 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAgICoRe: Multi-Agent, Iterative, Coarse-to-Fine Refinement for Reasoning
Paper and Code
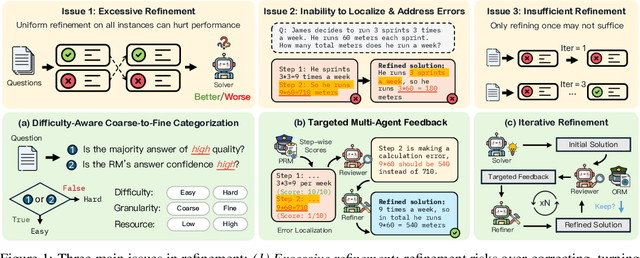
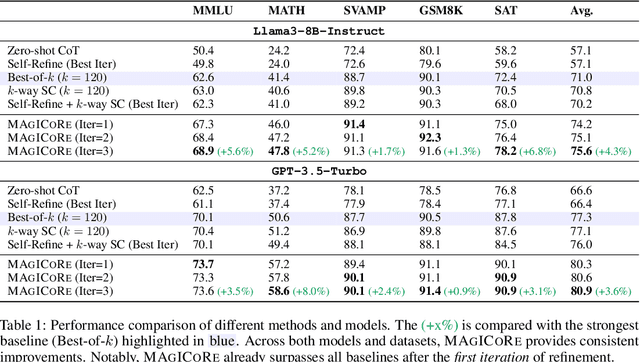
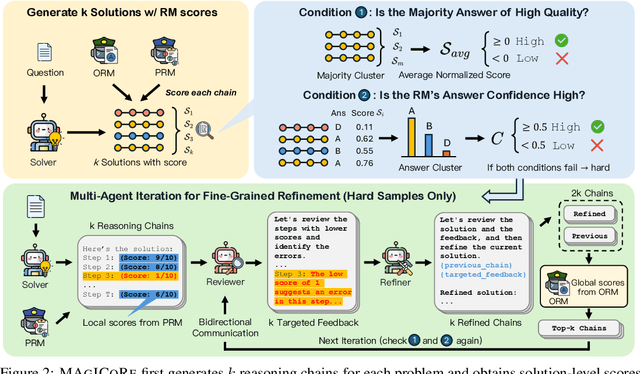
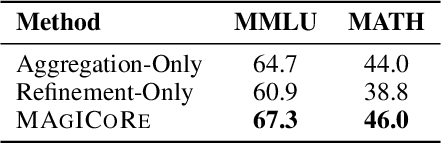
Large Language Models' (LLM) reasoning can be improved using test-time aggregation strategies, i.e., generating multiple samples and voting among generated samples. While these improve performance, they often reach a saturation point. Refinement offers an alternative by using LLM-generated feedback to improve solution quality. However, refinement introduces 3 key challenges: (1) Excessive refinement: Uniformly refining all instances can over-correct and reduce the overall performance. (2) Inability to localize and address errors: LLMs have a limited ability to self-correct and struggle to identify and correct their own mistakes. (3) Insufficient refinement: Deciding how many iterations of refinement are needed is non-trivial, and stopping too soon could leave errors unaddressed. To tackle these issues, we propose MAgICoRe, which avoids excessive refinement by categorizing problem difficulty as easy or hard, solving easy problems with coarse-grained aggregation and hard ones with fine-grained and iterative multi-agent refinement. To improve error localization, we incorporate external step-wise reward model (RM) scores. Moreover, to ensure effective refinement, we employ a multi-agent loop with three agents: Solver, Reviewer (which generates targeted feedback based on step-wise RM scores), and the Refiner (which incorporates feedback). To ensure sufficient refinement, we re-evaluate updated solutions, iteratively initiating further rounds of refinement. We evaluate MAgICoRe on Llama-3-8B and GPT-3.5 and show its effectiveness across 5 math datasets. Even one iteration of MAgICoRe beats Self-Consistency by 3.4%, Best-of-k by 3.2%, and Self-Refine by 4.0% while using less than half the samples. Unlike iterative refinement with baselines, MAgICoRe continues to improve with more iterations. Finally, our ablations highlight the importance of MAgICoRe's RMs and multi-agent communication.