 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
CoRT: Code-integrated Reasoning within Thinking
Jun 12, 2025Large Reasoning Models (LRMs) like o1 and DeepSeek-R1 have shown remarkable progress in natural language reasoning with long chain-of-thought (CoT), yet they remain inefficient or inaccurate when handling complex mathematical operations. Addressing these limitations through computational tools (e.g., computation libraries and symbolic solvers) is promising, but it introduces a technical challenge: Code Interpreter (CI) brings external knowledge beyond the model's internal text representations, thus the direct combination is not efficient. This paper introduces CoRT, a post-training framework for teaching LRMs to leverage CI effectively and efficiently. As a first step, we address the data scarcity issue by synthesizing code-integrated reasoning data through Hint-Engineering, which strategically inserts different hints at appropriate positions to optimize LRM-CI interaction. We manually create 30 high-quality samples, upon which we post-train models ranging from 1.5B to 32B parameters, with supervised fine-tuning, rejection fine-tuning and reinforcement learning. Our experimental results demonstrate that Hint-Engineering models achieve 4\% and 8\% absolute improvements on DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Qwen-1.5B respectively, across five challenging mathematical reasoning datasets. Furthermore, Hint-Engineering models use about 30\% fewer tokens for the 32B model and 50\% fewer tokens for the 1.5B model compared with the natural language models. The models and code are available at https://github.com/ChengpengLi1003/CoRT.
Learning from Peers in Reasoning Models
May 12, 2025Large Reasoning Models (LRMs) have the ability to self-correct even when they make mistakes in their reasoning paths. However, our study reveals that when the reasoning process starts with a short but poor beginning, it becomes difficult for the model to recover. We refer to this phenomenon as the "Prefix Dominance Trap". Inspired by psychological findings that peer interaction can promote self-correction without negatively impacting already accurate individuals, we propose **Learning from Peers** (LeaP) to address this phenomenon. Specifically, every tokens, each reasoning path summarizes its intermediate reasoning and shares it with others through a routing mechanism, enabling paths to incorporate peer insights during inference. However, we observe that smaller models sometimes fail to follow summarization and reflection instructions effectively. To address this, we fine-tune them into our **LeaP-T** model series. Experiments on AIME 2024, AIME 2025, AIMO 2025, and GPQA Diamond show that LeaP provides substantial improvements. For instance, QwQ-32B with LeaP achieves nearly 5 absolute points higher than the baseline on average, and surpasses DeepSeek-R1-671B on three math benchmarks with an average gain of 3.3 points. Notably, our fine-tuned LeaP-T-7B matches the performance of DeepSeek-R1-Distill-Qwen-14B on AIME 2024. In-depth analysis reveals LeaP's robust error correction by timely peer insights, showing strong error tolerance and handling varied task difficulty. LeaP marks a milestone by enabling LRMs to collaborate during reasoning. Our code, datasets, and models are available at https://learning-from-peers.github.io/ .
RealCritic: Towards Effectiveness-Driven Evaluation of Language Model Critiques
Jan 24, 2025



Critiques are important for enhancing the performance of Large Language Models (LLMs), enabling both self-improvement and constructive feedback for others by identifying flaws and suggesting improvements. However, evaluating the critique capabilities of LLMs presents a significant challenge due to the open-ended nature of the task. In this work, we introduce a new benchmark designed to assess the critique capabilities of LLMs. Unlike existing benchmarks, which typically function in an open-loop fashion, our approach employs a closed-loop methodology that evaluates the quality of corrections generated from critiques. Moreover, the benchmark incorporates features such as self-critique, cross-critique, and iterative critique, which are crucial for distinguishing the abilities of advanced reasoning models from more classical ones. We implement this benchmark using eight challenging reasoning tasks. We have several interesting findings. First, despite demonstrating comparable performance in direct chain-of-thought generation, classical LLMs significantly lag behind the advanced reasoning-based model o1-mini across all critique scenarios. Second, in self-critique and iterative critique settings, classical LLMs may even underperform relative to their baseline capabilities. We hope that this benchmark will serve as a valuable resource to guide future advancements. The code and data are available at \url{https://github.com/tangzhy/RealCritic}.
Enabling Scalable Oversight via Self-Evolving Critic
Jan 10, 2025Despite their remarkable performance, the development of Large Language Models (LLMs) faces a critical challenge in scalable oversight: providing effective feedback for tasks where human evaluation is difficult or where LLMs outperform humans. While there is growing interest in using LLMs for critique, current approaches still rely on human annotations or more powerful models, leaving the issue of enhancing critique capabilities without external supervision unresolved. We introduce SCRIT (Self-evolving CRITic), a framework that enables genuine self-evolution of critique abilities. Technically, SCRIT self-improves by training on synthetic data, generated by a contrastive-based self-critic that uses reference solutions for step-by-step critique, and a self-validation mechanism that ensures critique quality through correction outcomes. Implemented with Qwen2.5-72B-Instruct, one of the most powerful LLMs, SCRIT achieves up to a 10.3\% improvement on critique-correction and error identification benchmarks. Our analysis reveals that SCRIT's performance scales positively with data and model size, outperforms alternative approaches, and benefits critically from its self-validation component.
Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
Dec 16, 2024



This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Oct 10, 2024
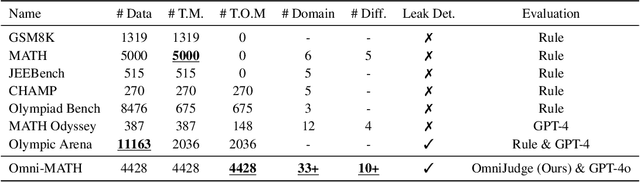

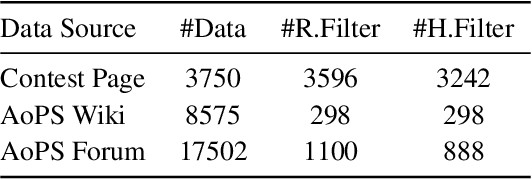
Recent advancements in large language models (LLMs) have led to significant breakthroughs in mathematical reasoning capabilities. However, existing benchmarks like GSM8K or MATH are now being solved with high accuracy (e.g., OpenAI o1 achieves 94.8% on MATH dataset), indicating their inadequacy for truly challenging these models. To bridge this gap, we propose a comprehensive and challenging benchmark specifically designed to assess LLMs' mathematical reasoning at the Olympiad level. Unlike existing Olympiad-related benchmarks, our dataset focuses exclusively on mathematics and comprises a vast collection of 4428 competition-level problems with rigorous human annotation. These problems are meticulously categorized into over 33 sub-domains and span more than 10 distinct difficulty levels, enabling a holistic assessment of model performance in Olympiad-mathematical reasoning. Furthermore, we conducted an in-depth analysis based on this benchmark. Our experimental results show that even the most advanced models, OpenAI o1-mini and OpenAI o1-preview, struggle with highly challenging Olympiad-level problems, with 60.54% and 52.55% accuracy, highlighting significant challenges in Olympiad-level mathematical reasoning.
ORLM: Training Large Language Models for Optimization Modeling
May 30, 2024



Large Language Models (LLMs) have emerged as powerful tools for tackling complex Operations Research (OR) problem by providing the capacity in automating optimization modeling. However, current methodologies heavily rely on prompt engineering (e.g., multi-agent cooperation) with proprietary LLMs, raising data privacy concerns that could be prohibitive in industry applications. To tackle this issue, we propose training open-source LLMs for optimization modeling. We identify four critical requirements for the training dataset of OR LLMs, design and implement OR-Instruct, a semi-automated process for creating synthetic data tailored to specific requirements. We also introduce the IndustryOR benchmark, the first industrial benchmark for testing LLMs on solving real-world OR problems. We apply the data from OR-Instruct to various open-source LLMs of 7b size (termed as ORLMs), resulting in a significantly improved capability for optimization modeling. Our best-performing ORLM achieves state-of-the-art performance on the NL4OPT, MAMO, and IndustryOR benchmarks. Our code and data are available at \url{https://github.com/Cardinal-Operations/ORLM}.
MathScale: Scaling Instruction Tuning for Mathematical Reasoning
Mar 05, 2024



Large language models (LLMs) have demonstrated remarkable capabilities in problem-solving. However, their proficiency in solving mathematical problems remains inadequate. We propose MathScale, a simple and scalable method to create high-quality mathematical reasoning data using frontier LLMs (e.g., {\tt GPT-3.5}). Inspired by the cognitive mechanism in human mathematical learning, it first extracts topics and knowledge points from seed math questions and then build a concept graph, which is subsequently used to generate new math questions. MathScale exhibits effective scalability along the size axis of the math dataset that we generate. As a result, we create a mathematical reasoning dataset (MathScaleQA) containing two million math question-answer pairs. To evaluate mathematical reasoning abilities of LLMs comprehensively, we construct {\sc MwpBench}, a benchmark of Math Word Problems, which is a collection of ten datasets (including GSM8K and MATH) covering K-12, college, and competition level math problems. We apply MathScaleQA to fine-tune open-source LLMs (e.g., LLaMA-2 and Mistral), resulting in significantly improved capabilities in mathematical reasoning. Evaluated on {\sc MwpBench}, MathScale-7B achieves state-of-the-art performance across all datasets, surpassing its best peers of equivalent size by 42.9\% in micro average accuracy and 43.7\% in macro average accuracy, respectively.
Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models
Feb 20, 2024We introduce Generalized Instruction Tuning (called GLAN), a general and scalable method for instruction tuning of Large Language Models (LLMs). Unlike prior work that relies on seed examples or existing datasets to construct instruction tuning data, GLAN exclusively utilizes a pre-curated taxonomy of human knowledge and capabilities as input and generates large-scale synthetic instruction data across all disciplines. Specifically, inspired by the systematic structure in human education system, we build the taxonomy by decomposing human knowledge and capabilities to various fields, sub-fields and ultimately, distinct disciplines semi-automatically, facilitated by LLMs. Subsequently, we generate a comprehensive list of subjects for every discipline and proceed to design a syllabus tailored to each subject, again utilizing LLMs. With the fine-grained key concepts detailed in every class session of the syllabus, we are able to generate diverse instructions with a broad coverage across the entire spectrum of human knowledge and skills. Extensive experiments on large language models (e.g., Mistral) demonstrate that GLAN excels in multiple dimensions from mathematical reasoning, coding, academic exams, logical reasoning to general instruction following without using task-specific training data of these tasks. In addition, GLAN allows for easy customization and new fields or skills can be added by simply incorporating a new node into our taxonomy.