 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Ghost in Representation Learning: from Component Analysis to Self-Supervised Learning
Jan 28, 2026Self-supervised learning (SSL) have improved empirical performance by unleashing the power of unlabeled data for practical applications. Specifically, SSL extracts the representation from massive unlabeled data, which will be transferred to a plenty of down streaming tasks with limited data. The significant improvement on diverse applications of representation learning has attracted increasing attention, resulting in a variety of dramatically different self-supervised learning objectives for representation extraction, with an assortment of learning procedures, but the lack of a clear and unified understanding. Such an absence hampers the ongoing development of representation learning, leaving a theoretical understanding missing, principles for efficient algorithm design unclear, and the use of representation learning methods in practice unjustified. The urgency for a unified framework is further motivated by the rapid growth in representation learning methods. In this paper, we are therefore compelled to develop a principled foundation of representation learning. We first theoretically investigate the sufficiency of the representation from a spectral representation view, which reveals the spectral essence of the existing successful SSL algorithms and paves the path to a unified framework for understanding and analysis. Such a framework work also inspires the development of more efficient and easy-to-use representation learning algorithms with principled way in real-world applications.
Universal computation is intrinsic to language model decoding
Jan 12, 2026Language models now provide an interface to express and often solve general problems in natural language, yet their ultimate computational capabilities remain a major topic of scientific debate. Unlike a formal computer, a language model is trained to autoregressively predict successive elements in human-generated text. We prove that chaining a language model's autoregressive output is sufficient to perform universal computation. That is, a language model can simulate the execution of any algorithm on any input. The challenge of eliciting desired computational behaviour can thus be reframed in terms of programmability: the ease of finding a suitable prompt. Strikingly, we demonstrate that even randomly initialized language models are capable of universal computation before training. This implies that training does not give rise to computational expressiveness -- rather, it improves programmability, enabling a natural language interface for accessing these intrinsic capabilities.
The World Is Bigger! A Computationally-Embedded Perspective on the Big World Hypothesis
Dec 29, 2025Continual learning is often motivated by the idea, known as the big world hypothesis, that "the world is bigger" than the agent. Recent problem formulations capture this idea by explicitly constraining an agent relative to the environment. These constraints lead to solutions in which the agent continually adapts to best use its limited capacity, rather than converging to a fixed solution. However, explicit constraints can be ad hoc, difficult to incorporate, and may limit the effectiveness of scaling up the agent's capacity. In this paper, we characterize a problem setting in which an agent, regardless of its capacity, is constrained by being embedded in the environment. In particular, we introduce a computationally-embedded perspective that represents an embedded agent as an automaton simulated within a universal (formal) computer. Such an automaton is always constrained; we prove that it is equivalent to an agent that interacts with a partially observable Markov decision process over a countably infinite state-space. We propose an objective for this setting, which we call interactivity, that measures an agent's ability to continually adapt its behaviour by learning new predictions. We then develop a model-based reinforcement learning algorithm for interactivity-seeking, and use it to construct a synthetic problem to evaluate continual learning capability. Our results show that deep nonlinear networks struggle to sustain interactivity, whereas deep linear networks sustain higher interactivity as capacity increases.
Spectral Representation-based Reinforcement Learning
Dec 17, 2025In real-world applications with large state and action spaces, reinforcement learning (RL) typically employs function approximations to represent core components like the policies, value functions, and dynamics models. Although powerful approximations such as neural networks offer great expressiveness, they often present theoretical ambiguities, suffer from optimization instability and exploration difficulty, and incur substantial computational costs in practice. In this paper, we introduce the perspective of spectral representations as a solution to address these difficulties in RL. Stemming from the spectral decomposition of the transition operator, this framework yields an effective abstraction of the system dynamics for subsequent policy optimization while also providing a clear theoretical characterization. We reveal how to construct spectral representations for transition operators that possess latent variable structures or energy-based structures, which implies different learning methods to extract spectral representations from data. Notably, each of these learning methods realizes an effective RL algorithm under this framework. We also provably extend this spectral view to partially observable MDPs. Finally, we validate these algorithms on over 20 challenging tasks from the DeepMind Control Suite, where they achieve performances comparable or superior to current state-of-the-art model-free and model-based baselines.
Rethinking the Global Convergence of Softmax Policy Gradient with Linear Function Approximation
May 06, 2025Policy gradient (PG) methods have played an essential role in the empirical successes of reinforcement learning. In order to handle large state-action spaces, PG methods are typically used with function approximation. In this setting, the approximation error in modeling problem-dependent quantities is a key notion for characterizing the global convergence of PG methods. We focus on Softmax PG with linear function approximation (referred to as $\texttt{Lin-SPG}$) and demonstrate that the approximation error is irrelevant to the algorithm's global convergence even for the stochastic bandit setting. Consequently, we first identify the necessary and sufficient conditions on the feature representation that can guarantee the asymptotic global convergence of $\texttt{Lin-SPG}$. Under these feature conditions, we prove that $T$ iterations of $\texttt{Lin-SPG}$ with a problem-specific learning rate result in an $O(1/T)$ convergence to the optimal policy. Furthermore, we prove that $\texttt{Lin-SPG}$ with any arbitrary constant learning rate can ensure asymptotic global convergence to the optimal policy.
Improving Large Language Model Planning with Action Sequence Similarity
May 02, 2025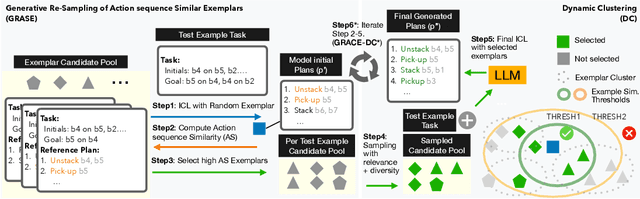

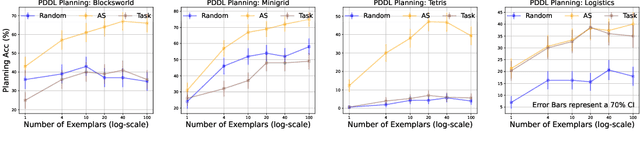

Planning is essential for artificial intelligence systems to look ahead and proactively determine a course of actions to reach objectives in the virtual and real world. Recent work on large language models (LLMs) sheds light on their planning capability in various tasks. However, it remains unclear what signals in the context influence the model performance. In this work, we explore how to improve the model planning capability through in-context learning (ICL), specifically, what signals can help select the exemplars. Through extensive experiments, we observe that commonly used problem similarity may result in false positives with drastically different plans, which can mislead the model. In response, we propose to sample and filter exemplars leveraging plan side action sequence similarity (AS). We propose GRASE-DC: a two-stage pipeline that first re-samples high AS exemplars and then curates the selected exemplars with dynamic clustering on AS to achieve a balance of relevance and diversity. Our experimental result confirms that GRASE-DC achieves significant performance improvement on various planning tasks (up to ~11-40 point absolute accuracy improvement with 27.3% fewer exemplars needed on average). With GRASE-DC* + VAL, where we iteratively apply GRASE-DC with a validator, we are able to even boost the performance by 18.9% more. Extensive analysis validates the consistent performance improvement of GRASE-DC with various backbone LLMs and on both classical planning and natural language planning benchmarks. GRASE-DC can further boost the planning accuracy by ~24 absolute points on harder problems using simpler problems as exemplars over a random baseline. This demonstrates its ability to generalize to out-of-distribution problems.
* 25 pages, 11 figures
Representation Learning via Non-Contrastive Mutual Information
Apr 23, 2025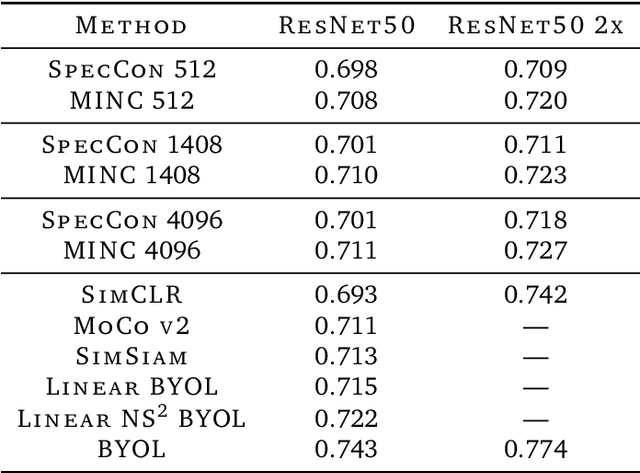
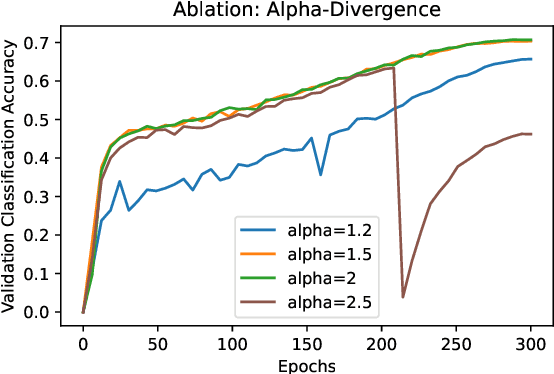
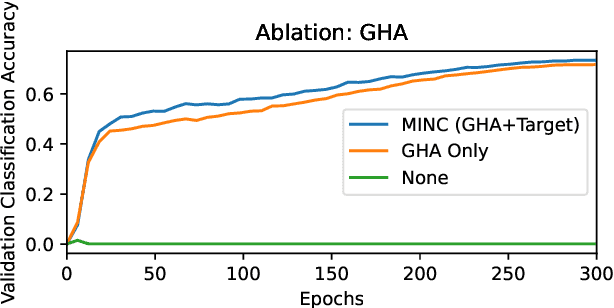
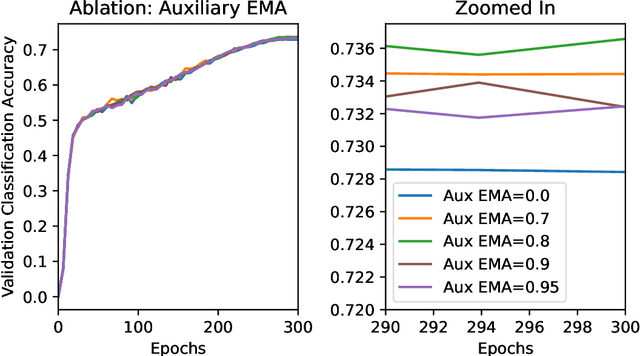
Labeling data is often very time consuming and expensive, leaving us with a majority of unlabeled data. Self-supervised representation learning methods such as SimCLR (Chen et al., 2020) or BYOL (Grill et al., 2020) have been very successful at learning meaningful latent representations from unlabeled image data, resulting in much more general and transferable representations for downstream tasks. Broadly, self-supervised methods fall into two types: 1) Contrastive methods, such as SimCLR; and 2) Non-Contrastive methods, such as BYOL. Contrastive methods are generally trying to maximize mutual information between related data points, so they need to compare every data point to every other data point, resulting in high variance, and thus requiring large batch sizes to work well. Non-contrastive methods like BYOL have much lower variance as they do not need to make pairwise comparisons, but are much trickier to implement as they have the possibility of collapsing to a constant vector. In this paper, we aim to develop a self-supervised objective that combines the strength of both types. We start with a particular contrastive method called the Spectral Contrastive Loss (HaoChen et al., 2021; Lu et al., 2024), and we convert it into a more general non-contrastive form; this removes the pairwise comparisons resulting in lower variance, but keeps the mutual information formulation of the contrastive method preventing collapse. We call our new objective the Mutual Information Non-Contrastive (MINC) loss. We test MINC by learning image representations on ImageNet (similar to SimCLR and BYOL) and show that it consistently improves upon the Spectral Contrastive loss baseline.
Ordering-based Conditions for Global Convergence of Policy Gradient Methods
Apr 02, 2025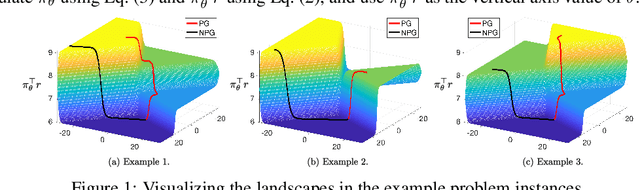
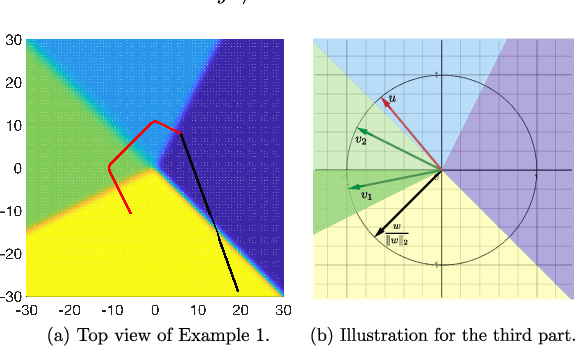
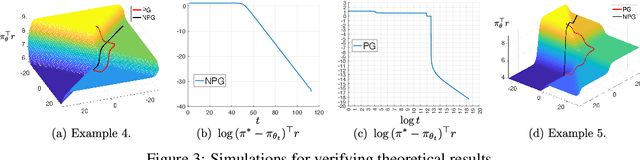
We prove that, for finite-arm bandits with linear function approximation, the global convergence of policy gradient (PG) methods depends on inter-related properties between the policy update and the representation. textcolor{blue}{First}, we establish a few key observations that frame the study: \textbf{(i)} Global convergence can be achieved under linear function approximation without policy or reward realizability, both for the standard Softmax PG and natural policy gradient (NPG). \textbf{(ii)} Approximation error is not a key quantity for characterizing global convergence in either algorithm. \textbf{(iii)} The conditions on the representation that imply global convergence are different between these two algorithms. Overall, these observations call into question approximation error as an appropriate quantity for characterizing the global convergence of PG methods under linear function approximation. \textcolor{blue}{Second}, motivated by these observations, we establish new general results: \textbf{(i)} NPG with linear function approximation achieves global convergence \emph{if and only if} the projection of the reward onto the representable space preserves the optimal action's rank, a quantity that is not strongly related to approximation error. \textbf{(ii)} The global convergence of Softmax PG occurs if the representation satisfies a non-domination condition and can preserve the ranking of rewards, which goes well beyond policy or reward realizability. We provide experimental results to support these theoretical findings.
Small steps no more: Global convergence of stochastic gradient bandits for arbitrary learning rates
Feb 11, 2025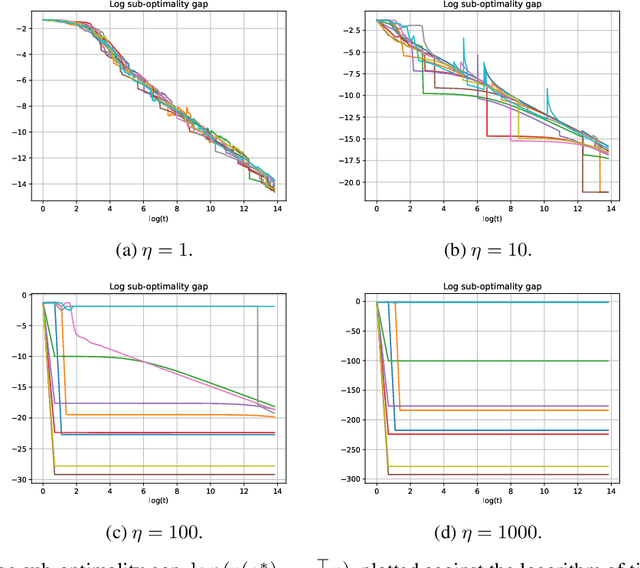
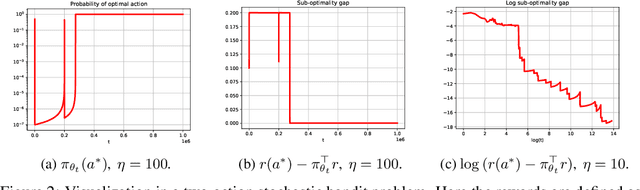
We provide a new understanding of the stochastic gradient bandit algorithm by showing that it converges to a globally optimal policy almost surely using \emph{any} constant learning rate. This result demonstrates that the stochastic gradient algorithm continues to balance exploration and exploitation appropriately even in scenarios where standard smoothness and noise control assumptions break down. The proofs are based on novel findings about action sampling rates and the relationship between cumulative progress and noise, and extend the current understanding of how simple stochastic gradient methods behave in bandit settings.
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Jan 28, 2025



Supervised fine-tuning (SFT) and reinforcement learning (RL) are widely used post-training techniques for foundation models. However, their roles in enhancing model generalization capabilities remain unclear. This paper studies the difference between SFT and RL on generalization and memorization, focusing on text-based rule variants and visual variants. We introduce GeneralPoints, an arithmetic reasoning card game, and adopt V-IRL, a real-world navigation environment, to assess how models trained with SFT and RL generalize to unseen variants in both textual and visual domains. We show that RL, especially when trained with an outcome-based reward, generalizes across both rule-based textual and visual variants. SFT, in contrast, tends to memorize training data and struggles to generalize out-of-distribution scenarios. Further analysis reveals that RL improves the model's underlying visual recognition capabilities, contributing to its enhanced generalization in the visual domain. Despite RL's superior generalization, we show that SFT remains essential for effective RL training; SFT stabilizes the model's output format, enabling subsequent RL to achieve its performance gains. These findings demonstrates the capability of RL for acquiring generalizable knowledge in complex, multi-modal tasks.