 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoBRL: Optimizing Multi-Document Summarization by Blending Reinforcement Learning Policies
May 18, 2021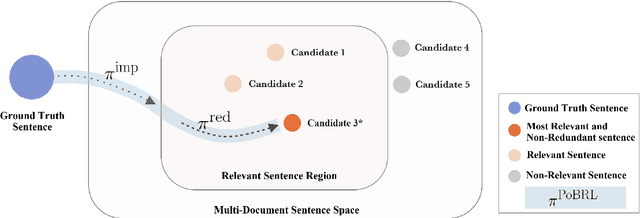
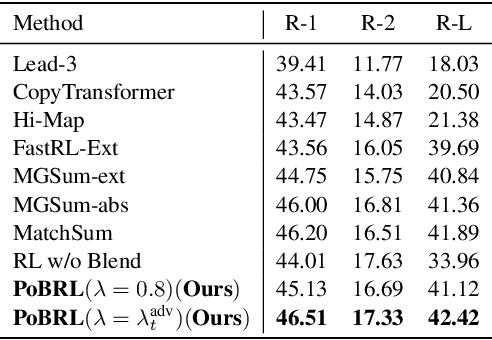
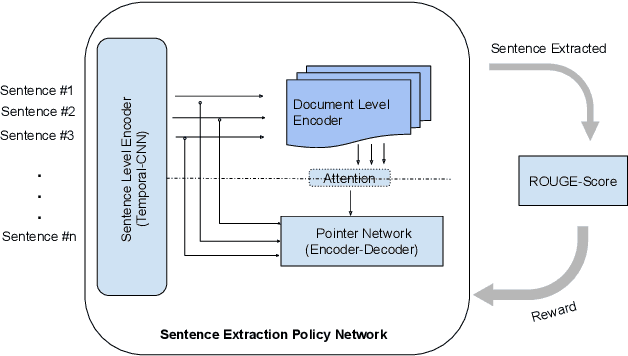

We propose a novel reinforcement learning based framework PoBRL for solving multi-document summarization. PoBRL jointly optimizes over the following three objectives necessary for a high-quality summary: importance, relevance, and length. Our strategy decouples this multi-objective optimization into different subproblems that can be solved individually by reinforcement learning. Utilizing PoBRL, we then blend each learned policies together to produce a summary that is a concise and complete representation of the original input. Our empirical analysis shows state-of-the-art performance on several multi-document datasets. Human evaluation also shows that our method produces high-quality output.
MUSBO: Model-based Uncertainty Regularized and Sample Efficient Batch Optimization for Deployment Constrained Reinforcement Learning
Feb 23, 2021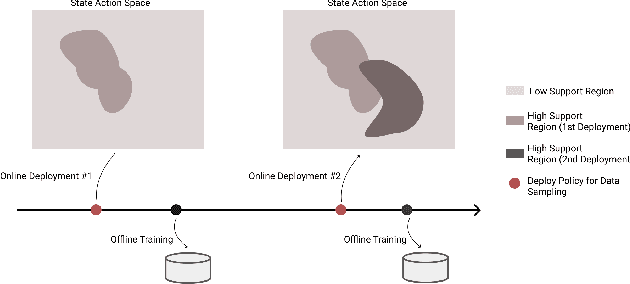
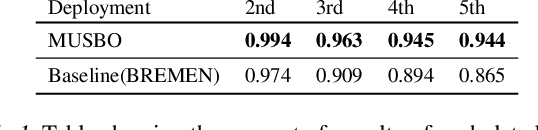


In many contemporary applications such as healthcare, finance, robotics, and recommendation systems, continuous deployment of new policies for data collection and online learning is either cost ineffective or impractical. We consider a setting that lies between pure offline reinforcement learning (RL) and pure online RL called deployment constrained RL in which the number of policy deployments for data sampling is limited. To solve this challenging task, we propose a new algorithmic learning framework called Model-based Uncertainty regularized and Sample Efficient Batch Optimization (MUSBO). Our framework discovers novel and high quality samples for each deployment to enable efficient data collection. During each offline training session, we bootstrap the policy update by quantifying the amount of uncertainty within our collected data. In the high support region (low uncertainty), we encourage our policy by taking an aggressive update. In the low support region (high uncertainty) when the policy bootstraps into the out-of-distribution region, we downweight it by our estimated uncertainty quantification. Experimental results show that MUSBO achieves state-of-the-art performance in the deployment constrained RL setting.