 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Continual Clustering via Forward-Backward Knowledge Distillation
Jun 05, 2026Unsupervised Continual Learning (UCL) aims to enable neural networks to learn sequential tasks without labels or access to past data. A major challenge in this setting is Catastrophic Forgetting, where models forget previously learned tasks upon learning new ones. This challenge is amplified in UCL due to the absence of labels to guide learning and memory retention. Existing mitigation strategies, such as knowledge distillation and replay buffers, often raise memory and privacy concerns. Moreover, current UCL methods largely overlook clustering-specific objectives. To fill this gap, we introduce Unsupervised Continual Clustering (UCC) and propose Forward-Backward Knowledge Distillation for Continual Clustering (FBCC). FBCC employs a continual teacher network with a clustering projector and lightweight task-specific students. Through a dual-phase forward-backward distillation process, the teacher learns new clusters while preserving previously discovered cluster structure without storing past data. FBCC represents a pioneering approach to UCC, demonstrating improved clustering performance across sequential tasks. Experiments on four benchmark datasets demonstrate that FBCC consistently outperforms existing continual learning baselines in clustering accuracy while significantly reducing catastrophic forgetting.
Forward-Backward Knowledge Distillation for Continual Clustering
May 29, 2024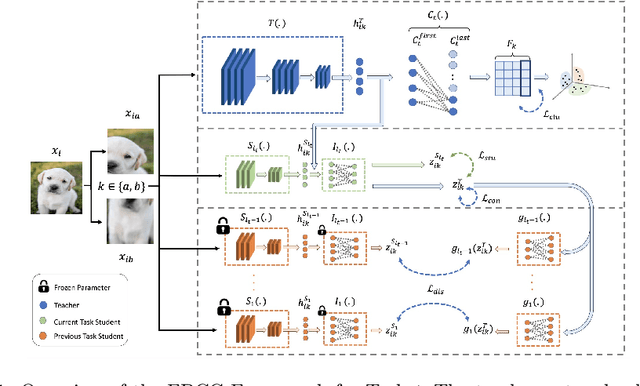
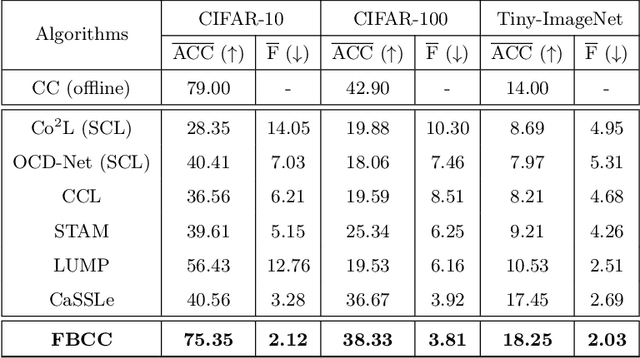
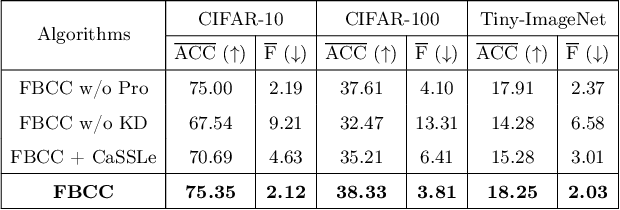
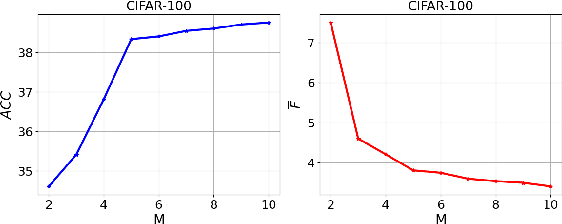
Unsupervised Continual Learning (UCL) is a burgeoning field in machine learning, focusing on enabling neural networks to sequentially learn tasks without explicit label information. Catastrophic Forgetting (CF), where models forget previously learned tasks upon learning new ones, poses a significant challenge in continual learning, especially in UCL, where labeled information of data is not accessible. CF mitigation strategies, such as knowledge distillation and replay buffers, often face memory inefficiency and privacy issues. Although current research in UCL has endeavored to refine data representations and address CF in streaming data contexts, there is a noticeable lack of algorithms specifically designed for unsupervised clustering. To fill this gap, in this paper, we introduce the concept of Unsupervised Continual Clustering (UCC). We propose Forward-Backward Knowledge Distillation for unsupervised Continual Clustering (FBCC) to counteract CF within the context of UCC. FBCC employs a single continual learner (the ``teacher'') with a cluster projector, along with multiple student models, to address the CF issue. The proposed method consists of two phases: Forward Knowledge Distillation, where the teacher learns new clusters while retaining knowledge from previous tasks with guidance from specialized student models, and Backward Knowledge Distillation, where a student model mimics the teacher's behavior to retain task-specific knowledge, aiding the teacher in subsequent tasks. FBCC marks a pioneering approach to UCC, demonstrating enhanced performance and memory efficiency in clustering across various tasks, outperforming the application of clustering algorithms to the latent space of state-of-the-art UCL algorithms.
Deep Clustering with Self-Supervision using Pairwise Similarities
May 06, 2024Deep clustering incorporates embedding into clustering to find a lower-dimensional space appropriate for clustering. In this paper, we propose a novel deep clustering framework with self-supervision using pairwise similarities (DCSS). The proposed method consists of two successive phases. In the first phase, we propose to form hypersphere-like groups of similar data points, i.e. one hypersphere per cluster, employing an autoencoder that is trained using cluster-specific losses. The hyper-spheres are formed in the autoencoder's latent space. In the second phase, we propose to employ pairwise similarities to create a $K$-dimensional space that is capable of accommodating more complex cluster distributions, hence providing more accurate clustering performance. $K$ is the number of clusters. The autoencoder's latent space obtained in the first phase is used as the input of the second phase. The effectiveness of both phases is demonstrated on seven benchmark datasets by conducting a rigorous set of experiments.
C3: Cross-instance guided Contrastive Clustering
Nov 21, 2022Clustering is the task of gathering similar data samples into clusters without using any predefined labels. It has been widely studied in machine learning literature, and recent advancements in deep learning have revived interest in this field. Contrastive clustering (CC) models are a staple of deep clustering in which positive and negative pairs of each data instance are generated through data augmentation. CC models aim to learn a feature space where instance-level and cluster-level representations of positive pairs are grouped together. Despite improving the SOTA, these algorithms ignore the cross-instance patterns, which carry essential information for improving clustering performance. In this paper, we propose a novel contrastive clustering method, Cross-instance guided Contrastive Clustering (C3), that considers the cross-sample relationships to increase the number of positive pairs. In particular, we define a new loss function that identifies similar instances using the instance-level representation and encourages them to aggregate together. Extensive experimental evaluations show that our proposed method can outperform state-of-the-art algorithms on benchmark computer vision datasets: we improve the clustering accuracy by 6.8%, 2.8%, 4.9%, 1.3% and 0.4% on CIFAR-10, CIFAR-100, ImageNet-10, ImageNet-Dogs, and Tiny-ImageNet, respectively.