 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Path Not Taken: RLVR Provably Learns Off the Principals
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) reliably improves the reasoning performance of large language models, yet it appears to modify only a small fraction of parameters. We revisit this paradox and show that sparsity is a surface artifact of a model-conditioned optimization bias: for a fixed pretrained model, updates consistently localize to preferred parameter regions, highly consistent across runs and largely invariant to datasets and RL recipes. We mechanistically explain these dynamics with a Three-Gate Theory: Gate I (KL Anchor) imposes a KL-constrained update; Gate II (Model Geometry) steers the step off principal directions into low-curvature, spectrum-preserving subspaces; and Gate III (Precision) hides micro-updates in non-preferred regions, making the off-principal bias appear as sparsity. We then validate this theory and, for the first time, provide a parameter-level characterization of RLVR's learning dynamics: RLVR learns off principal directions in weight space, achieving gains via minimal spectral drift, reduced principal-subspace rotation, and off-principal update alignment. In contrast, SFT targets principal weights, distorts the spectrum, and even lags RLVR. Together, these results provide the first parameter-space account of RLVR's training dynamics, revealing clear regularities in how parameters evolve. Crucially, we show that RL operates in a distinct optimization regime from SFT, so directly adapting SFT-era parameter-efficient fine-tuning (PEFT) methods can be flawed, as evidenced by our case studies on advanced sparse fine-tuning and LoRA variants. We hope this work charts a path toward a white-box understanding of RLVR and the design of geometry-aware, RLVR-native learning algorithms, rather than repurposed SFT-era heuristics.
SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models
Oct 10, 2025Diffusion large language models (dLLMs) are emerging as an efficient alternative to autoregressive models due to their ability to decode multiple tokens in parallel. However, aligning dLLMs with human preferences or task-specific rewards via reinforcement learning (RL) is challenging because their intractable log-likelihood precludes the direct application of standard policy gradient methods. While prior work uses surrogates like the evidence lower bound (ELBO), these one-sided approximations can introduce significant policy gradient bias. To address this, we propose the Sandwiched Policy Gradient (SPG) that leverages both an upper and a lower bound of the true log-likelihood. Experiments show that SPG significantly outperforms baselines based on ELBO or one-step estimation. Specifically, SPG improves the accuracy over state-of-the-art RL methods for dLLMs by 3.6% in GSM8K, 2.6% in MATH500, 18.4% in Countdown and 27.0% in Sudoku.
GaLore 2: Large-Scale LLM Pre-Training by Gradient Low-Rank Projection
Apr 29, 2025



Large language models (LLMs) have revolutionized natural language understanding and generation but face significant memory bottlenecks during training. GaLore, Gradient Low-Rank Projection, addresses this issue by leveraging the inherent low-rank structure of weight gradients, enabling substantial memory savings without sacrificing performance. Recent works further extend GaLore from various aspects, including low-bit quantization and higher-order tensor structures. However, there are several remaining challenges for GaLore, such as the computational overhead of SVD for subspace updates and the integration with state-of-the-art training parallelization strategies (e.g., FSDP). In this paper, we present GaLore 2, an efficient and scalable GaLore framework that addresses these challenges and incorporates recent advancements. In addition, we demonstrate the scalability of GaLore 2 by pre-training Llama 7B from scratch using up to 500 billion training tokens, highlighting its potential impact on real LLM pre-training scenarios.
Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning
Feb 05, 2025



Large Language Models (LLMs) excel at reasoning and planning when trained on chainof-thought (CoT) data, where the step-by-step thought process is explicitly outlined by text tokens. However, this results in lengthy inputs where many words support textual coherence rather than core reasoning information, and processing these inputs consumes substantial computation resources. In this work, we propose a hybrid representation of the reasoning process, where we partially abstract away the initial reasoning steps using latent discrete tokens generated by VQ-VAE, significantly reducing the length of reasoning traces. We explore the use of latent trace abstractions in two scenarios: 1) training the model from scratch for the Keys-Finding Maze problem, 2) fine-tuning LLMs on this hybrid data with an extended vocabulary including unseen latent tokens, for both logical and mathematical reasoning problems. To facilitate effective learning, we introduce a simple training procedure that randomly mixes latent and text tokens, which enables fast adaptation to new latent tokens. Our approach consistently outperforms the baselines methods in various benchmarks.
Training Large Language Models to Reason in a Continuous Latent Space
Dec 09, 2024



Large language models (LLMs) are restricted to reason in the "language space", where they typically express the reasoning process with a chain-of-thought (CoT) to solve a complex reasoning problem. However, we argue that language space may not always be optimal for reasoning. For example, most word tokens are primarily for textual coherence and not essential for reasoning, while some critical tokens require complex planning and pose huge challenges to LLMs. To explore the potential of LLM reasoning in an unrestricted latent space instead of using natural language, we introduce a new paradigm Coconut (Chain of Continuous Thought). We utilize the last hidden state of the LLM as a representation of the reasoning state (termed "continuous thought"). Rather than decoding this into a word token, we feed it back to the LLM as the subsequent input embedding directly in the continuous space. Experiments show that Coconut can effectively augment the LLM on several reasoning tasks. This novel latent reasoning paradigm leads to emergent advanced reasoning patterns: the continuous thought can encode multiple alternative next reasoning steps, allowing the model to perform a breadth-first search (BFS) to solve the problem, rather than prematurely committing to a single deterministic path like CoT. Coconut outperforms CoT in certain logical reasoning tasks that require substantial backtracking during planning, with fewer thinking tokens during inference. These findings demonstrate the promise of latent reasoning and offer valuable insights for future research.
Dualformer: Controllable Fast and Slow Thinking by Learning with Randomized Reasoning Traces
Oct 13, 2024In human cognition theory, human thinking is governed by two systems: the fast and intuitive System 1 and the slower but more deliberative System 2. Recent studies have shown that incorporating System 2 process into Transformers including large language models (LLMs), significantly enhances their reasoning capabilities. Nevertheless, models that purely resemble System 2 thinking require substantially higher computational costs and are much slower to respond. To address this challenge, we present Dualformer, a single Transformer model that seamlessly integrates both the fast and slow reasoning modes. Dualformer is obtained by training on data with randomized reasoning traces, where different parts of the traces are dropped during training. The dropping strategies are specifically tailored according to the trace structure, analogous to analyzing our thinking process and creating shortcuts with patterns. At inference time, our model can be configured to output only the solutions (fast mode) or both the reasoning chain and the final solution (slow mode), or automatically decide which mode to engage (auto mode). In all cases, Dualformer outperforms the corresponding baseline models in both performance and computational efficiency: (1) in slow mode, Dualformer optimally solves unseen 30 x 30 maze navigation tasks 97.6% of the time, surpassing the Searchformer (trained on data with complete reasoning traces) baseline performance of 93.3%, while only using 45.5% fewer reasoning steps; (2) in fast mode, Dualformer completes those tasks with an 80% optimal rate, significantly outperforming the Solution-Only model (trained on solution-only data), which has an optimal rate of only 30%. For math problems, our techniques have also achieved improved performance with LLM fine-tuning, showing its generalization beyond task-specific models.
Narrowing the Coordinate-frame Gap in Behavior Prediction Models: Distillation for Efficient and Accurate Scene-centric Motion Forecasting
Jun 10, 2022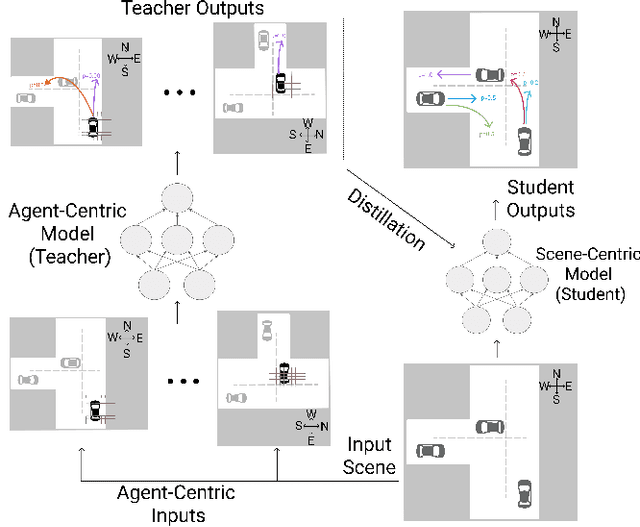
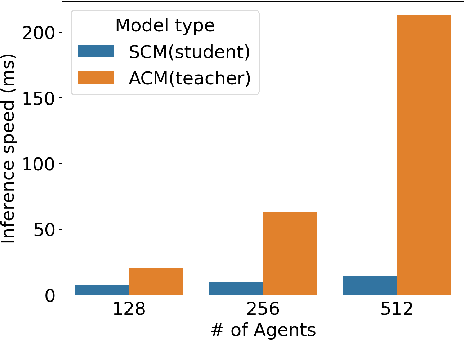
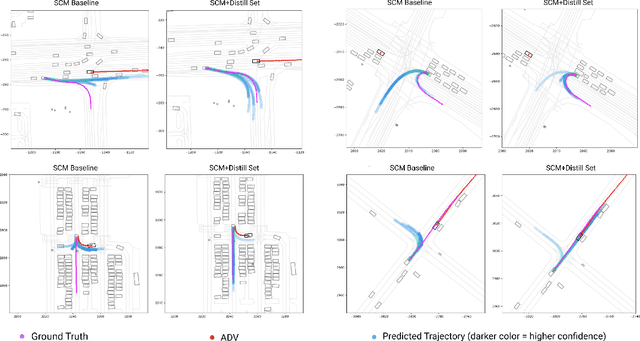
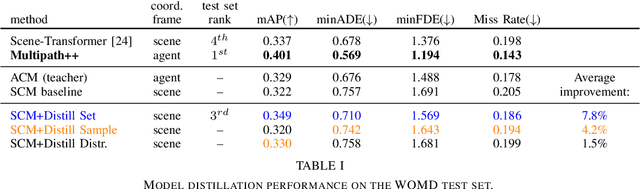
Behavior prediction models have proliferated in recent years, especially in the popular real-world robotics application of autonomous driving, where representing the distribution over possible futures of moving agents is essential for safe and comfortable motion planning. In these models, the choice of coordinate frames to represent inputs and outputs has crucial trade offs which broadly fall into one of two categories. Agent-centric models transform inputs and perform inference in agent-centric coordinates. These models are intrinsically invariant to translation and rotation between scene elements, are best-performing on public leaderboards, but scale quadratically with the number of agents and scene elements. Scene-centric models use a fixed coordinate system to process all agents. This gives them the advantage of sharing representations among all agents, offering efficient amortized inference computation which scales linearly with the number of agents. However, these models have to learn invariance to translation and rotation between scene elements, and typically underperform agent-centric models. In this work, we develop knowledge distillation techniques between probabilistic motion forecasting models, and apply these techniques to close the gap in performance between agent-centric and scene-centric models. This improves scene-centric model performance by 13.2% on the public Argoverse benchmark, 7.8% on Waymo Open Dataset and up to 9.4% on a large In-House dataset. These improved scene-centric models rank highly in public leaderboards and are up to 15 times more efficient than their agent-centric teacher counterparts in busy scenes.
MUSBO: Model-based Uncertainty Regularized and Sample Efficient Batch Optimization for Deployment Constrained Reinforcement Learning
Feb 23, 2021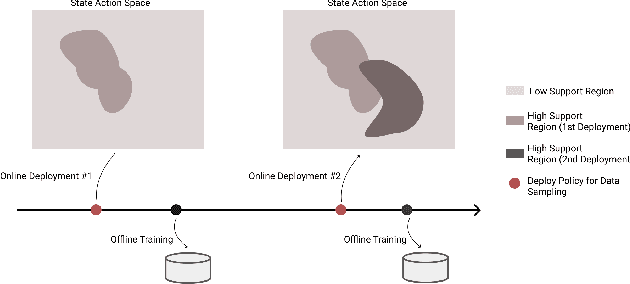
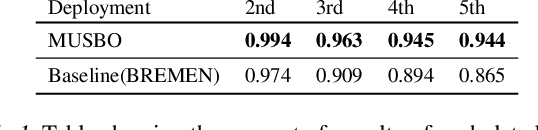


In many contemporary applications such as healthcare, finance, robotics, and recommendation systems, continuous deployment of new policies for data collection and online learning is either cost ineffective or impractical. We consider a setting that lies between pure offline reinforcement learning (RL) and pure online RL called deployment constrained RL in which the number of policy deployments for data sampling is limited. To solve this challenging task, we propose a new algorithmic learning framework called Model-based Uncertainty regularized and Sample Efficient Batch Optimization (MUSBO). Our framework discovers novel and high quality samples for each deployment to enable efficient data collection. During each offline training session, we bootstrap the policy update by quantifying the amount of uncertainty within our collected data. In the high support region (low uncertainty), we encourage our policy by taking an aggressive update. In the low support region (high uncertainty) when the policy bootstraps into the out-of-distribution region, we downweight it by our estimated uncertainty quantification. Experimental results show that MUSBO achieves state-of-the-art performance in the deployment constrained RL setting.