 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Intervention Learning from Emergency Stop Interventions
Feb 03, 2026Human interventions are a common source of data in autonomous systems during testing. These interventions provide an important signal about where the current policy needs improvement, but are often noisy and incomplete. We define Robust Intervention Learning (RIL) as the problem of learning from intervention data while remaining robust to the quality and informativeness of the intervention signal. In the best case, interventions are precise and avoiding them is sufficient to solve the task, but in many realistic settings avoiding interventions is necessary but not sufficient for achieving good performance. We study robust intervention learning in the context of emergency stop interventions and propose Residual Intervention Fine-Tuning (RIFT), a residual fine-tuning algorithm that treats intervention feedback as an incomplete learning signal and explicitly combines it with a prior policy. By framing intervention learning as a fine-tuning problem, our approach leverages structure encoded in the prior policy to resolve ambiguity when intervention signals under-specify the task. We provide theoretical analysis characterizing conditions under which this formulation yields principled policy improvement, and identify regimes where intervention learning is expected to fail. Our experiments reveal that residual fine-tuning enables robust and consistent policy improvement across a range of intervention strategies and prior policy qualities, and highlight robust intervention learning as a promising direction for future work.
Self-Predictive Representations for Combinatorial Generalization in Behavioral Cloning
Jun 11, 2025Behavioral cloning (BC) methods trained with supervised learning (SL) are an effective way to learn policies from human demonstrations in domains like robotics. Goal-conditioning these policies enables a single generalist policy to capture diverse behaviors contained within an offline dataset. While goal-conditioned behavior cloning (GCBC) methods can perform well on in-distribution training tasks, they do not necessarily generalize zero-shot to tasks that require conditioning on novel state-goal pairs, i.e. combinatorial generalization. In part, this limitation can be attributed to a lack of temporal consistency in the state representation learned by BC; if temporally related states are encoded to similar latent representations, then the out-of-distribution gap for novel state-goal pairs would be reduced. Hence, encouraging this temporal consistency in the representation space should facilitate combinatorial generalization. Successor representations, which encode the distribution of future states visited from the current state, nicely encapsulate this property. However, previous methods for learning successor representations have relied on contrastive samples, temporal-difference (TD) learning, or both. In this work, we propose a simple yet effective representation learning objective, $\text{BYOL-}\gamma$ augmented GCBC, which is not only able to theoretically approximate the successor representation in the finite MDP case without contrastive samples or TD learning, but also, results in competitive empirical performance across a suite of challenging tasks requiring combinatorial generalization.
Plasticity as the Mirror of Empowerment
May 15, 2025Agents are minimally entities that are influenced by their past observations and act to influence future observations. This latter capacity is captured by empowerment, which has served as a vital framing concept across artificial intelligence and cognitive science. This former capacity, however, is equally foundational: In what ways, and to what extent, can an agent be influenced by what it observes? In this paper, we ground this concept in a universal agent-centric measure that we refer to as plasticity, and reveal a fundamental connection to empowerment. Following a set of desiderata on a suitable definition, we define plasticity using a new information-theoretic quantity we call the generalized directed information. We show that this new quantity strictly generalizes the directed information introduced by Massey (1990) while preserving all of its desirable properties. Our first finding is that plasticity is the mirror of empowerment: The agent's plasticity is identical to the empowerment of the environment, and vice versa. Our second finding establishes a tension between the plasticity and empowerment of an agent, suggesting that agent design needs to be mindful of both characteristics. We explore the implications of these findings, and suggest that plasticity, empowerment, and their relationship are essential to understanding agency.
Cracking the Code of Action: a Generative Approach to Affordances for Reinforcement Learning
Apr 24, 2025Agents that can autonomously navigate the web through a graphical user interface (GUI) using a unified action space (e.g., mouse and keyboard actions) can require very large amounts of domain-specific expert demonstrations to achieve good performance. Low sample efficiency is often exacerbated in sparse-reward and large-action-space environments, such as a web GUI, where only a few actions are relevant in any given situation. In this work, we consider the low-data regime, with limited or no access to expert behavior. To enable sample-efficient learning, we explore the effect of constraining the action space through $\textit{intent-based affordances}$ -- i.e., considering in any situation only the subset of actions that achieve a desired outcome. We propose $\textbf{Code as Generative Affordances}$ $(\textbf{$\texttt{CoGA}$})$, a method that leverages pre-trained vision-language models (VLMs) to generate code that determines affordable actions through implicit intent-completion functions and using a fully-automated program generation and verification pipeline. These programs are then used in-the-loop of a reinforcement learning agent to return a set of affordances given a pixel observation. By greatly reducing the number of actions that an agent must consider, we demonstrate on a wide range of tasks in the MiniWob++ benchmark that: $\textbf{1)}$ $\texttt{CoGA}$ is orders of magnitude more sample efficient than its RL agent, $\textbf{2)}$ $\texttt{CoGA}$'s programs can generalize within a family of tasks, and $\textbf{3)}$ $\texttt{CoGA}$ performs better or on par compared with behavior cloning when a small number of expert demonstrations is available.
Representation Learning via Non-Contrastive Mutual Information
Apr 23, 2025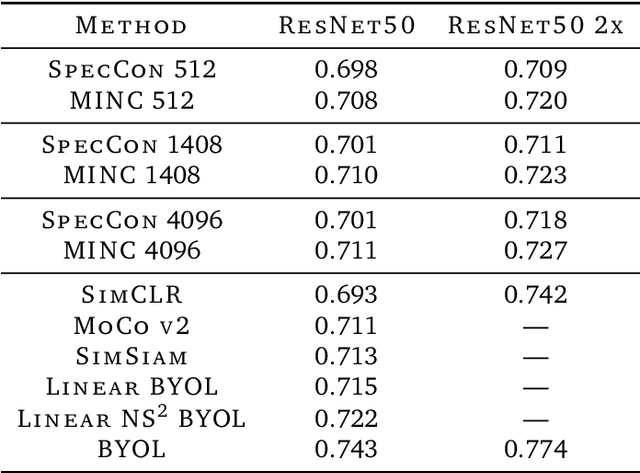
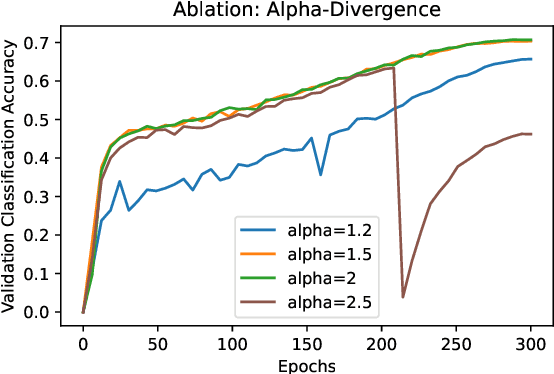
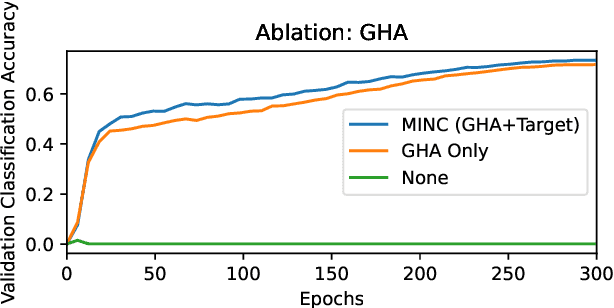
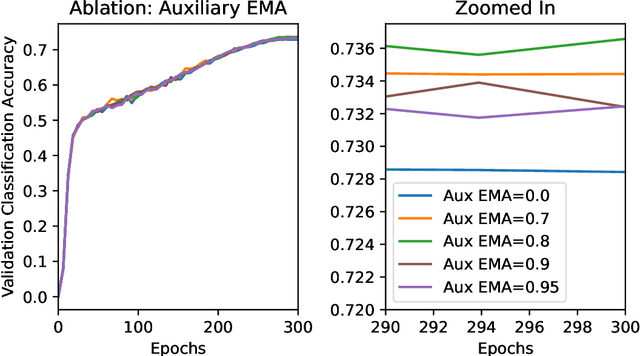
Labeling data is often very time consuming and expensive, leaving us with a majority of unlabeled data. Self-supervised representation learning methods such as SimCLR (Chen et al., 2020) or BYOL (Grill et al., 2020) have been very successful at learning meaningful latent representations from unlabeled image data, resulting in much more general and transferable representations for downstream tasks. Broadly, self-supervised methods fall into two types: 1) Contrastive methods, such as SimCLR; and 2) Non-Contrastive methods, such as BYOL. Contrastive methods are generally trying to maximize mutual information between related data points, so they need to compare every data point to every other data point, resulting in high variance, and thus requiring large batch sizes to work well. Non-contrastive methods like BYOL have much lower variance as they do not need to make pairwise comparisons, but are much trickier to implement as they have the possibility of collapsing to a constant vector. In this paper, we aim to develop a self-supervised objective that combines the strength of both types. We start with a particular contrastive method called the Spectral Contrastive Loss (HaoChen et al., 2021; Lu et al., 2024), and we convert it into a more general non-contrastive form; this removes the pairwise comparisons resulting in lower variance, but keeps the mutual information formulation of the contrastive method preventing collapse. We call our new objective the Mutual Information Non-Contrastive (MINC) loss. We test MINC by learning image representations on ImageNet (similar to SimCLR and BYOL) and show that it consistently improves upon the Spectral Contrastive loss baseline.
Long Range Navigator (LRN): Extending robot planning horizons beyond metric maps
Apr 17, 2025A robot navigating an outdoor environment with no prior knowledge of the space must rely on its local sensing to perceive its surroundings and plan. This can come in the form of a local metric map or local policy with some fixed horizon. Beyond that, there is a fog of unknown space marked with some fixed cost. A limited planning horizon can often result in myopic decisions leading the robot off course or worse, into very difficult terrain. Ideally, we would like the robot to have full knowledge that can be orders of magnitude larger than a local cost map. In practice, this is intractable due to sparse sensing information and often computationally expensive. In this work, we make a key observation that long-range navigation only necessitates identifying good frontier directions for planning instead of full map knowledge. To this end, we propose Long Range Navigator (LRN), that learns an intermediate affordance representation mapping high-dimensional camera images to `affordable' frontiers for planning, and then optimizing for maximum alignment with the desired goal. LRN notably is trained entirely on unlabeled ego-centric videos making it easy to scale and adapt to new platforms. Through extensive off-road experiments on Spot and a Big Vehicle, we find that augmenting existing navigation stacks with LRN reduces human interventions at test-time and leads to faster decision making indicating the relevance of LRN. https://personalrobotics.github.io/lrn
Agency Is Frame-Dependent
Feb 06, 2025
Agency is a system's capacity to steer outcomes toward a goal, and is a central topic of study across biology, philosophy, cognitive science, and artificial intelligence. Determining if a system exhibits agency is a notoriously difficult question: Dennett (1989), for instance, highlights the puzzle of determining which principles can decide whether a rock, a thermostat, or a robot each possess agency. We here address this puzzle from the viewpoint of reinforcement learning by arguing that agency is fundamentally frame-dependent: Any measurement of a system's agency must be made relative to a reference frame. We support this claim by presenting a philosophical argument that each of the essential properties of agency proposed by Barandiaran et al. (2009) and Moreno (2018) are themselves frame-dependent. We conclude that any basic science of agency requires frame-dependence, and discuss the implications of this claim for reinforcement learning.
Normalization and effective learning rates in reinforcement learning
Jul 01, 2024



Normalization layers have recently experienced a renaissance in the deep reinforcement learning and continual learning literature, with several works highlighting diverse benefits such as improving loss landscape conditioning and combatting overestimation bias. However, normalization brings with it a subtle but important side effect: an equivalence between growth in the norm of the network parameters and decay in the effective learning rate. This becomes problematic in continual learning settings, where the resulting effective learning rate schedule may decay to near zero too quickly relative to the timescale of the learning problem. We propose to make the learning rate schedule explicit with a simple re-parameterization which we call Normalize-and-Project (NaP), which couples the insertion of normalization layers with weight projection, ensuring that the effective learning rate remains constant throughout training. This technique reveals itself as a powerful analytical tool to better understand learning rate schedules in deep reinforcement learning, and as a means of improving robustness to nonstationarity in synthetic plasticity loss benchmarks along with both the single-task and sequential variants of the Arcade Learning Environment. We also show that our approach can be easily applied to popular architectures such as ResNets and transformers while recovering and in some cases even slightly improving the performance of the base model in common stationary benchmarks.
A Unifying Framework for Action-Conditional Self-Predictive Reinforcement Learning
Jun 04, 2024



Learning a good representation is a crucial challenge for Reinforcement Learning (RL) agents. Self-predictive learning provides means to jointly learn a latent representation and dynamics model by bootstrapping from future latent representations (BYOL). Recent work has developed theoretical insights into these algorithms by studying a continuous-time ODE model for self-predictive representation learning under the simplifying assumption that the algorithm depends on a fixed policy (BYOL-$\Pi$); this assumption is at odds with practical instantiations of such algorithms, which explicitly condition their predictions on future actions. In this work, we take a step towards bridging the gap between theory and practice by analyzing an action-conditional self-predictive objective (BYOL-AC) using the ODE framework, characterizing its convergence properties and highlighting important distinctions between the limiting solutions of the BYOL-$\Pi$ and BYOL-AC dynamics. We show how the two representations are related by a variance equation. This connection leads to a novel variance-like action-conditional objective (BYOL-VAR) and its corresponding ODE. We unify the study of all three objectives through two complementary lenses; a model-based perspective, where each objective is shown to be equivalent to a low-rank approximation of certain dynamics, and a model-free perspective, which establishes relationships between the objectives and their respective value, Q-value, and advantage function. Our empirical investigations, encompassing both linear function approximation and Deep RL environments, demonstrates that BYOL-AC is better overall in a variety of different settings.
Disentangling the Causes of Plasticity Loss in Neural Networks
Feb 29, 2024Underpinning the past decades of work on the design, initialization, and optimization of neural networks is a seemingly innocuous assumption: that the network is trained on a \textit{stationary} data distribution. In settings where this assumption is violated, e.g.\ deep reinforcement learning, learning algorithms become unstable and brittle with respect to hyperparameters and even random seeds. One factor driving this instability is the loss of plasticity, meaning that updating the network's predictions in response to new information becomes more difficult as training progresses. While many recent works provide analyses and partial solutions to this phenomenon, a fundamental question remains unanswered: to what extent do known mechanisms of plasticity loss overlap, and how can mitigation strategies be combined to best maintain the trainability of a network? This paper addresses these questions, showing that loss of plasticity can be decomposed into multiple independent mechanisms and that, while intervening on any single mechanism is insufficient to avoid the loss of plasticity in all cases, intervening on multiple mechanisms in conjunction results in highly robust learning algorithms. We show that a combination of layer normalization and weight decay is highly effective at maintaining plasticity in a variety of synthetic nonstationary learning tasks, and further demonstrate its effectiveness on naturally arising nonstationarities, including reinforcement learning in the Arcade Learning Environment.