 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improving Pretraining: using post-trained models to pretrain better models
Jan 29, 2026Ensuring safety, factuality and overall quality in the generations of large language models is a critical challenge, especially as these models are increasingly deployed in real-world applications. The prevailing approach to addressing these issues involves collecting expensive, carefully curated datasets and applying multiple stages of fine-tuning and alignment. However, even this complex pipeline cannot guarantee the correction of patterns learned during pretraining. Therefore, addressing these issues during pretraining is crucial, as it shapes a model's core behaviors and prevents unsafe or hallucinated outputs from becoming deeply embedded. To tackle this issue, we introduce a new pretraining method that streams documents and uses reinforcement learning (RL) to improve the next K generated tokens at each step. A strong, post-trained model judges candidate generations -- including model rollouts, the original suffix, and a rewritten suffix -- for quality, safety, and factuality. Early in training, the process relies on the original and rewritten suffixes; as the model improves, RL rewards high-quality rollouts. This approach builds higher quality, safer, and more factual models from the ground up. In experiments, our method gives 36.2% and 18.5% relative improvements over standard pretraining in terms of factuality and safety, and up to 86.3% win rate improvements in overall generation quality.
Stochastic activations
Sep 26, 2025We introduce stochastic activations. This novel strategy randomly selects between several non-linear functions in the feed-forward layer of a large language model. In particular, we choose between SILU or RELU depending on a Bernoulli draw. This strategy circumvents the optimization problem associated with RELU, namely, the constant shape for negative inputs that prevents the gradient flow. We leverage this strategy in two ways: (1) We use stochastic activations during pre-training and fine-tune the model with RELU, which is used at inference time to provide sparse latent vectors. This reduces the inference FLOPs and translates into a significant speedup in the CPU. Interestingly, this leads to much better results than training from scratch with the RELU activation function. (2) We evaluate stochastic activations for generation. This strategy performs reasonably well: it is only slightly inferior to the best deterministic non-linearity, namely SILU combined with temperature scaling. This offers an alternative to existing strategies by providing a controlled way to increase the diversity of the generated text.
StepWiser: Stepwise Generative Judges for Wiser Reasoning
Aug 27, 2025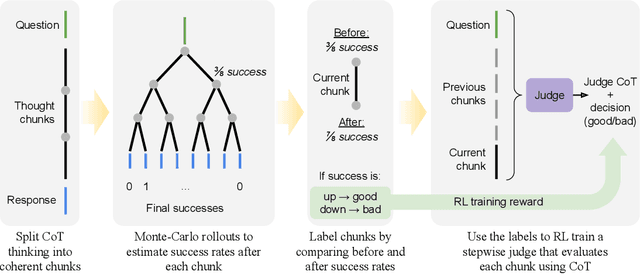


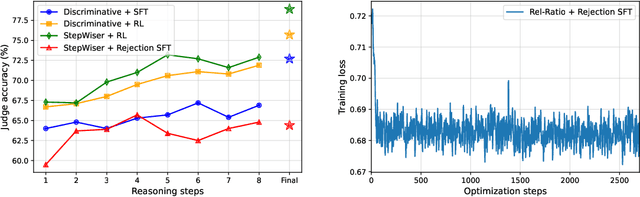
As models increasingly leverage multi-step reasoning strategies to solve complex problems, supervising the logical validity of these intermediate steps has become a critical research challenge. Process reward models address this by providing step-by-step feedback, but current approaches have two major drawbacks: they typically function as classifiers without providing explanations, and their reliance on supervised fine-tuning with static datasets limits generalization. Inspired by recent advances, we reframe stepwise reward modeling from a classification task to a reasoning task itself. We thus propose a generative judge that reasons about the policy model's reasoning steps (i.e., meta-reasons), outputting thinking tokens before delivering a final verdict. Our model, StepWiser, is trained by reinforcement learning using relative outcomes of rollouts. We show it provides (i) better judgment accuracy on intermediate steps than existing methods; (ii) can be used to improve the policy model at training time; and (iii) improves inference-time search.
CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks
Jul 31, 2025We propose CoT-Self-Instruct, a synthetic data generation method that instructs LLMs to first reason and plan via Chain-of-Thought (CoT) based on the given seed tasks, and then to generate a new synthetic prompt of similar quality and complexity for use in LLM training, followed by filtering for high-quality data with automatic metrics. In verifiable reasoning, our synthetic data significantly outperforms existing training datasets, such as s1k and OpenMathReasoning, across MATH500, AMC23, AIME24 and GPQA-Diamond. For non-verifiable instruction-following tasks, our method surpasses the performance of human or standard self-instruct prompts on both AlpacaEval 2.0 and Arena-Hard.
Bridging Offline and Online Reinforcement Learning for LLMs
Jun 26, 2025We investigate the effectiveness of reinforcement learning methods for finetuning large language models when transitioning from offline to semi-online to fully online regimes for both verifiable and non-verifiable tasks. Our experiments cover training on verifiable math as well as non-verifiable instruction following with a set of benchmark evaluations for both. Across these settings, we extensively compare online and semi-online Direct Preference Optimization and Group Reward Policy Optimization objectives, and surprisingly find similar performance and convergence between these variants, which all strongly outperform offline methods. We provide a detailed analysis of the training dynamics and hyperparameter selection strategies to achieve optimal results. Finally, we show that multi-tasking with verifiable and non-verifiable rewards jointly yields improved performance across both task types.
Multi-Token Attention
Apr 01, 2025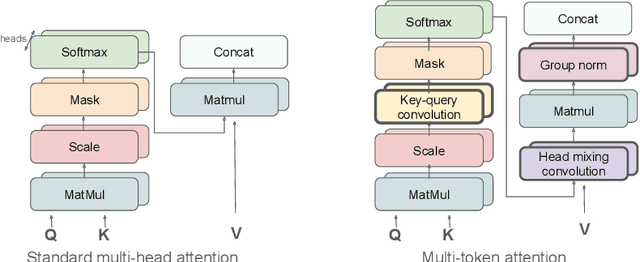

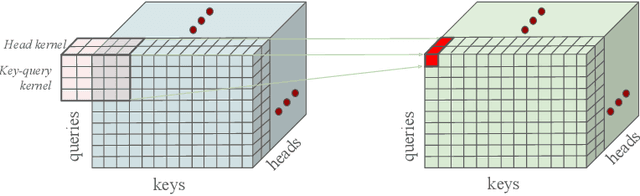
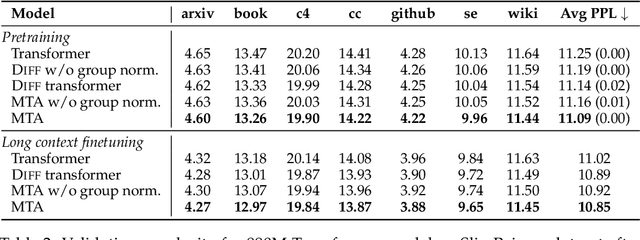
Soft attention is a critical mechanism powering LLMs to locate relevant parts within a given context. However, individual attention weights are determined by the similarity of only a single query and key token vector. This "single token attention" bottlenecks the amount of information used in distinguishing a relevant part from the rest of the context. To address this issue, we propose a new attention method, Multi-Token Attention (MTA), which allows LLMs to condition their attention weights on multiple query and key vectors simultaneously. This is achieved by applying convolution operations over queries, keys and heads, allowing nearby queries and keys to affect each other's attention weights for more precise attention. As a result, our method can locate relevant context using richer, more nuanced information that can exceed a single vector's capacity. Through extensive evaluations, we demonstrate that MTA achieves enhanced performance on a range of popular benchmarks. Notably, it outperforms Transformer baseline models on standard language modeling tasks, and on tasks that require searching for information within long contexts, where our method's ability to leverage richer information proves particularly beneficial.
SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
Mar 19, 2025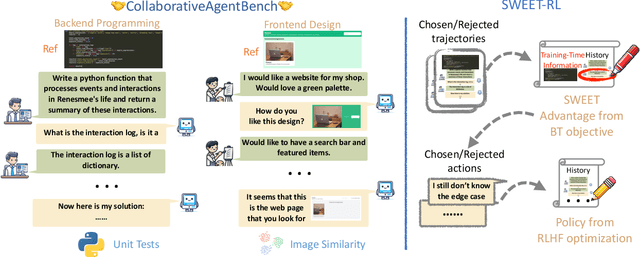
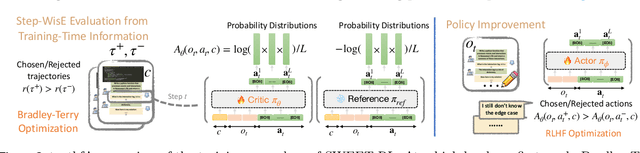
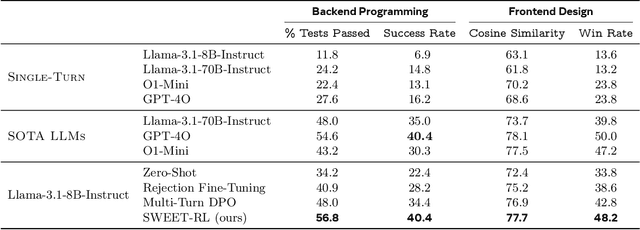
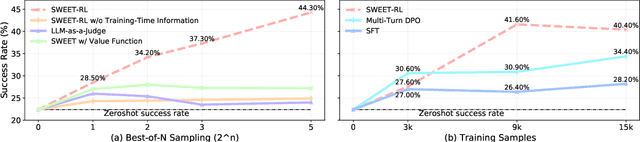
Large language model (LLM) agents need to perform multi-turn interactions in real-world tasks. However, existing multi-turn RL algorithms for optimizing LLM agents fail to perform effective credit assignment over multiple turns while leveraging the generalization capabilities of LLMs and it remains unclear how to develop such algorithms. To study this, we first introduce a new benchmark, ColBench, where an LLM agent interacts with a human collaborator over multiple turns to solve realistic tasks in backend programming and frontend design. Building on this benchmark, we propose a novel RL algorithm, SWEET-RL (RL with Step-WisE Evaluation from Training-time information), that uses a carefully designed optimization objective to train a critic model with access to additional training-time information. The critic provides step-level rewards for improving the policy model. Our experiments demonstrate that SWEET-RL achieves a 6% absolute improvement in success and win rates on ColBench compared to other state-of-the-art multi-turn RL algorithms, enabling Llama-3.1-8B to match or exceed the performance of GPT4-o in realistic collaborative content creation.
Diverse Preference Optimization
Jan 31, 2025



Post-training of language models, either through reinforcement learning, preference optimization or supervised finetuning, tends to sharpen the output probability distribution and reduce the diversity of generated responses. This is particularly a problem for creative generative tasks where varied responses are desired. In this work we introduce Diverse Preference Optimization (DivPO), an optimization method which learns to generate much more diverse responses than standard pipelines, while maintaining the quality of the generations. In DivPO, preference pairs are selected by first considering a pool of responses, and a measure of diversity among them, and selecting chosen examples as being more rare but high quality, while rejected examples are more common, but low quality. DivPO results in generating 45.6% more diverse persona attributes, and an 74.6% increase in story diversity, while maintaining similar win rates as standard baselines.
R.I.P.: Better Models by Survival of the Fittest Prompts
Jan 30, 2025



Training data quality is one of the most important drivers of final model quality. In this work, we introduce a method for evaluating data integrity based on the assumption that low-quality input prompts result in high variance and low quality responses. This is achieved by measuring the rejected response quality and the reward gap between the chosen and rejected preference pair. Our method, Rejecting Instruction Preferences (RIP) can be used to filter prompts from existing training sets, or to make high quality synthetic datasets, yielding large performance gains across various benchmarks compared to unfiltered data. Using Llama 3.1-8B-Instruct, RIP improves AlpacaEval2 LC Win Rate by 9.4%, Arena-Hard by 8.7%, and WildBench by 9.9%. Using Llama 3.3-70B-Instruct, RIP improves Arena-Hard from 67.5 to 82.9, which is from 18th place to 6th overall in the leaderboard.
Step-KTO: Optimizing Mathematical Reasoning through Stepwise Binary Feedback
Jan 18, 2025Large language models (LLMs) have recently demonstrated remarkable success in mathematical reasoning. Despite progress in methods like chain-of-thought prompting and self-consistency sampling, these advances often focus on final correctness without ensuring that the underlying reasoning process is coherent and reliable. This paper introduces Step-KTO, a training framework that combines process-level and outcome-level binary feedback to guide LLMs toward more trustworthy reasoning trajectories. By providing binary evaluations for both the intermediate reasoning steps and the final answer, Step-KTO encourages the model to adhere to logical progressions rather than relying on superficial shortcuts. Our experiments on challenging mathematical benchmarks show that Step-KTO significantly improves both final answer accuracy and the quality of intermediate reasoning steps. For example, on the MATH-500 dataset, Step-KTO achieves a notable improvement in Pass@1 accuracy over strong baselines. These results highlight the promise of integrating stepwise process feedback into LLM training, paving the way toward more interpretable and dependable reasoning capabilities.