 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Reasoning Chains Reduce Intrinsic Dimensionality
Feb 09, 2026Chain-of-thought (CoT) reasoning and its variants have substantially improved the performance of language models on complex reasoning tasks, yet the precise mechanisms by which different strategies facilitate generalization remain poorly understood. While current explanations often point to increased test-time computation or structural guidance, establishing a consistent, quantifiable link between these factors and generalization remains challenging. In this work, we identify intrinsic dimensionality as a quantitative measure for characterizing the effectiveness of reasoning chains. Intrinsic dimensionality quantifies the minimum number of model dimensions needed to reach a given accuracy threshold on a given task. By keeping the model architecture fixed and varying the task formulation through different reasoning strategies, we demonstrate that effective reasoning strategies consistently reduce the intrinsic dimensionality of the task. Validating this on GSM8K with Gemma-3 1B and 4B, we observe a strong inverse correlation between the intrinsic dimensionality of a reasoning strategy and its generalization performance on both in-distribution and out-of-distribution data. Our findings suggest that effective reasoning chains facilitate learning by better compressing the task using fewer parameters, offering a new quantitative metric for analyzing reasoning processes.
Conflict-Resolving and Sharpness-Aware Minimization for Generalized Knowledge Editing with Multiple Updates
Feb 03, 2026Large language models (LLMs) rely on internal knowledge to solve many downstream tasks, making it crucial to keep them up to date. Since full retraining is expensive, prior work has explored efficient alternatives such as model editing and parameter-efficient fine-tuning. However, these approaches often break down in practice due to poor generalization across inputs, limited stability, and knowledge conflict. To address these limitations, we propose the CoRSA (Conflict-Resolving and Sharpness-Aware Minimization) training framework, a parameter-efficient, holistic approach for knowledge editing with multiple updates. CoRSA tackles multiple challenges simultaneously: it improves generalization to different input forms and enhances stability across multiple updates by minimizing loss curvature, and resolves conflicts by maximizing the margin between new and prior knowledge. Across three widely used fact editing benchmarks, CoRSA achieves significant gains in generalization, outperforming baselines with average absolute improvements of 12.42% over LoRA and 10% over model editing methods. With multiple updates, it maintains high update efficacy while reducing catastrophic forgetting by 27.82% compared to LoRA. CoRSA also generalizes to the code domain, outperforming the strongest baseline by 5.48% Pass@5 in update efficacy.
Think Right: Learning to Mitigate Under-Over Thinking via Adaptive, Attentive Compression
Oct 02, 2025Recent thinking models solve complex reasoning tasks by scaling test-time compute, but this scaling must be allocated in line with task difficulty. On one hand, short reasoning (underthinking) leads to errors on harder problems that require extended reasoning steps; but, excessively long reasoning (overthinking) can be token-inefficient, generating unnecessary steps even after reaching a correct intermediate solution. We refer to this as under-adaptivity, where the model fails to modulate its response length appropriately given problems of varying difficulty. To address under-adaptivity and strike a balance between under- and overthinking, we propose TRAAC (Think Right with Adaptive, Attentive Compression), an online post-training RL method that leverages the model's self-attention over a long reasoning trajectory to identify important steps and prune redundant ones. TRAAC also estimates difficulty and incorporates it into training rewards, thereby learning to allocate reasoning budget commensurate with example difficulty. Our approach improves accuracy, reduces reasoning steps, and enables adaptive thinking compared to base models and other RL baselines. Across a variety of tasks (AIME, AMC, GPQA-D, BBEH), TRAAC (Qwen3-4B) achieves an average absolute accuracy gain of 8.4% with a relative reduction in reasoning length of 36.8% compared to the base model, and a 7.9% accuracy gain paired with a 29.4% length drop compared to the best RL baseline. TRAAC also shows strong generalization: although our models are trained on math datasets, they show accuracy and efficiency gains on out-of-distribution non-math datasets like GPQA-D, BBEH, and OptimalThinkingBench. Our analysis further verifies that TRAAC provides fine-grained adjustments to thinking budget based on difficulty and that a combination of task-difficulty calibration and attention-based compression yields gains across diverse tasks.
GrAInS: Gradient-based Attribution for Inference-Time Steering of LLMs and VLMs
Jul 24, 2025Inference-time steering methods offer a lightweight alternative to fine-tuning large language models (LLMs) and vision-language models (VLMs) by modifying internal activations at test time without updating model weights. However, most existing approaches rely on fixed, global intervention vectors, overlook the causal influence of individual input tokens, and fail to leverage informative gradients from the model's logits, particularly in multimodal settings where visual and textual inputs contribute unevenly. To address these limitations, we introduce GrAInS, an inference-time steering approach that operates across both language-only and vision-language models and tasks. GrAInS uses contrastive, gradient-based attribution via Integrated Gradients to identify the top-k most influential tokens, both positively and negatively attributed based on their contribution to preferred versus dispreferred outputs. These tokens are then used to construct directional steering vectors that capture semantic shifts from undesirable to desirable behavior. During inference, GrAInS adjusts hidden activations at transformer layers guided by token-level attribution signals, and normalizes activations to preserve representational scale. This enables fine-grained, interpretable, and modular control over model behavior, without retraining or auxiliary supervision. Empirically, GrAInS consistently outperforms both fine-tuning and existing steering baselines: it achieves a 13.22% accuracy gain on TruthfulQA using Llama-3.1-8B, reduces hallucination rates on MMHal-Bench from 0.624 to 0.514 with LLaVA-1.6-7B, and improves alignment win rates on SPA-VL by 8.11%, all while preserving the model's fluency and general capabilities.
Executable Functional Abstractions: Inferring Generative Programs for Advanced Math Problems
Apr 14, 2025Scientists often infer abstract procedures from specific instances of problems and use the abstractions to generate new, related instances. For example, programs encoding the formal rules and properties of a system have been useful in fields ranging from RL (procedural environments) to physics (simulation engines). These programs can be seen as functions which execute to different outputs based on their parameterizations (e.g., gridworld configuration or initial physical conditions). We introduce the term EFA (Executable Functional Abstraction) to denote such programs for math problems. EFA-like constructs have been shown to be useful for math reasoning as problem generators for stress-testing models. However, prior work has been limited to abstractions for grade-school math (whose simple rules are easy to encode in programs), while generating EFAs for advanced math has thus far required human engineering. We explore the automatic construction of EFAs for advanced math problems. We operationalize the task of automatically constructing EFAs as a program synthesis task, and develop EFAGen, which conditions an LLM on a seed math problem and its step-by-step solution to generate candidate EFA programs that are faithful to the generalized problem and solution class underlying the seed problem. Furthermore, we formalize properties any valid EFA must possess in terms of executable unit tests, and show how the tests can be used as verifiable rewards to train LLMs to become better writers of EFAs. We demonstrate that EFAs constructed by EFAGen behave rationally by remaining faithful to seed problems, produce learnable problem variations, and that EFAGen can infer EFAs across multiple diverse sources of competition-level math problems. Finally, we show downstream uses of model-written EFAs e.g. finding problem variations that are harder or easier for a learner to solve, as well as data generation.
Multi-Attribute Steering of Language Models via Targeted Intervention
Feb 18, 2025Inference-time intervention (ITI) has emerged as a promising method for steering large language model (LLM) behavior in a particular direction (e.g., improving helpfulness) by intervening on token representations without costly updates to the LLM's parameters. However, existing ITI approaches fail to scale to multi-attribute settings with conflicts, such as enhancing helpfulness while also reducing toxicity. To address this, we introduce Multi-Attribute Targeted Steering (MAT-Steer), a novel steering framework designed for selective token-level intervention across multiple attributes. MAT-Steer learns steering vectors using an alignment objective that shifts the model's internal representations of undesirable outputs closer to those of desirable ones while enforcing sparsity and orthogonality among vectors for different attributes, thereby reducing inter-attribute conflicts. We evaluate MAT-Steer in two distinct settings: (i) on question answering (QA) tasks where we balance attributes like truthfulness, bias, and toxicity; (ii) on generative tasks where we simultaneously improve attributes like helpfulness, correctness, and coherence. MAT-Steer outperforms existing ITI and parameter-efficient finetuning approaches across both task types (e.g., 3% average accuracy gain across QA tasks and 55.82% win rate against the best ITI baseline).
Learning to Generate Unit Tests for Automated Debugging
Feb 03, 2025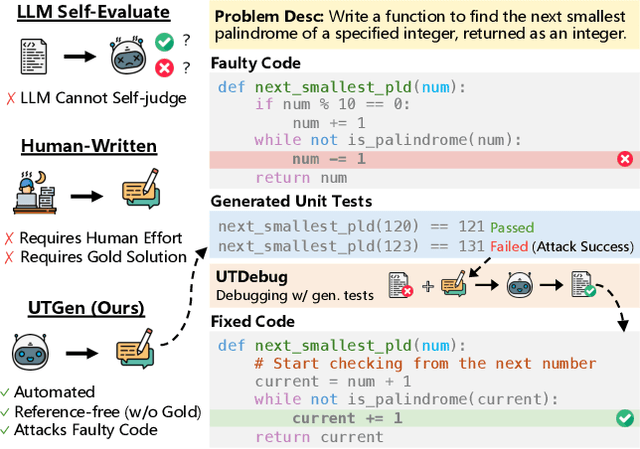

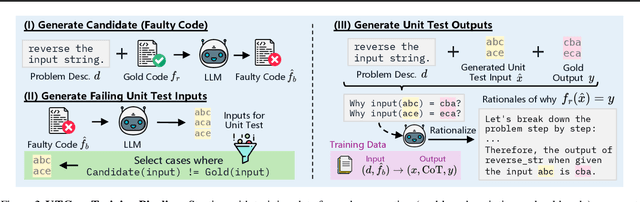

Unit tests (UTs) play an instrumental role in assessing code correctness as well as providing feedback to a large language model (LLM) as it iteratively debugs faulty code, motivating automated test generation. However, we uncover a trade-off between generating unit test inputs that reveal errors when given a faulty code and correctly predicting the unit test output without access to the gold solution. To address this trade-off, we propose UTGen, which teaches LLMs to generate unit test inputs that reveal errors along with their correct expected outputs based on task descriptions and candidate code. We integrate UTGen into UTDebug, a robust debugging pipeline that uses generated tests to help LLMs debug effectively. Since model-generated tests can provide noisy signals (e.g., from incorrectly predicted outputs), UTDebug (i) scales UTGen via test-time compute to improve UT output prediction, and (ii) validates and back-tracks edits based on multiple generated UTs to avoid overfitting. We show that UTGen outperforms UT generation baselines by 7.59% based on a metric measuring the presence of both error-revealing UT inputs and correct UT outputs. When used with UTDebug, we find that feedback from UTGen's unit tests improves pass@1 accuracy of Qwen-2.5 7B on HumanEvalFix and our own harder debugging split of MBPP+ by over 3% and 12.35% (respectively) over other LLM-based UT generation baselines.
Self-Consistency Preference Optimization
Nov 06, 2024



Self-alignment, whereby models learn to improve themselves without human annotation, is a rapidly growing research area. However, existing techniques often fail to improve complex reasoning tasks due to the difficulty of assigning correct rewards. An orthogonal approach that is known to improve correctness is self-consistency, a method applied at inference time based on multiple sampling in order to find the most consistent answer. In this work, we extend the self-consistency concept to help train models. We thus introduce self-consistency preference optimization (ScPO), which iteratively trains consistent answers to be preferred over inconsistent ones on unsupervised new problems. We show ScPO leads to large improvements over conventional reward model training on reasoning tasks such as GSM8K and MATH, closing the gap with supervised training with gold answers or preferences, and that combining ScPO with standard supervised learning improves results even further. On ZebraLogic, ScPO finetunes Llama-3 8B to be superior to Llama-3 70B, Gemma-2 27B, and Claude-3 Haiku.
LASeR: Learning to Adaptively Select Reward Models with Multi-Armed Bandits
Oct 02, 2024Reward Models (RMs) play a crucial role in aligning LLMs with human preferences, enhancing their performance by ranking outputs during inference or iterative training. However, the degree to which an RM generalizes to new tasks is often not known a priori (e.g. some RMs may excel at scoring creative writing vs. math reasoning). Therefore, using only one fixed RM while training LLMs can be suboptimal. Moreover, optimizing LLMs with multiple RMs simultaneously can be prohibitively computationally-intensive and challenging due to conflicting signals from different RMs, potentially degrading performance. To address these challenges, we introduce LASeR (Learning to Adaptively Select Rewards), which iteratively trains LLMs using multiple RMs, selecting and utilizing the most well-suited RM for each instance to rank outputs and generate preference data, framed as a multi-armed bandit problem. Our results on commonsense and math reasoning tasks demonstrate that LASeR can boost iterative LLM optimization by optimizing for multiple RMs, improving the absolute average accuracy of Llama-3-8B over three datasets by 2.67% over training with ensemble RM scores while also showing superior training efficiency (e.g., a 2x speedup). Moreover, on WildChat, a benchmark of instruction-following prompts, we find that using Llama-3-8B LASeR leads to a 71.45% AlpacaEval win rate over sequentially optimizing multiple RMs. Extending to long-context generation tasks, we find that on Llama-3-8B, LASeR achieves an average improvement of 2.64 F1 and 2.42 F1 on single- and multi-document QA over random RM selection when used with best-of-n sampling. LASeR is robust to noisy rewards and generalizes to multiple settings. Finally, LASeR's RM selection changes depending on the underlying task or instance and we verify the presence of conflicting preferences from multiple RMs that can be mitigated using LASeR.
MAgICoRe: Multi-Agent, Iterative, Coarse-to-Fine Refinement for Reasoning
Sep 18, 2024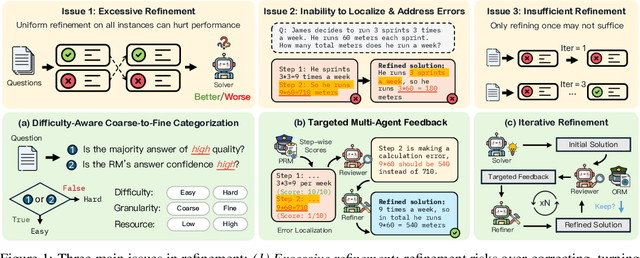
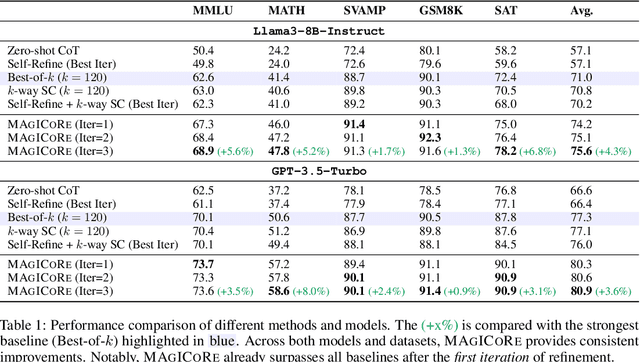
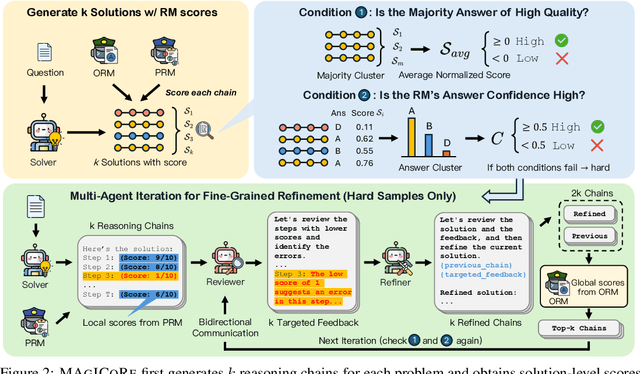
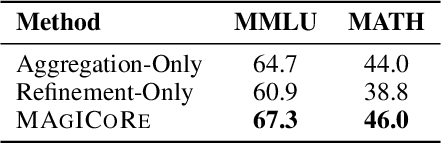
Large Language Models' (LLM) reasoning can be improved using test-time aggregation strategies, i.e., generating multiple samples and voting among generated samples. While these improve performance, they often reach a saturation point. Refinement offers an alternative by using LLM-generated feedback to improve solution quality. However, refinement introduces 3 key challenges: (1) Excessive refinement: Uniformly refining all instances can over-correct and reduce the overall performance. (2) Inability to localize and address errors: LLMs have a limited ability to self-correct and struggle to identify and correct their own mistakes. (3) Insufficient refinement: Deciding how many iterations of refinement are needed is non-trivial, and stopping too soon could leave errors unaddressed. To tackle these issues, we propose MAgICoRe, which avoids excessive refinement by categorizing problem difficulty as easy or hard, solving easy problems with coarse-grained aggregation and hard ones with fine-grained and iterative multi-agent refinement. To improve error localization, we incorporate external step-wise reward model (RM) scores. Moreover, to ensure effective refinement, we employ a multi-agent loop with three agents: Solver, Reviewer (which generates targeted feedback based on step-wise RM scores), and the Refiner (which incorporates feedback). To ensure sufficient refinement, we re-evaluate updated solutions, iteratively initiating further rounds of refinement. We evaluate MAgICoRe on Llama-3-8B and GPT-3.5 and show its effectiveness across 5 math datasets. Even one iteration of MAgICoRe beats Self-Consistency by 3.4%, Best-of-k by 3.2%, and Self-Refine by 4.0% while using less than half the samples. Unlike iterative refinement with baselines, MAgICoRe continues to improve with more iterations. Finally, our ablations highlight the importance of MAgICoRe's RMs and multi-agent communication.