupled with sources required to answer these queries. Through rigorous evaluation, we show that GEO can boost visibility by up to 40\% in generative engine responses. Moreover, we show the efficacy of these strategies varies across domains, underscoring the need for domain-specific methods. Our work opens a new frontier in the field of information discovery systems, with profound implications for generative engines and content creators.
AutoMix: Automatically Mixing Language Models
Oct 19, 2023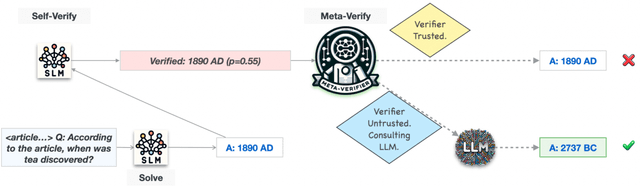
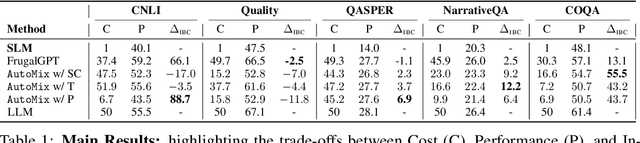
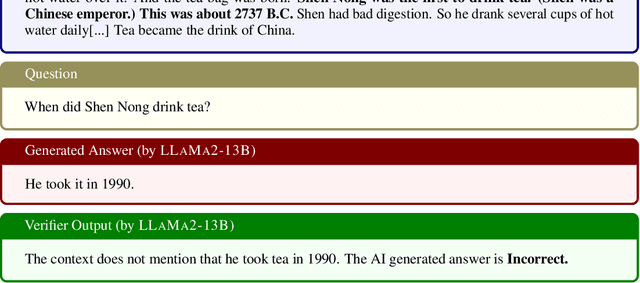

Large language models (LLMs) are now available in various sizes and configurations from cloud API providers. While this diversity offers a broad spectrum of choices, effectively leveraging the options to optimize computational cost and performance remains challenging. In this work, we present AutoMix, an approach that strategically routes queries to larger LMs, based on the approximate correctness of outputs from a smaller LM. Central to AutoMix is a few-shot self-verification mechanism, which estimates the reliability of its own outputs without requiring training. Given that verifications can be noisy, we employ a meta verifier in AutoMix to refine the accuracy of these assessments. Our experiments using LLAMA2-13/70B, on five context-grounded reasoning datasets demonstrate that AutoMix surpasses established baselines, improving the incremental benefit per cost by up to 89%. Our code and data are available at https://github.com/automix-llm/automix.
Let's Sample Step by Step: Adaptive-Consistency for Efficient Reasoning with LLMs
May 19, 2023



A popular approach for improving the correctness of output from large language models (LLMs) is Self-Consistency - poll the LLM multiple times and output the most frequent solution. Existing Self-Consistency techniques always draw a constant number of samples per question, where a better approach will be to non-uniformly distribute the available budget based on the amount of agreement in the samples drawn so far. In response, we introduce Adaptive-Consistency, a cost-efficient, model-agnostic technique that dynamically adjusts the number of samples per question using a lightweight stopping criterion. Our experiments over 13 datasets and two LLMs demonstrate that Adaptive-Consistency reduces sample budget by up to 6.0 times with an average accuracy drop of less than 0.1%.