 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiTab: A Scalable Foundation for Multitask Learning on Tabular Data
Nov 13, 2025Tabular data is the most abundant data type in the world, powering systems in finance, healthcare, e-commerce, and beyond. As tabular datasets grow and span multiple related targets, there is an increasing need to exploit shared task information for improved multitask generalization. Multitask learning (MTL) has emerged as a powerful way to improve generalization and efficiency, yet most existing work focuses narrowly on large-scale recommendation systems, leaving its potential in broader tabular domains largely underexplored. Also, existing MTL approaches for tabular data predominantly rely on multi-layer perceptron-based backbones, which struggle to capture complex feature interactions and often fail to scale when data is abundant, a limitation that transformer architectures have overcome in other domains. Motivated by this, we introduce MultiTab-Net, the first multitask transformer architecture specifically designed for large tabular data. MultiTab-Net employs a novel multitask masked-attention mechanism that dynamically models feature-feature dependencies while mitigating task competition. Through extensive experiments, we show that MultiTab-Net consistently achieves higher multitask gain than existing MTL architectures and single-task transformers across diverse domains including large-scale recommendation data, census-like socioeconomic data, and physics datasets, spanning a wide range of task counts, task types, and feature modalities. In addition, we contribute MultiTab-Bench, a generalized multitask synthetic dataset generator that enables systematic evaluation of multitask dynamics by tuning task count, task correlations, and relative task complexity. Our code is publicly available at https://github.com/Armanfard-Lab/MultiTab.
Zero-Shot Anomaly Detection with Dual-Branch Prompt Learning
Aug 01, 2025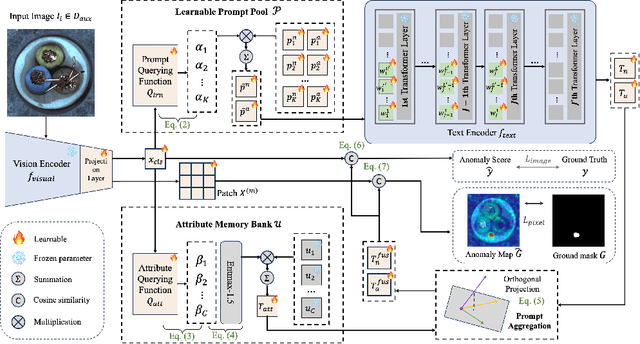



Zero-shot anomaly detection (ZSAD) enables identifying and localizing defects in unseen categories by relying solely on generalizable features rather than requiring any labeled examples of anomalies. However, existing ZSAD methods, whether using fixed or learned prompts, struggle under domain shifts because their training data are derived from limited training domains and fail to generalize to new distributions. In this paper, we introduce PILOT, a framework designed to overcome these challenges through two key innovations: (1) a novel dual-branch prompt learning mechanism that dynamically integrates a pool of learnable prompts with structured semantic attributes, enabling the model to adaptively weight the most relevant anomaly cues for each input image; and (2) a label-free test-time adaptation strategy that updates the learnable prompt parameters using high-confidence pseudo-labels from unlabeled test data. Extensive experiments on 13 industrial and medical benchmarks demonstrate that PILOT achieves state-of-the-art performance in both anomaly detection and localization under domain shift.
Unveiling the Flaws: A Critical Analysis of Initialization Effect on Time Series Anomaly Detection
Aug 13, 2024



Deep learning for time-series anomaly detection (TSAD) has gained significant attention over the past decade. Despite the reported improvements in several papers, the practical application of these models remains limited. Recent studies have cast doubt on these models, attributing their results to flawed evaluation techniques. However, the impact of initialization has largely been overlooked. This paper provides a critical analysis of the initialization effects on TSAD model performance. Our extensive experiments reveal that TSAD models are highly sensitive to hyperparameters such as window size, seed number, and normalization. This sensitivity often leads to significant variability in performance, which can be exploited to artificially inflate the reported efficacy of these models. We demonstrate that even minor changes in initialization parameters can result in performance variations that overshadow the claimed improvements from novel model architectures. Our findings highlight the need for rigorous evaluation protocols and transparent reporting of preprocessing steps to ensure the reliability and fairness of anomaly detection methods. This paper calls for a more cautious interpretation of TSAD advancements and encourages the development of more robust and transparent evaluation practices to advance the field and its practical applications.
Forward-Backward Knowledge Distillation for Continual Clustering
May 29, 2024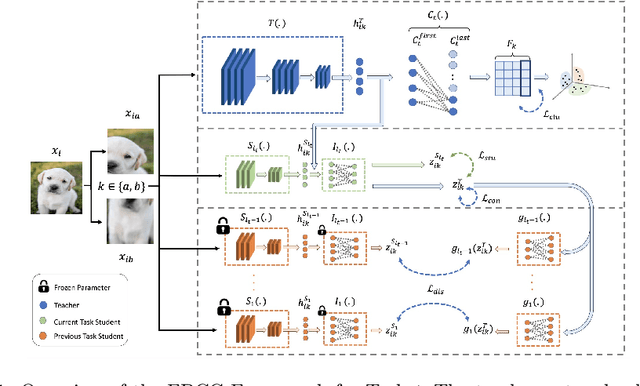
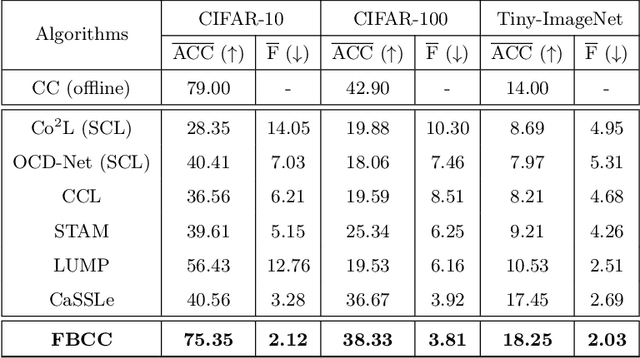
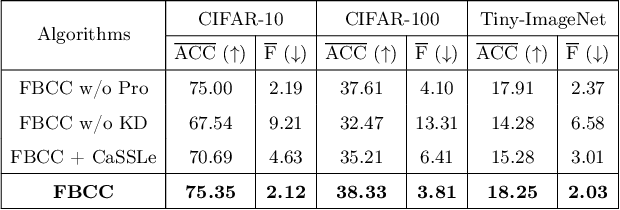
Unsupervised Continual Learning (UCL) is a burgeoning field in machine learning, focusing on enabling neural networks to sequentially learn tasks without explicit label information. Catastrophic Forgetting (CF), where models forget previously learned tasks upon learning new ones, poses a significant challenge in continual learning, especially in UCL, where labeled information of data is not accessible. CF mitigation strategies, such as knowledge distillation and replay buffers, often face memory inefficiency and privacy issues. Although current research in UCL has endeavored to refine data representations and address CF in streaming data contexts, there is a noticeable lack of algorithms specifically designed for unsupervised clustering. To fill this gap, in this paper, we introduce the concept of Unsupervised Continual Clustering (UCC). We propose Forward-Backward Knowledge Distillation for unsupervised Continual Clustering (FBCC) to counteract CF within the context of UCC. FBCC employs a single continual learner (the ``teacher'') with a cluster projector, along with multiple student models, to address the CF issue. The proposed method consists of two phases: Forward Knowledge Distillation, where the teacher learns new clusters while retaining knowledge from previous tasks with guidance from specialized student models, and Backward Knowledge Distillation, where a student model mimics the teacher's behavior to retain task-specific knowledge, aiding the teacher in subsequent tasks. FBCC marks a pioneering approach to UCC, demonstrating enhanced performance and memory efficiency in clustering across various tasks, outperforming the application of clustering algorithms to the latent space of state-of-the-art UCL algorithms.
Deep Clustering with Self-Supervision using Pairwise Similarities
May 06, 2024Deep clustering incorporates embedding into clustering to find a lower-dimensional space appropriate for clustering. In this paper, we propose a novel deep clustering framework with self-supervision using pairwise similarities (DCSS). The proposed method consists of two successive phases. In the first phase, we propose to form hypersphere-like groups of similar data points, i.e. one hypersphere per cluster, employing an autoencoder that is trained using cluster-specific losses. The hyper-spheres are formed in the autoencoder's latent space. In the second phase, we propose to employ pairwise similarities to create a $K$-dimensional space that is capable of accommodating more complex cluster distributions, hence providing more accurate clustering performance. $K$ is the number of clusters. The autoencoder's latent space obtained in the first phase is used as the input of the second phase. The effectiveness of both phases is demonstrated on seven benchmark datasets by conducting a rigorous set of experiments.
Graph-Jigsaw Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection
Mar 18, 2024Skeleton-based video anomaly detection (SVAD) is a crucial task in computer vision. Accurately identifying abnormal patterns or events enables operators to promptly detect suspicious activities, thereby enhancing safety. Achieving this demands a comprehensive understanding of human motions, both at body and region levels, while also accounting for the wide variations of performing a single action. However, existing studies fail to simultaneously address these crucial properties. This paper introduces a novel, practical and lightweight framework, namely Graph-Jigsaw Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection (GiCiSAD) to overcome the challenges associated with SVAD. GiCiSAD consists of three novel modules: the Graph Attention-based Forecasting module to capture the spatio-temporal dependencies inherent in the data, the Graph-level Jigsaw Puzzle Maker module to distinguish subtle region-level discrepancies between normal and abnormal motions, and the Graph-based Conditional Diffusion model to generate a wide spectrum of human motions. Extensive experiments on four widely used skeleton-based video datasets show that GiCiSAD outperforms existing methods with significantly fewer training parameters, establishing it as the new state-of-the-art.
EMA-Net: Efficient Multitask Affinity Learning for Dense Scene Predictions
Jan 20, 2024Multitask learning (MTL) has gained prominence for its ability to jointly predict multiple tasks, achieving better per-task performance while using fewer per-task model parameters than single-task learning. More recently, decoder-focused architectures have considerably improved multitask performance by refining task predictions using the features of other related tasks. However, most of these refinement methods fail to simultaneously capture local and global task-specific representations, as well as cross-task patterns in a parameter-efficient manner. In this paper, we introduce the Efficient Multitask Affinity Learning Network (EMA-Net), which is a lightweight framework that enhances the task refinement capabilities of multitask networks. EMA-Net adeptly captures local, global, and cross-task interactions using our novel Cross-Task Affinity Learning (CTAL) module. The key innovation of CTAL lies in its ability to manipulate task affinity matrices in a manner that is optimally suited to apply parameter-efficient grouped convolutions without worrying about information loss. Our results show that we achieve state-of-the-art MTL performance for CNN-based decoder-focused models while using substantially fewer model parameters. Our code is publicly available at https://github.com/Armanfard-Lab/EMA-Net.
Open-Set Multivariate Time-Series Anomaly Detection
Oct 18, 2023Numerous methods for time series anomaly detection (TSAD) methods have emerged in recent years. Most existing methods are unsupervised and assume the availability of normal training samples only, while few supervised methods have shown superior performance by incorporating labeled anomalous samples in the training phase. However, certain anomaly types are inherently challenging for unsupervised methods to differentiate from normal data, while supervised methods are constrained to detecting anomalies resembling those present during training, failing to generalize to unseen anomaly classes. This paper is the first attempt in providing a novel approach for the open-set TSAD problem, in which a small number of labeled anomalies from a limited class of anomalies are visible in the training phase, with the objective of detecting both seen and unseen anomaly classes in the test phase. The proposed method, called Multivariate Open-Set timeseries Anomaly Detection (MOSAD) consists of three primary modules: a Feature Extractor to extract meaningful time-series features; a Multi-head Network consisting of Generative-, Deviation-, and Contrastive heads for capturing both seen and unseen anomaly classes; and an Anomaly Scoring module leveraging the insights of the three heads to detect anomalies. Extensive experiments on three real-world datasets consistently show that our approach surpasses existing methods under various experimental settings, thus establishing a new state-of-the-art performance in the TSAD field.
Explainable Attention for Few-shot Learning and Beyond
Oct 11, 2023Attention mechanisms have exhibited promising potential in enhancing learning models by identifying salient portions of input data. This is particularly valuable in scenarios where limited training samples are accessible due to challenges in data collection and labeling. Drawing inspiration from human recognition processes, we posit that an AI baseline's performance could be more accurate and dependable if it is exposed to essential segments of raw data rather than the entire input dataset, akin to human perception. However, the task of selecting these informative data segments, referred to as hard attention finding, presents a formidable challenge. In situations with few training samples, existing studies struggle to locate such informative regions due to the large number of training parameters that cannot be effectively learned from the available limited samples. In this study, we introduce a novel and practical framework for achieving explainable hard attention finding, specifically tailored for few-shot learning scenarios, called FewXAT. Our approach employs deep reinforcement learning to implement the concept of hard attention, directly impacting raw input data and thus rendering the process interpretable for human understanding. Through extensive experimentation across various benchmark datasets, we demonstrate the efficacy of our proposed method.
Multivariate Time-Series Anomaly Detection with Contaminated Data: Application to Physiological Signals
Aug 24, 2023Mainstream unsupervised anomaly detection algorithms often excel in academic datasets, yet their real-world performance is restricted due to the controlled experimental conditions involving clean training data. Addressing the challenge of training with noise, a prevalent issue in practical anomaly detection, is frequently overlooked. In a pioneering endeavor, this study delves into the realm of label-level noise within sensory time-series anomaly detection (TSAD). This paper presents a novel and practical end-to-end unsupervised TSAD when the training data are contaminated with anomalies. The introduced approach, called TSAD-C, is devoid of access to abnormality labels during the training phase. TSAD-C encompasses three modules: a Decontaminator to rectify the abnormalities (aka noise) present in the training data, a Variable Dependency Modeling module to capture both long-term intra- and inter-variable dependencies within the decontaminated data that can be considered as a surrogate of the pure normal data, and an Anomaly Scoring module to detect anomalies. Our extensive experiments conducted on three widely used physiological datasets conclusively demonstrate that our approach surpasses existing methodologies, thus establishing a new state-of-the-art performance in the field.