 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Flaws: A Critical Analysis of Initialization Effect on Time Series Anomaly Detection
Aug 13, 2024



Deep learning for time-series anomaly detection (TSAD) has gained significant attention over the past decade. Despite the reported improvements in several papers, the practical application of these models remains limited. Recent studies have cast doubt on these models, attributing their results to flawed evaluation techniques. However, the impact of initialization has largely been overlooked. This paper provides a critical analysis of the initialization effects on TSAD model performance. Our extensive experiments reveal that TSAD models are highly sensitive to hyperparameters such as window size, seed number, and normalization. This sensitivity often leads to significant variability in performance, which can be exploited to artificially inflate the reported efficacy of these models. We demonstrate that even minor changes in initialization parameters can result in performance variations that overshadow the claimed improvements from novel model architectures. Our findings highlight the need for rigorous evaluation protocols and transparent reporting of preprocessing steps to ensure the reliability and fairness of anomaly detection methods. This paper calls for a more cautious interpretation of TSAD advancements and encourages the development of more robust and transparent evaluation practices to advance the field and its practical applications.
C3: Cross-instance guided Contrastive Clustering
Nov 21, 2022Clustering is the task of gathering similar data samples into clusters without using any predefined labels. It has been widely studied in machine learning literature, and recent advancements in deep learning have revived interest in this field. Contrastive clustering (CC) models are a staple of deep clustering in which positive and negative pairs of each data instance are generated through data augmentation. CC models aim to learn a feature space where instance-level and cluster-level representations of positive pairs are grouped together. Despite improving the SOTA, these algorithms ignore the cross-instance patterns, which carry essential information for improving clustering performance. In this paper, we propose a novel contrastive clustering method, Cross-instance guided Contrastive Clustering (C3), that considers the cross-sample relationships to increase the number of positive pairs. In particular, we define a new loss function that identifies similar instances using the instance-level representation and encourages them to aggregate together. Extensive experimental evaluations show that our proposed method can outperform state-of-the-art algorithms on benchmark computer vision datasets: we improve the clustering accuracy by 6.8%, 2.8%, 4.9%, 1.3% and 0.4% on CIFAR-10, CIFAR-100, ImageNet-10, ImageNet-Dogs, and Tiny-ImageNet, respectively.
Self-Supervised Anomaly Detection: A Survey and Outlook
May 12, 2022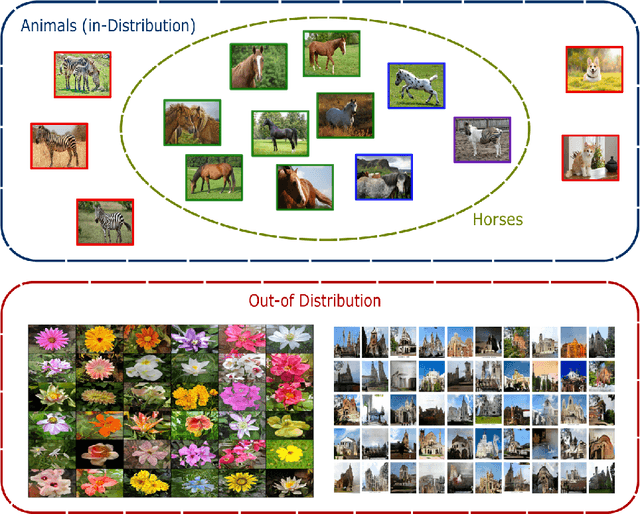


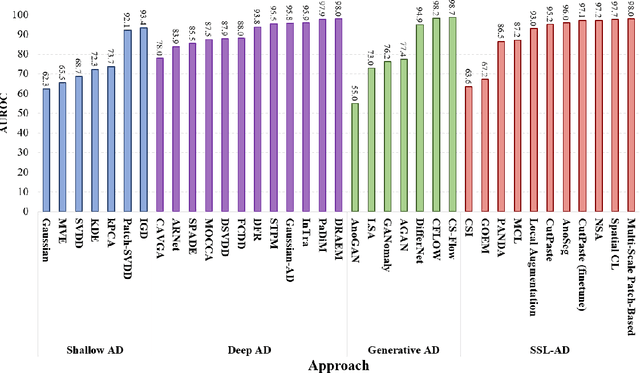
Over the past few years, anomaly detection, a subfield of machine learning that is mainly concerned with the detection of rare events, witnessed an immense improvement following the unprecedented growth of deep learning models. Recently, the emergence of self-supervised learning has sparked the development of new anomaly detection algorithms that surpassed state-of-the-art accuracy by a significant margin. This paper aims to review the current approaches in self-supervised anomaly detection. We present technical details of the common approaches and discuss their strengths and drawbacks. We also compare the performance of these models against each other and other state-of-the-art anomaly detection models. Finally, we discuss a variety of new directions for improving the existing algorithms.
DASVDD: Deep Autoencoding Support Vector Data Descriptor for Anomaly Detection
Jun 09, 2021


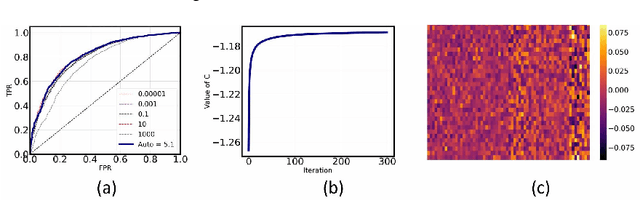
Semi-supervised anomaly detection, which aims to detect anomalies from normal samples using a model that is solely trained on normal data, has been an active field of research in the past decade. With recent advancements in deep learning, particularly generative adversarial networks and autoencoders, researchers have designed efficient deep anomaly detection methods. Existing works commonly use neural networks such as an autoencoder to map the data into a new representation that is easier to work with and then apply an anomaly detection algorithm. In this paper, we propose a method, DASVDD, that jointly learns the parameters of an autoencoder while minimizing the volume of an enclosing hyper-sphere on its latent representation. We propose a customized anomaly score which is a combination of autoencoder's reconstruction error and distance of the lower-dimensional representation of a sample from the center of the enclosing hyper-sphere. Minimizing this anomaly score on the normal data during training aids us in learning the underlying distribution of normal data. Including the reconstruction error in the anomaly score ensures that DASVDD does not suffer from the common hyper-sphere collapse issue since the proposed DASVDD model does not converge to the trivial solution of mapping all inputs to a constant point in the latent representation. Experimental evaluations on several benchmark datasets from different domains show that the proposed method outperforms most of the commonly used state-of-the-art anomaly detection algorithms while maintaining robust and accurate performance across different anomaly classes.