 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedTRPO: Trajectory Reduction in Policy Optimization of Diffusion Large Language Models
Mar 19, 2026Diffusion Large Language Models (dLLMs) introduce a new paradigm for language generation, which in turn presents new challenges for aligning them with human preferences. In this work, we aim to improve the policy optimization for dLLMs by reducing the cost of the trajectory probability calculation, thereby enabling scaled-up offline policy training. We prove that: (i) under reference policy regularization, the probability ratio of the newly unmasked tokens is an unbiased estimate of that of intermediate diffusion states, and (ii) the probability of the full trajectory can be effectively estimated with a single forward pass of a re-masked final state. By integrating these two trajectory reduction strategies into a policy optimization objective, we propose Trajectory Reduction Policy Optimization (dTRPO). We evaluate dTRPO on 7B dLLMs across instruction-following and reasoning benchmarks. Results show that it substantially improves the core performance of state-of-the-art dLLMs, achieving gains of up to 9.6% on STEM tasks, up to 4.3% on coding tasks, and up to 3.0% on instruction-following tasks. Moreover, dTRPO exhibits strong training efficiency due to its offline, single-forward nature, and achieves improved generation efficiency through high-quality outputs.
PoBRL: Optimizing Multi-Document Summarization by Blending Reinforcement Learning Policies
May 18, 2021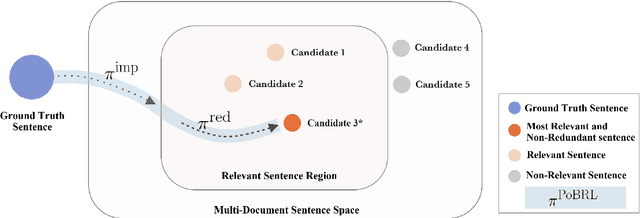
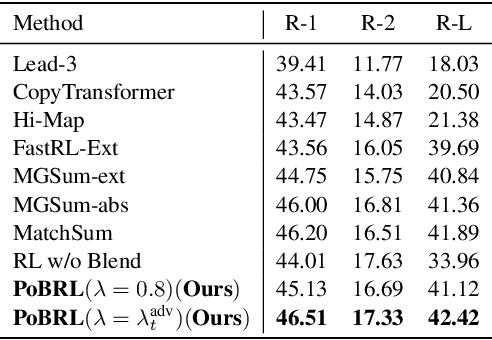
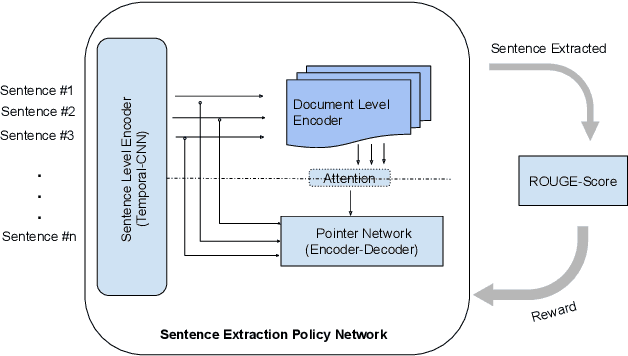

We propose a novel reinforcement learning based framework PoBRL for solving multi-document summarization. PoBRL jointly optimizes over the following three objectives necessary for a high-quality summary: importance, relevance, and length. Our strategy decouples this multi-objective optimization into different subproblems that can be solved individually by reinforcement learning. Utilizing PoBRL, we then blend each learned policies together to produce a summary that is a concise and complete representation of the original input. Our empirical analysis shows state-of-the-art performance on several multi-document datasets. Human evaluation also shows that our method produces high-quality output.
ConQUR: Mitigating Delusional Bias in Deep Q-learning
Feb 27, 2020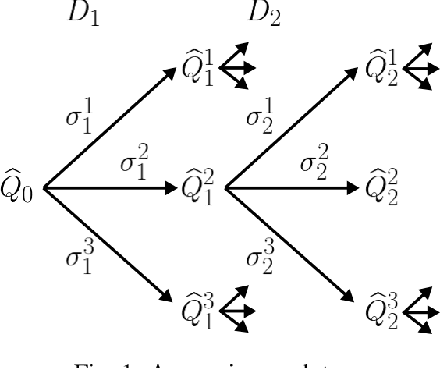
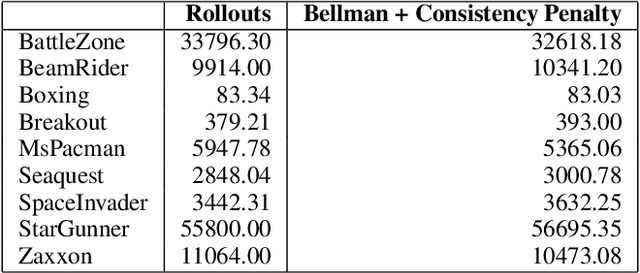

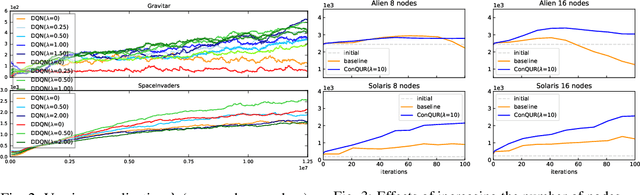
Delusional bias is a fundamental source of error in approximate Q-learning. To date, the only techniques that explicitly address delusion require comprehensive search using tabular value estimates. In this paper, we develop efficient methods to mitigate delusional bias by training Q-approximators with labels that are "consistent" with the underlying greedy policy class. We introduce a simple penalization scheme that encourages Q-labels used across training batches to remain (jointly) consistent with the expressible policy class. We also propose a search framework that allows multiple Q-approximators to be generated and tracked, thus mitigating the effect of premature (implicit) policy commitments. Experimental results demonstrate that these methods can improve the performance of Q-learning in a variety of Atari games, sometimes dramatically.