 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Quantized Latent Concepts: A Scalable Alternative to Clustering-Based Concept Discovery
Feb 02, 2026Deep Learning models encode rich semantic information in their hidden representations. However, it remains challenging to understand which parts of this information models actually rely on when making predictions. A promising line of post-hoc concept-based explanation methods relies on clustering token representations. However, commonly used approaches such as hierarchical clustering are computationally infeasible for large-scale datasets, and K-Means often yields shallow or frequency-dominated clusters. We propose the vector quantized latent concept (VQLC) method, a framework built upon the vector quantized-variational autoencoder (VQ-VAE) architecture that learns a discrete codebook mapping continuous representations to concept vectors. We perform thorough evaluations and show that VQLC improves scalability while maintaining comparable quality of human-understandable explanations.
Zero-Shot Anomaly Detection with Dual-Branch Prompt Learning
Aug 01, 2025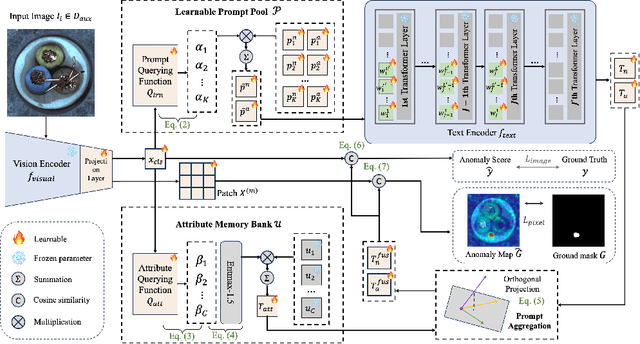



Zero-shot anomaly detection (ZSAD) enables identifying and localizing defects in unseen categories by relying solely on generalizable features rather than requiring any labeled examples of anomalies. However, existing ZSAD methods, whether using fixed or learned prompts, struggle under domain shifts because their training data are derived from limited training domains and fail to generalize to new distributions. In this paper, we introduce PILOT, a framework designed to overcome these challenges through two key innovations: (1) a novel dual-branch prompt learning mechanism that dynamically integrates a pool of learnable prompts with structured semantic attributes, enabling the model to adaptively weight the most relevant anomaly cues for each input image; and (2) a label-free test-time adaptation strategy that updates the learnable prompt parameters using high-confidence pseudo-labels from unlabeled test data. Extensive experiments on 13 industrial and medical benchmarks demonstrate that PILOT achieves state-of-the-art performance in both anomaly detection and localization under domain shift.
GitChameleon: Evaluating AI Code Generation Against Python Library Version Incompatibilities
Jul 16, 2025
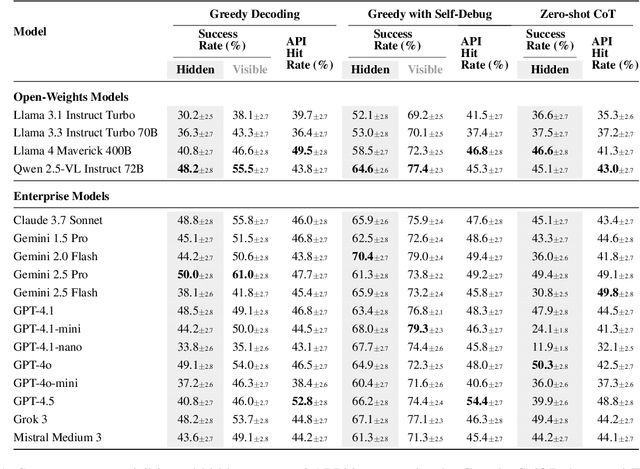
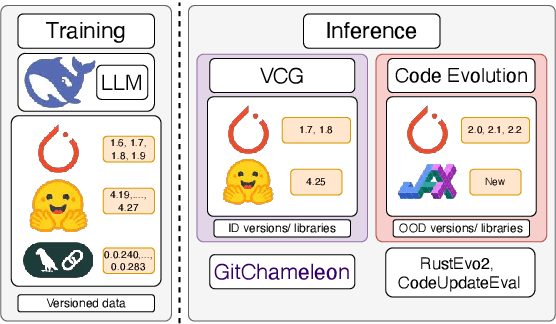
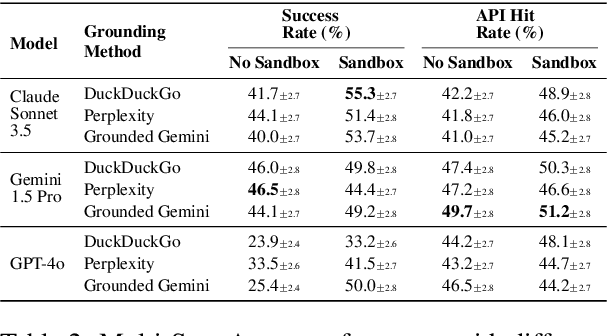
The rapid evolution of software libraries poses a considerable hurdle for code generation, necessitating continuous adaptation to frequent version updates while preserving backward compatibility. While existing code evolution benchmarks provide valuable insights, they typically lack execution-based evaluation for generating code compliant with specific library versions. To address this, we introduce GitChameleon, a novel, meticulously curated dataset comprising 328 Python code completion problems, each conditioned on specific library versions and accompanied by executable unit tests. GitChameleon rigorously evaluates the capacity of contemporary large language models (LLMs), LLM-powered agents, code assistants, and RAG systems to perform version-conditioned code generation that demonstrates functional accuracy through execution. Our extensive evaluations indicate that state-of-the-art systems encounter significant challenges with this task; enterprise models achieving baseline success rates in the 48-51\% range, underscoring the intricacy of the problem. By offering an execution-based benchmark emphasizing the dynamic nature of code libraries, GitChameleon enables a clearer understanding of this challenge and helps guide the development of more adaptable and dependable AI code generation methods. We make the dataset and evaluation code publicly available at https://github.com/mrcabbage972/GitChameleonBenchmark.
Estimating Head Motion in Structural MRI Using a Deep Neural Network Trained on Synthetic Artifacts
May 29, 2025Motion-related artifacts are inevitable in Magnetic Resonance Imaging (MRI) and can bias automated neuroanatomical metrics such as cortical thickness. Manual review cannot objectively quantify motion in anatomical scans, and existing automated approaches often require specialized hardware or rely on unbalanced noisy training data. Here, we train a 3D convolutional neural network to estimate motion severity using only synthetically corrupted volumes. We validate our method with one held-out site from our training cohort and with 14 fully independent datasets, including one with manual ratings, achieving a representative $R^2 = 0.65$ versus manual labels and significant thickness-motion correlations in 12/15 datasets. Furthermore, our predicted motion correlates with subject age in line with prior studies. Our approach generalizes across scanner brands and protocols, enabling objective, scalable motion assessment in structural MRI studies without prospective motion correction.
Towards Fair In-Context Learning with Tabular Foundation Models
May 15, 2025Tabular foundational models have exhibited strong in-context learning (ICL) capabilities on structured data, allowing them to make accurate predictions on test sets without parameter updates, using training examples as context. This emerging approach positions itself as a competitive alternative to traditional gradient-boosted tree methods. However, while biases in conventional machine learning models are well documented, it remains unclear how these biases manifest in tabular ICL. The paper investigates the fairness implications of tabular ICL and explores three preprocessing strategies--correlation removal, group-balanced demonstration selection, and uncertainty-based demonstration selection--to address bias. Comprehensive experiments indicate that uncertainty-based demonstration selection consistently enhances group fairness of in-context predictions. The source code for reproducing the results of this work can be found at https://github.com/patrikken/Fair-TabICL.
Handling Delay in Real-Time Reinforcement Learning
Mar 30, 2025Real-time reinforcement learning (RL) introduces several challenges. First, policies are constrained to a fixed number of actions per second due to hardware limitations. Second, the environment may change while the network is still computing an action, leading to observational delay. The first issue can partly be addressed with pipelining, leading to higher throughput and potentially better policies. However, the second issue remains: if each neuron operates in parallel with an execution time of $\tau$, an $N$-layer feed-forward network experiences observation delay of $\tau N$. Reducing the number of layers can decrease this delay, but at the cost of the network's expressivity. In this work, we explore the trade-off between minimizing delay and network's expressivity. We present a theoretically motivated solution that leverages temporal skip connections combined with history-augmented observations. We evaluate several architectures and show that those incorporating temporal skip connections achieve strong performance across various neuron execution times, reinforcement learning algorithms, and environments, including four Mujoco tasks and all MinAtar games. Moreover, we demonstrate parallel neuron computation can accelerate inference by 6-350% on standard hardware. Our investigation into temporal skip connections and parallel computations paves the way for more efficient RL agents in real-time setting.
Behaviour Discovery and Attribution for Explainable Reinforcement Learning
Mar 19, 2025Explaining the decisions made by reinforcement learning (RL) agents is critical for building trust and ensuring reliability in real-world applications. Traditional approaches to explainability often rely on saliency analysis, which can be limited in providing actionable insights. Recently, there has been growing interest in attributing RL decisions to specific trajectories within a dataset. However, these methods often generalize explanations to long trajectories, potentially involving multiple distinct behaviors. Often, providing multiple more fine grained explanations would improve clarity. In this work, we propose a framework for behavior discovery and action attribution to behaviors in offline RL trajectories. Our method identifies meaningful behavioral segments, enabling more precise and granular explanations associated with high level agent behaviors. This approach is adaptable across diverse environments with minimal modifications, offering a scalable and versatile solution for behavior discovery and attribution for explainable RL.
Comparative Analysis of Diffusion Generative Models in Computational Pathology
Nov 24, 2024



Diffusion Generative Models (DGM) have rapidly surfaced as emerging topics in the field of computer vision, garnering significant interest across a wide array of deep learning applications. Despite their high computational demand, these models are extensively utilized for their superior sample quality and robust mode coverage. While research in diffusion generative models is advancing, exploration within the domain of computational pathology and its large-scale datasets has been comparatively gradual. Bridging the gap between the high-quality generation capabilities of Diffusion Generative Models and the intricate nature of pathology data, this paper presents an in-depth comparative analysis of diffusion methods applied to a pathology dataset. Our analysis extends to datasets with varying Fields of View (FOV), revealing that DGMs are highly effective in producing high-quality synthetic data. An ablative study is also conducted, followed by a detailed discussion on the impact of various methods on the synthesized histopathology images. One striking observation from our experiments is how the adjustment of image size during data generation can simulate varying fields of view. These findings underscore the potential of DGMs to enhance the quality and diversity of synthetic pathology data, especially when used with real data, ultimately increasing accuracy of deep learning models in histopathology. Code is available from https://github.com/AtlasAnalyticsLab/Diffusion4Path
Adaptive Group Robust Ensemble Knowledge Distillation
Nov 22, 2024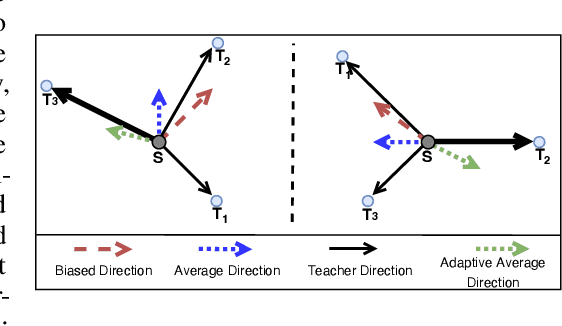
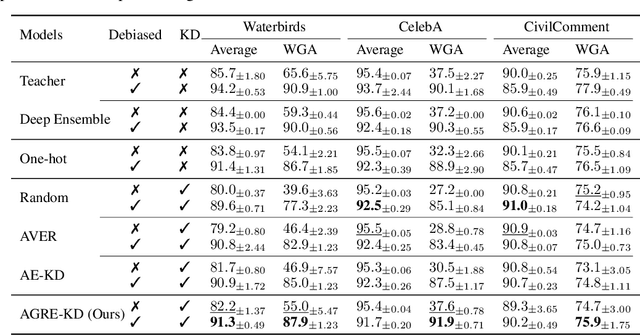
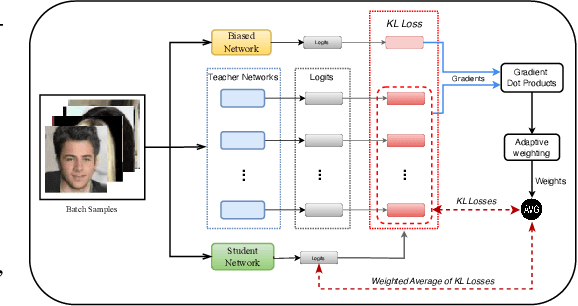
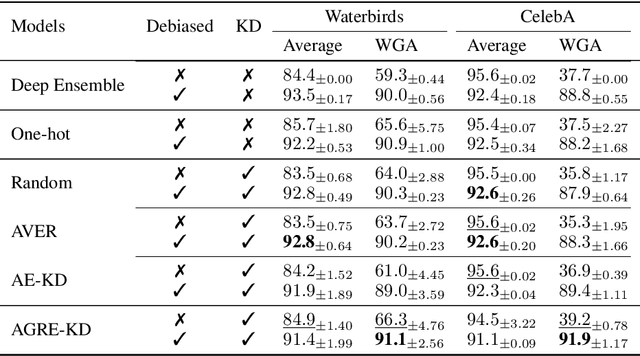
Neural networks can learn spurious correlations in the data, often leading to performance disparity for underrepresented subgroups. Studies have demonstrated that the disparity is amplified when knowledge is distilled from a complex teacher model to a relatively "simple" student model. Prior work has shown that ensemble deep learning methods can improve the performance of the worst-case subgroups; however, it is unclear if this advantage carries over when distilling knowledge from an ensemble of teachers, especially when the teacher models are debiased. This study demonstrates that traditional ensemble knowledge distillation can significantly drop the performance of the worst-case subgroups in the distilled student model even when the teacher models are debiased. To overcome this, we propose Adaptive Group Robust Ensemble Knowledge Distillation (AGRE-KD), a simple ensembling strategy to ensure that the student model receives knowledge beneficial for unknown underrepresented subgroups. Leveraging an additional biased model, our method selectively chooses teachers whose knowledge would better improve the worst-performing subgroups by upweighting the teachers with gradient directions deviating from the biased model. Our experiments on several datasets demonstrate the superiority of the proposed ensemble distillation technique and show that it can even outperform classic model ensembles based on majority voting.
KD-LoRA: A Hybrid Approach to Efficient Fine-Tuning with LoRA and Knowledge Distillation
Oct 28, 2024



Large language models (LLMs) have demonstrated remarkable performance across various downstream tasks. However, the high computational and memory requirements of LLMs are a major bottleneck. To address this, parameter-efficient fine-tuning (PEFT) methods such as low-rank adaptation (LoRA) have been proposed to reduce computational costs while ensuring minimal loss in performance. Additionally, knowledge distillation (KD) has been a popular choice for obtaining compact student models from teacher models. In this work, we present KD-LoRA, a novel fine-tuning method that combines LoRA with KD. Our results demonstrate that KD-LoRA achieves performance comparable to full fine-tuning (FFT) and LoRA while significantly reducing resource requirements. Specifically, KD-LoRA retains 98% of LoRA's performance on the GLUE benchmark, while being 40% more compact. Additionally, KD-LoRA reduces GPU memory usage by 30% compared to LoRA, while decreasing inference time by 30% compared to both FFT and LoRA. We evaluate KD-LoRA across three encoder-only models: BERT, RoBERTa, and DeBERTaV3. Code is available at https://github.com/rambodazimi/KD-LoRA.