 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning over mathematical objects: on-policy reward modeling and test time aggregation
Mar 19, 2026The ability to precisely derive mathematical objects is a core requirement for downstream STEM applications, including mathematics, physics, and chemistry, where reasoning must culminate in formally structured expressions. Yet, current LM evaluations of mathematical and scientific reasoning rely heavily on simplified answer formats such as numerical values or multiple choice options due to the convenience of automated assessment. In this paper we provide three contributions for improving reasoning over mathematical objects: (i) we build and release training data and benchmarks for deriving mathematical objects, the Principia suite; (ii) we provide training recipes with strong LLM-judges and verifiers, where we show that on-policy judge training boosts performance; (iii) we show how on-policy training can also be used to scale test-time compute via aggregation. We find that strong LMs such as Qwen3-235B and o3 struggle on Principia, while our training recipes can bring significant improvements over different LLM backbones, while simultaneously improving results on existing numerical and MCQA tasks, demonstrating cross-format generalization of reasoning abilities.
Text-to-Stage: Spatial Layouts from Long-form Narratives
Mar 18, 2026In this work, we probe the ability of a language model to demonstrate spatial reasoning from unstructured text, mimicking human capabilities and automating a process that benefits many downstream media applications. Concretely, we study the narrative-to-play task: inferring stage-play layouts (scenes, speaker positions, movements, and room types) from text that lacks explicit spatial, positional, or relational cues. We then introduce a dramaturgy-inspired deterministic evaluation suite and, finally, a training and inference recipe that combines rejection SFT using Best-of-N sampling with RL from verifiable rewards via GRPO. Experiments on a text-only corpus of classical English literature demonstrate improvements over vanilla models across multiple metrics (character attribution, spatial plausibility, and movement economy), as well as alignment with an LLM-as-a-judge and subjective human preferences.
Hybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense
Oct 08, 2025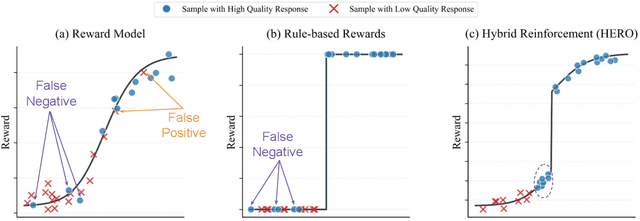
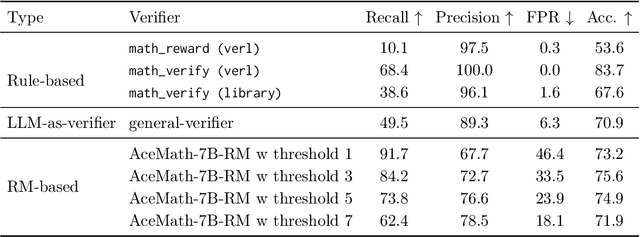
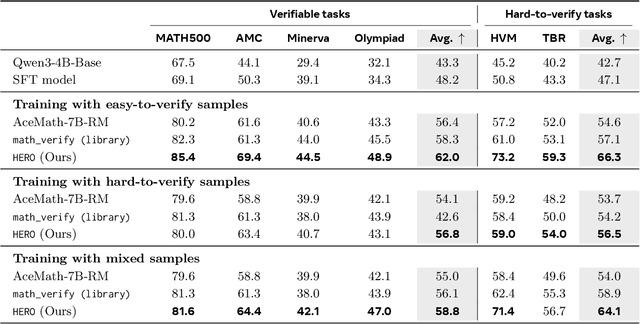
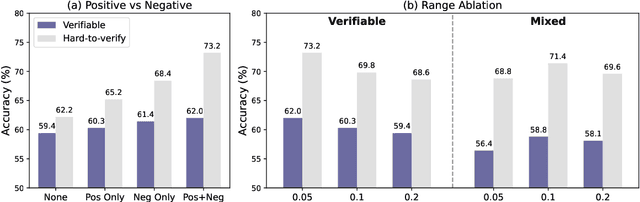
Post-training for reasoning of large language models (LLMs) increasingly relies on verifiable rewards: deterministic checkers that provide 0-1 correctness signals. While reliable, such binary feedback is brittle--many tasks admit partially correct or alternative answers that verifiers under-credit, and the resulting all-or-nothing supervision limits learning. Reward models offer richer, continuous feedback, which can serve as a complementary supervisory signal to verifiers. We introduce HERO (Hybrid Ensemble Reward Optimization), a reinforcement learning framework that integrates verifier signals with reward-model scores in a structured way. HERO employs stratified normalization to bound reward-model scores within verifier-defined groups, preserving correctness while refining quality distinctions, and variance-aware weighting to emphasize challenging prompts where dense signals matter most. Across diverse mathematical reasoning benchmarks, HERO consistently outperforms RM-only and verifier-only baselines, with strong gains on both verifiable and hard-to-verify tasks. Our results show that hybrid reward design retains the stability of verifiers while leveraging the nuance of reward models to advance reasoning.
OptimalThinkingBench: Evaluating Over and Underthinking in LLMs
Aug 18, 2025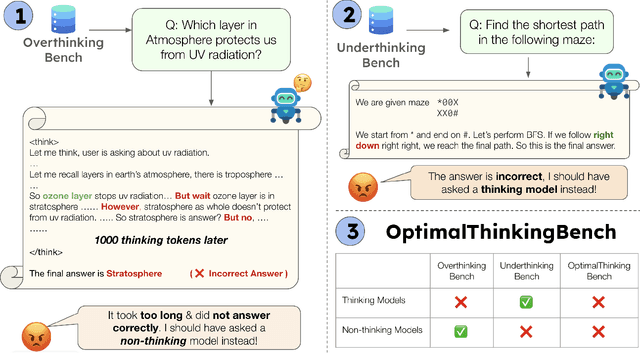
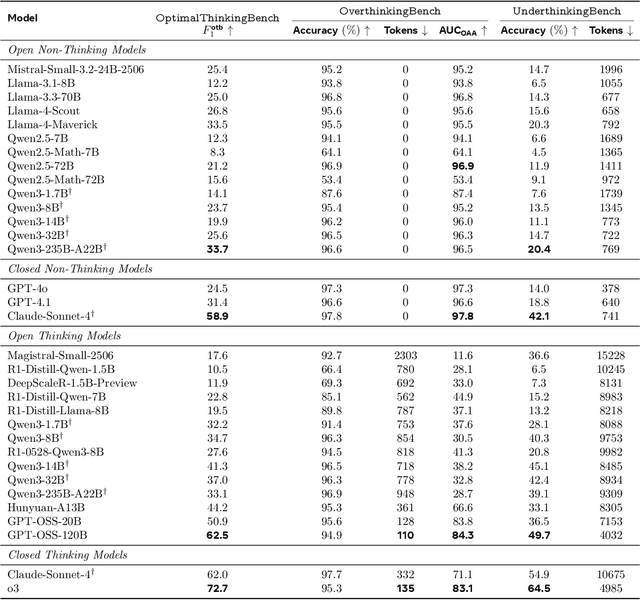

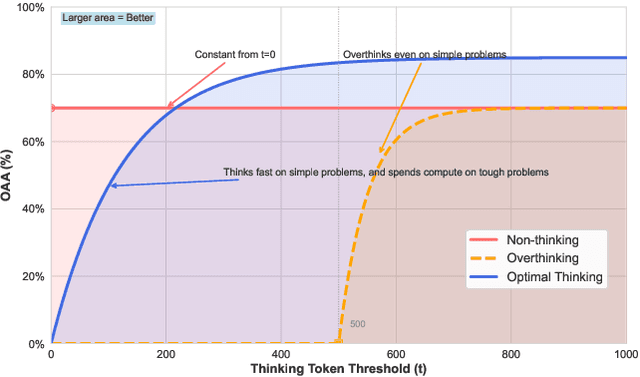
Thinking LLMs solve complex tasks at the expense of increased compute and overthinking on simpler problems, while non-thinking LLMs are faster and cheaper but underthink on harder reasoning problems. This has led to the development of separate thinking and non-thinking LLM variants, leaving the onus of selecting the optimal model for each query on the end user. In this work, we introduce OptimalThinkingBench, a unified benchmark that jointly evaluates overthinking and underthinking in LLMs and also encourages the development of optimally-thinking models that balance performance and efficiency. Our benchmark comprises two sub-benchmarks: OverthinkingBench, featuring simple queries in 72 domains, and UnderthinkingBench, containing 11 challenging reasoning tasks. Using novel thinking-adjusted accuracy metrics, we perform extensive evaluation of 33 different thinking and non-thinking models and show that no model is able to optimally think on our benchmark. Thinking models often overthink for hundreds of tokens on the simplest user queries without improving performance. In contrast, large non-thinking models underthink, often falling short of much smaller thinking models. We further explore several methods to encourage optimal thinking, but find that these approaches often improve on one sub-benchmark at the expense of the other, highlighting the need for better unified and optimal models in the future.
Bridging Offline and Online Reinforcement Learning for LLMs
Jun 26, 2025We investigate the effectiveness of reinforcement learning methods for finetuning large language models when transitioning from offline to semi-online to fully online regimes for both verifiable and non-verifiable tasks. Our experiments cover training on verifiable math as well as non-verifiable instruction following with a set of benchmark evaluations for both. Across these settings, we extensively compare online and semi-online Direct Preference Optimization and Group Reward Policy Optimization objectives, and surprisingly find similar performance and convergence between these variants, which all strongly outperform offline methods. We provide a detailed analysis of the training dynamics and hyperparameter selection strategies to achieve optimal results. Finally, we show that multi-tasking with verifiable and non-verifiable rewards jointly yields improved performance across both task types.
J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning
May 15, 2025The progress of AI is bottlenecked by the quality of evaluation, and powerful LLM-as-a-Judge models have proved to be a core solution. Improved judgment ability is enabled by stronger chain-of-thought reasoning, motivating the need to find the best recipes for training such models to think. In this work we introduce J1, a reinforcement learning approach to training such models. Our method converts both verifiable and non-verifiable prompts to judgment tasks with verifiable rewards that incentivize thinking and mitigate judgment bias. In particular, our approach outperforms all other existing 8B or 70B models when trained at those sizes, including models distilled from DeepSeek-R1. J1 also outperforms o1-mini, and even R1 on some benchmarks, despite training a smaller model. We provide analysis and ablations comparing Pairwise-J1 vs Pointwise-J1 models, offline vs online training recipes, reward strategies, seed prompts, and variations in thought length and content. We find that our models make better judgments by learning to outline evaluation criteria, comparing against self-generated reference answers, and re-evaluating the correctness of model responses.
Learning to Plan & Reason for Evaluation with Thinking-LLM-as-a-Judge
Jan 30, 2025



LLM-as-a-Judge models generate chain-of-thought (CoT) sequences intended to capture the step-bystep reasoning process that underlies the final evaluation of a response. However, due to the lack of human annotated CoTs for evaluation, the required components and structure of effective reasoning traces remain understudied. Consequently, previous approaches often (1) constrain reasoning traces to hand-designed components, such as a list of criteria, reference answers, or verification questions and (2) structure them such that planning is intertwined with the reasoning for evaluation. In this work, we propose EvalPlanner, a preference optimization algorithm for Thinking-LLM-as-a-Judge that first generates an unconstrained evaluation plan, followed by its execution, and then the final judgment. In a self-training loop, EvalPlanner iteratively optimizes over synthetically constructed evaluation plans and executions, leading to better final verdicts. Our method achieves a new state-of-the-art performance for generative reward models on RewardBench (with a score of 93.9), despite being trained on fewer amount of, and synthetically generated, preference pairs. Additional experiments on other benchmarks like RM-Bench, JudgeBench, and FollowBenchEval further highlight the utility of both planning and reasoning for building robust LLM-as-a-Judge reasoning models.
MAgICoRe: Multi-Agent, Iterative, Coarse-to-Fine Refinement for Reasoning
Sep 18, 2024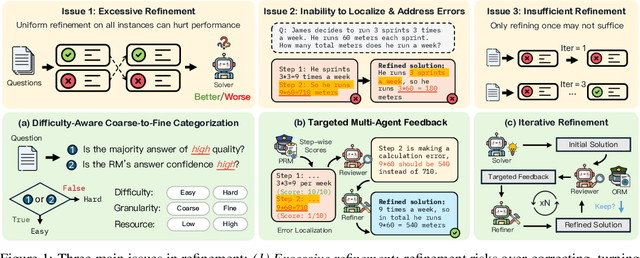
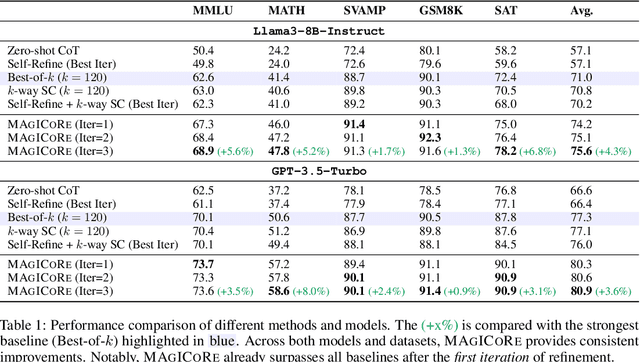
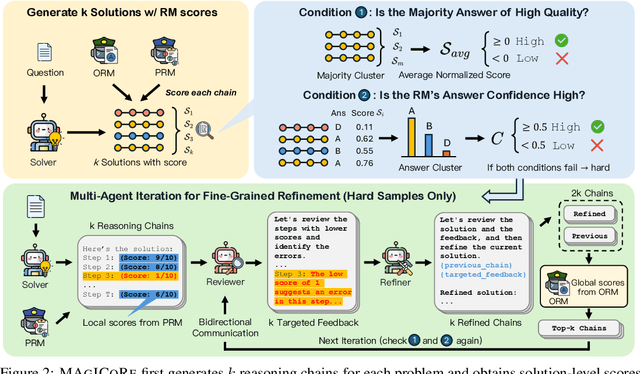
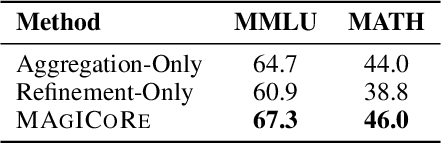
Large Language Models' (LLM) reasoning can be improved using test-time aggregation strategies, i.e., generating multiple samples and voting among generated samples. While these improve performance, they often reach a saturation point. Refinement offers an alternative by using LLM-generated feedback to improve solution quality. However, refinement introduces 3 key challenges: (1) Excessive refinement: Uniformly refining all instances can over-correct and reduce the overall performance. (2) Inability to localize and address errors: LLMs have a limited ability to self-correct and struggle to identify and correct their own mistakes. (3) Insufficient refinement: Deciding how many iterations of refinement are needed is non-trivial, and stopping too soon could leave errors unaddressed. To tackle these issues, we propose MAgICoRe, which avoids excessive refinement by categorizing problem difficulty as easy or hard, solving easy problems with coarse-grained aggregation and hard ones with fine-grained and iterative multi-agent refinement. To improve error localization, we incorporate external step-wise reward model (RM) scores. Moreover, to ensure effective refinement, we employ a multi-agent loop with three agents: Solver, Reviewer (which generates targeted feedback based on step-wise RM scores), and the Refiner (which incorporates feedback). To ensure sufficient refinement, we re-evaluate updated solutions, iteratively initiating further rounds of refinement. We evaluate MAgICoRe on Llama-3-8B and GPT-3.5 and show its effectiveness across 5 math datasets. Even one iteration of MAgICoRe beats Self-Consistency by 3.4%, Best-of-k by 3.2%, and Self-Refine by 4.0% while using less than half the samples. Unlike iterative refinement with baselines, MAgICoRe continues to improve with more iterations. Finally, our ablations highlight the importance of MAgICoRe's RMs and multi-agent communication.
System-1.x: Learning to Balance Fast and Slow Planning with Language Models
Jul 19, 2024

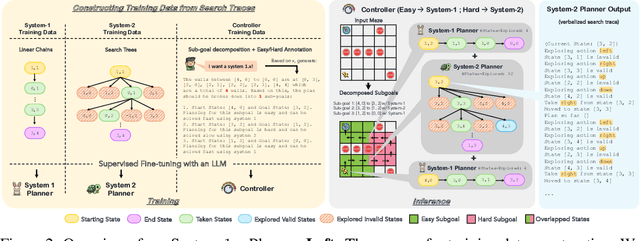

Language models can be used to solve long-horizon planning problems in two distinct modes: a fast 'System-1' mode, directly generating plans without any explicit search or backtracking, and a slow 'System-2' mode, planning step-by-step by explicitly searching over possible actions. While System-2 is typically more effective, it is also more computationally expensive, making it infeasible for long plans or large action spaces. Moreover, isolated System-1 or 2 ignores the user's end goals, failing to provide ways to control the model's behavior. To this end, we propose the System-1.x Planner, a controllable planning framework with LLMs that is capable of generating hybrid plans and balancing between the two planning modes based on the difficulty of the problem at hand. System-1.x consists of (i) a controller, (ii) a System-1 Planner, and (iii) a System-2 Planner. Based on a user-specified hybridization factor (x) governing the mixture between System-1 and 2, the controller decomposes a problem into sub-goals, and classifies them as easy or hard to be solved by either System-1 or 2, respectively. We fine-tune all three components on top of a single base LLM, requiring only search traces as supervision. Experiments with two diverse planning tasks -- Maze Navigation and Blocksworld -- show that our System-1.x Planner outperforms a System-1 Planner, a System-2 Planner trained to approximate A* search, and also a symbolic planner (A*). We demonstrate the following key properties of our planner: (1) controllability: increasing the hybridization factor (e.g., System-1.75 vs 1.5) performs more search, improving performance, (2) flexibility: by building a neuro-symbolic variant with a neural System-1 and a symbolic System-2, we can use existing symbolic methods, and (3) generalizability: by being able to learn from different search algorithms, our method is robust to the choice of search algorithm.
MAGDi: Structured Distillation of Multi-Agent Interaction Graphs Improves Reasoning in Smaller Language Models
Feb 02, 2024Multi-agent interactions between Large Language Model (LLM) agents have shown major improvements on diverse reasoning tasks. However, these involve long generations from multiple models across several rounds, making them expensive. Moreover, these multi-agent approaches fail to provide a final, single model for efficient inference. To address this, we introduce MAGDi, a new method for structured distillation of the reasoning interactions between multiple LLMs into smaller LMs. MAGDi teaches smaller models by representing multi-agent interactions as graphs, augmenting a base student model with a graph encoder, and distilling knowledge using three objective functions: next-token prediction, a contrastive loss between correct and incorrect reasoning, and a graph-based objective to model the interaction structure. Experiments on seven widely-used commonsense and math reasoning benchmarks show that MAGDi improves the reasoning capabilities of smaller models, outperforming several methods that distill from a single teacher and multiple teachers. Moreover, MAGDi also demonstrates an order of magnitude higher efficiency over its teachers. We conduct extensive analyses to show that MAGDi (1) enhances the generalizability to out-of-domain tasks, (2) scales positively with the size and strength of the base student model, and (3) obtains larger improvements (via our multi-teacher training) when applying self-consistency - an inference technique that relies on model diversity.