 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Station: An Open-World Environment for AI-Driven Discovery
Nov 09, 2025



We introduce the STATION, an open-world multi-agent environment that models a miniature scientific ecosystem. Leveraging their extended context windows, agents in the Station can engage in long scientific journeys that include reading papers from peers, formulating hypotheses, submitting code, performing analyses, and publishing results. Importantly, there is no centralized system coordinating their activities - agents are free to choose their own actions and develop their own narratives within the Station. Experiments demonstrate that AI agents in the Station achieve new state-of-the-art performance on a wide range of benchmarks, spanning from mathematics to computational biology to machine learning, notably surpassing AlphaEvolve in circle packing. A rich tapestry of narratives emerges as agents pursue independent research, interact with peers, and build upon a cumulative history. From these emergent narratives, novel methods arise organically, such as a new density-adaptive algorithm for scRNA-seq batch integration. The Station marks a first step towards autonomous scientific discovery driven by emergent behavior in an open-world environment, representing a new paradigm that moves beyond rigid optimization.
Thinker: Learning to Think Fast and Slow
May 27, 2025



Recent studies show that the reasoning capabilities of Large Language Models (LLMs) can be improved by applying Reinforcement Learning (RL) to question-answering (QA) tasks in areas such as math and coding. With a long context length, LLMs may learn to perform search, as indicated by the self-correction behavior observed in DeepSeek R1. However, this search behavior is often imprecise and lacks confidence, resulting in long, redundant responses and highlighting deficiencies in intuition and verification. Inspired by the Dual Process Theory in psychology, we introduce a simple modification to the QA task that includes four stages: Fast Thinking, where the LLM must answer within a strict token budget; Verification, where the model evaluates its initial response; Slow Thinking, where it refines the initial response with more deliberation; and Summarization, where it distills the refinement from the previous stage into precise steps. Our proposed task improves average accuracy from 24.9% to 27.9% for Qwen2.5-1.5B, and from 45.9% to 49.8% for DeepSeek-R1-Qwen-1.5B. Notably, for Qwen2.5-1.5B, the Fast Thinking mode alone achieves 26.8% accuracy using fewer than 1000 tokens, demonstrating substantial inference efficiency gains. These findings suggest that intuition and deliberative reasoning are distinct, complementary systems benefiting from targeted training.
Learning from Peers in Reasoning Models
May 12, 2025Large Reasoning Models (LRMs) have the ability to self-correct even when they make mistakes in their reasoning paths. However, our study reveals that when the reasoning process starts with a short but poor beginning, it becomes difficult for the model to recover. We refer to this phenomenon as the "Prefix Dominance Trap". Inspired by psychological findings that peer interaction can promote self-correction without negatively impacting already accurate individuals, we propose **Learning from Peers** (LeaP) to address this phenomenon. Specifically, every tokens, each reasoning path summarizes its intermediate reasoning and shares it with others through a routing mechanism, enabling paths to incorporate peer insights during inference. However, we observe that smaller models sometimes fail to follow summarization and reflection instructions effectively. To address this, we fine-tune them into our **LeaP-T** model series. Experiments on AIME 2024, AIME 2025, AIMO 2025, and GPQA Diamond show that LeaP provides substantial improvements. For instance, QwQ-32B with LeaP achieves nearly 5 absolute points higher than the baseline on average, and surpasses DeepSeek-R1-671B on three math benchmarks with an average gain of 3.3 points. Notably, our fine-tuned LeaP-T-7B matches the performance of DeepSeek-R1-Distill-Qwen-14B on AIME 2024. In-depth analysis reveals LeaP's robust error correction by timely peer insights, showing strong error tolerance and handling varied task difficulty. LeaP marks a milestone by enabling LRMs to collaborate during reasoning. Our code, datasets, and models are available at https://learning-from-peers.github.io/ .
Interpreting Emergent Planning in Model-Free Reinforcement Learning
Apr 02, 2025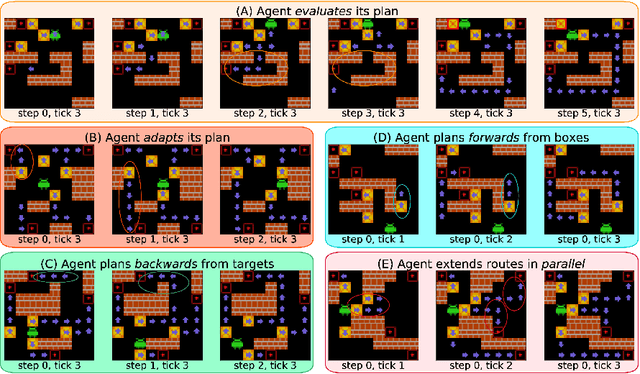


We present the first mechanistic evidence that model-free reinforcement learning agents can learn to plan. This is achieved by applying a methodology based on concept-based interpretability to a model-free agent in Sokoban -- a commonly used benchmark for studying planning. Specifically, we demonstrate that DRC, a generic model-free agent introduced by Guez et al. (2019), uses learned concept representations to internally formulate plans that both predict the long-term effects of actions on the environment and influence action selection. Our methodology involves: (1) probing for planning-relevant concepts, (2) investigating plan formation within the agent's representations, and (3) verifying that discovered plans (in the agent's representations) have a causal effect on the agent's behavior through interventions. We also show that the emergence of these plans coincides with the emergence of a planning-like property: the ability to benefit from additional test-time compute. Finally, we perform a qualitative analysis of the planning algorithm learned by the agent and discover a strong resemblance to parallelized bidirectional search. Our findings advance understanding of the internal mechanisms underlying planning behavior in agents, which is important given the recent trend of emergent planning and reasoning capabilities in LLMs through RL
Handling Delay in Real-Time Reinforcement Learning
Mar 30, 2025Real-time reinforcement learning (RL) introduces several challenges. First, policies are constrained to a fixed number of actions per second due to hardware limitations. Second, the environment may change while the network is still computing an action, leading to observational delay. The first issue can partly be addressed with pipelining, leading to higher throughput and potentially better policies. However, the second issue remains: if each neuron operates in parallel with an execution time of $\tau$, an $N$-layer feed-forward network experiences observation delay of $\tau N$. Reducing the number of layers can decrease this delay, but at the cost of the network's expressivity. In this work, we explore the trade-off between minimizing delay and network's expressivity. We present a theoretically motivated solution that leverages temporal skip connections combined with history-augmented observations. We evaluate several architectures and show that those incorporating temporal skip connections achieve strong performance across various neuron execution times, reinforcement learning algorithms, and environments, including four Mujoco tasks and all MinAtar games. Moreover, we demonstrate parallel neuron computation can accelerate inference by 6-350% on standard hardware. Our investigation into temporal skip connections and parallel computations paves the way for more efficient RL agents in real-time setting.
Learning from Failures in Multi-Attempt Reinforcement Learning
Mar 04, 2025Recent advancements in reinforcement learning (RL) for large language models (LLMs), exemplified by DeepSeek R1, have shown that even a simple question-answering task can substantially improve an LLM's reasoning capabilities. In this work, we extend this approach by modifying the task into a multi-attempt setting. Instead of generating a single response per question, the model is given multiple attempts, with feedback provided after incorrect responses. The multi-attempt task encourages the model to refine its previous attempts and improve search efficiency. Experimental results show that even a small LLM trained on a multi-attempt task achieves significantly higher accuracy when evaluated with more attempts, improving from 45.6% with 1 attempt to 52.5% with 2 attempts on the math benchmark. In contrast, the same LLM trained on a standard single-turn task exhibits only a marginal improvement, increasing from 42.3% to 43.2% when given more attempts during evaluation. The results indicate that, compared to the standard single-turn task, an LLM trained on a multi-attempt task achieves slightly better performance on math benchmarks while also learning to refine its responses more effectively based on user feedback. Full code is available at https://github.com/DualityRL/multi-attempt
Predicting Future Actions of Reinforcement Learning Agents
Oct 29, 2024


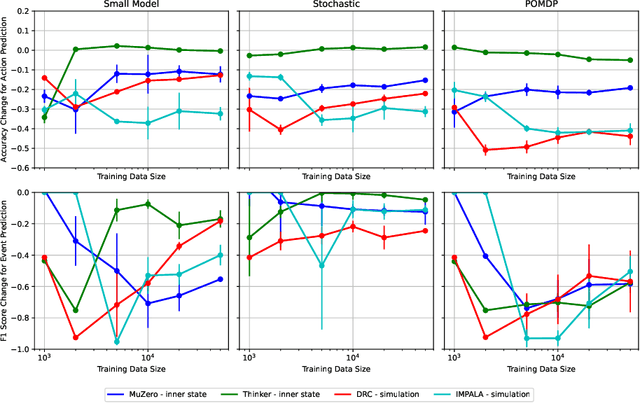
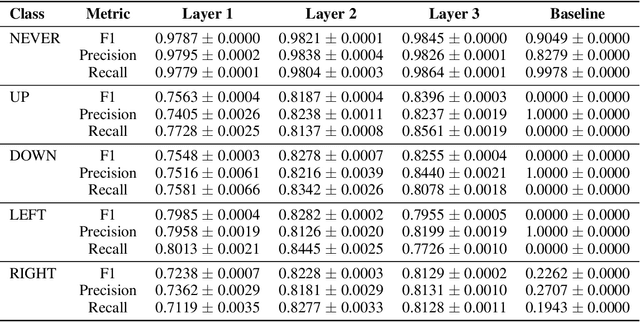
As reinforcement learning agents become increasingly deployed in real-world scenarios, predicting future agent actions and events during deployment is important for facilitating better human-agent interaction and preventing catastrophic outcomes. This paper experimentally evaluates and compares the effectiveness of future action and event prediction for three types of RL agents: explicitly planning, implicitly planning, and non-planning. We employ two approaches: the inner state approach, which involves predicting based on the inner computations of the agents (e.g., plans or neuron activations), and a simulation-based approach, which involves unrolling the agent in a learned world model. Our results show that the plans of explicitly planning agents are significantly more informative for prediction than the neuron activations of the other types. Furthermore, using internal plans proves more robust to model quality compared to simulation-based approaches when predicting actions, while the results for event prediction are more mixed. These findings highlight the benefits of leveraging inner states and simulations to predict future agent actions and events, thereby improving interaction and safety in real-world deployments.
Thinker: Learning to Plan and Act
Jul 27, 2023We propose the Thinker algorithm, a novel approach that enables reinforcement learning agents to autonomously interact with and utilize a learned world model. The Thinker algorithm wraps the environment with a world model and introduces new actions designed for interacting with the world model. These model-interaction actions enable agents to perform planning by proposing alternative plans to the world model before selecting a final action to execute in the environment. This approach eliminates the need for hand-crafted planning algorithms by enabling the agent to learn how to plan autonomously and allows for easy interpretation of the agent's plan with visualization. We demonstrate the algorithm's effectiveness through experimental results in the game of Sokoban and the Atari 2600 benchmark, where the Thinker algorithm achieves state-of-the-art performance and competitive results, respectively. Visualizations of agents trained with the Thinker algorithm demonstrate that they have learned to plan effectively with the world model to select better actions. The algorithm's generality opens a new research direction on how a world model can be used in reinforcement learning and how planning can be seamlessly integrated into an agent's decision-making process.
Structural Credit Assignment with Coordinated Exploration
Jul 25, 2023



A biologically plausible method for training an Artificial Neural Network (ANN) involves treating each unit as a stochastic Reinforcement Learning (RL) agent, thereby considering the network as a team of agents. Consequently, all units can learn via REINFORCE, a local learning rule modulated by a global reward signal, which aligns more closely with biologically observed forms of synaptic plasticity. However, this learning method tends to be slow and does not scale well with the size of the network. This inefficiency arises from two factors impeding effective structural credit assignment: (i) all units independently explore the network, and (ii) a single reward is used to evaluate the actions of all units. Accordingly, methods aimed at improving structural credit assignment can generally be classified into two categories. The first category includes algorithms that enable coordinated exploration among units, such as MAP propagation. The second category encompasses algorithms that compute a more specific reward signal for each unit within the network, like Weight Maximization and its variants. In this research report, our focus is on the first category. We propose the use of Boltzmann machines or a recurrent network for coordinated exploration. We show that the negative phase, which is typically necessary to train Boltzmann machines, can be removed. The resulting learning rules are similar to the reward-modulated Hebbian learning rule. Experimental results demonstrate that coordinated exploration significantly exceeds independent exploration in training speed for multiple stochastic and discrete units based on REINFORCE, even surpassing straight-through estimator (STE) backpropagation.
Unbiased Weight Maximization
Jul 25, 2023



A biologically plausible method for training an Artificial Neural Network (ANN) involves treating each unit as a stochastic Reinforcement Learning (RL) agent, thereby considering the network as a team of agents. Consequently, all units can learn via REINFORCE, a local learning rule modulated by a global reward signal, which aligns more closely with biologically observed forms of synaptic plasticity. Nevertheless, this learning method is often slow and scales poorly with network size due to inefficient structural credit assignment, since a single reward signal is broadcast to all units without considering individual contributions. Weight Maximization, a proposed solution, replaces a unit's reward signal with the norm of its outgoing weight, thereby allowing each hidden unit to maximize the norm of the outgoing weight instead of the global reward signal. In this research report, we analyze the theoretical properties of Weight Maximization and propose a variant, Unbiased Weight Maximization. This new approach provides an unbiased learning rule that increases learning speed and improves asymptotic performance. Notably, to our knowledge, this is the first learning rule for a network of Bernoulli-logistic units that is unbiased and scales well with the number of network's units in terms of learning speed.