 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable LLM Reasoning via Sparse Autoencoder-Based Steering
Jan 07, 2026Large Reasoning Models (LRMs) exhibit human-like cognitive reasoning strategies (e.g. backtracking, cross-verification) during reasoning process, which improves their performance on complex tasks. Currently, reasoning strategies are autonomously selected by LRMs themselves. However, such autonomous selection often produces inefficient or even erroneous reasoning paths. To make reasoning more reliable and flexible, it is important to develop methods for controlling reasoning strategies. Existing methods struggle to control fine-grained reasoning strategies due to conceptual entanglement in LRMs' hidden states. To address this, we leverage Sparse Autoencoders (SAEs) to decompose strategy-entangled hidden states into a disentangled feature space. To identify the few strategy-specific features from the vast pool of SAE features, we propose SAE-Steering, an efficient two-stage feature identification pipeline. SAE-Steering first recalls features that amplify the logits of strategy-specific keywords, filtering out over 99\% of features, and then ranks the remaining features by their control effectiveness. Using the identified strategy-specific features as control vectors, SAE-Steering outperforms existing methods by over 15\% in control effectiveness. Furthermore, controlling reasoning strategies can redirect LRMs from erroneous paths to correct ones, achieving a 7\% absolute accuracy improvement.
CoRT: Code-integrated Reasoning within Thinking
Jun 12, 2025Large Reasoning Models (LRMs) like o1 and DeepSeek-R1 have shown remarkable progress in natural language reasoning with long chain-of-thought (CoT), yet they remain inefficient or inaccurate when handling complex mathematical operations. Addressing these limitations through computational tools (e.g., computation libraries and symbolic solvers) is promising, but it introduces a technical challenge: Code Interpreter (CI) brings external knowledge beyond the model's internal text representations, thus the direct combination is not efficient. This paper introduces CoRT, a post-training framework for teaching LRMs to leverage CI effectively and efficiently. As a first step, we address the data scarcity issue by synthesizing code-integrated reasoning data through Hint-Engineering, which strategically inserts different hints at appropriate positions to optimize LRM-CI interaction. We manually create 30 high-quality samples, upon which we post-train models ranging from 1.5B to 32B parameters, with supervised fine-tuning, rejection fine-tuning and reinforcement learning. Our experimental results demonstrate that Hint-Engineering models achieve 4\% and 8\% absolute improvements on DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Qwen-1.5B respectively, across five challenging mathematical reasoning datasets. Furthermore, Hint-Engineering models use about 30\% fewer tokens for the 32B model and 50\% fewer tokens for the 1.5B model compared with the natural language models. The models and code are available at https://github.com/ChengpengLi1003/CoRT.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
START: Self-taught Reasoner with Tools
Mar 07, 2025Large reasoning models (LRMs) like OpenAI-o1 and DeepSeek-R1 have demonstrated remarkable capabilities in complex reasoning tasks through the utilization of long Chain-of-thought (CoT). However, these models often suffer from hallucinations and inefficiencies due to their reliance solely on internal reasoning processes. In this paper, we introduce START (Self-Taught Reasoner with Tools), a novel tool-integrated long CoT reasoning LLM that significantly enhances reasoning capabilities by leveraging external tools. Through code execution, START is capable of performing complex computations, self-checking, exploring diverse methods, and self-debugging, thereby addressing the limitations of LRMs. The core innovation of START lies in its self-learning framework, which comprises two key techniques: 1) Hint-infer: We demonstrate that inserting artificially designed hints (e.g., ``Wait, maybe using Python here is a good idea.'') during the inference process of a LRM effectively stimulates its ability to utilize external tools without the need for any demonstration data. Hint-infer can also serve as a simple and effective sequential test-time scaling method; 2) Hint Rejection Sampling Fine-Tuning (Hint-RFT): Hint-RFT combines Hint-infer and RFT by scoring, filtering, and modifying the reasoning trajectories with tool invocation generated by a LRM via Hint-infer, followed by fine-tuning the LRM. Through this framework, we have fine-tuned the QwQ-32B model to achieve START. On PhD-level science QA (GPQA), competition-level math benchmarks (AMC23, AIME24, AIME25), and the competition-level code benchmark (LiveCodeBench), START achieves accuracy rates of 63.6%, 95.0%, 66.7%, 47.1%, and 47.3%, respectively. It significantly outperforms the base QwQ-32B and achieves performance comparable to the state-of-the-art open-weight model R1-Distill-Qwen-32B and the proprietary model o1-Preview.
Qwen2.5 Technical Report
Dec 19, 2024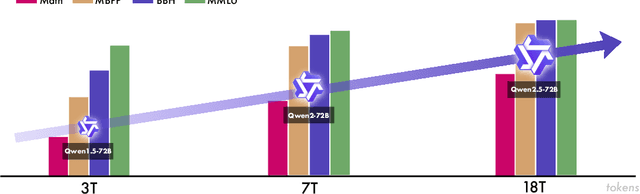

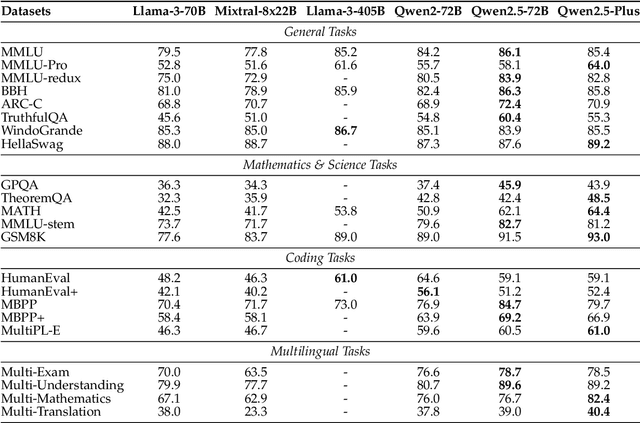
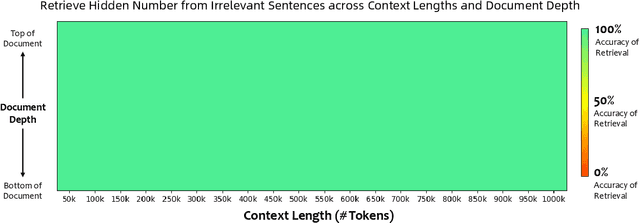
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Sep 18, 2024In this report, we present a series of math-specific large language models: Qwen2.5-Math and Qwen2.5-Math-Instruct-1.5B/7B/72B. The core innovation of the Qwen2.5 series lies in integrating the philosophy of self-improvement throughout the entire pipeline, from pre-training and post-training to inference: (1) During the pre-training phase, Qwen2-Math-Instruct is utilized to generate large-scale, high-quality mathematical data. (2) In the post-training phase, we develop a reward model (RM) by conducting massive sampling from Qwen2-Math-Instruct. This RM is then applied to the iterative evolution of data in supervised fine-tuning (SFT). With a stronger SFT model, it's possible to iteratively train and update the RM, which in turn guides the next round of SFT data iteration. On the final SFT model, we employ the ultimate RM for reinforcement learning, resulting in the Qwen2.5-Math-Instruct. (3) Furthermore, during the inference stage, the RM is used to guide sampling, optimizing the model's performance. Qwen2.5-Math-Instruct supports both Chinese and English, and possess advanced mathematical reasoning capabilities, including Chain-of-Thought (CoT) and Tool-Integrated Reasoning (TIR). We evaluate our models on 10 mathematics datasets in both English and Chinese, such as GSM8K, MATH, GaoKao, AMC23, and AIME24, covering a range of difficulties from grade school level to math competition problems.
Qwen2 Technical Report
Jul 16, 2024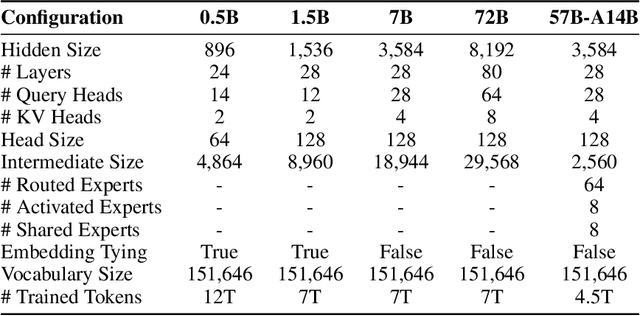
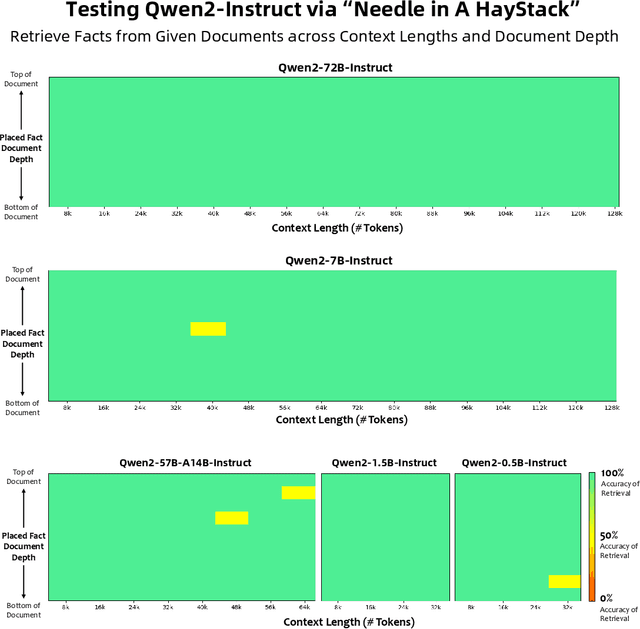
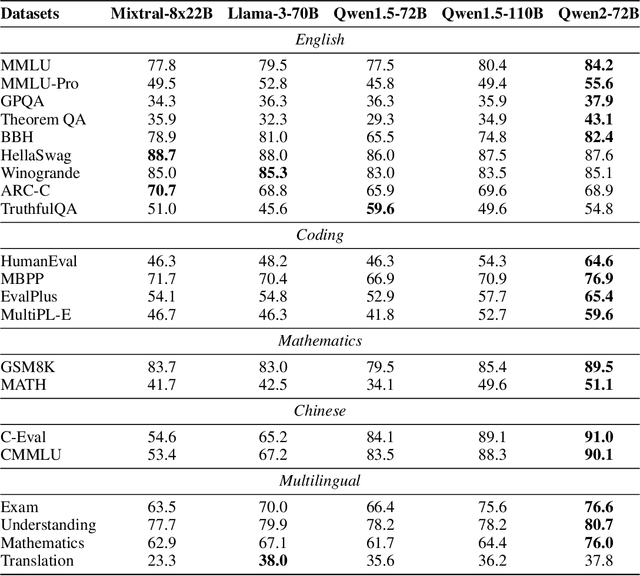
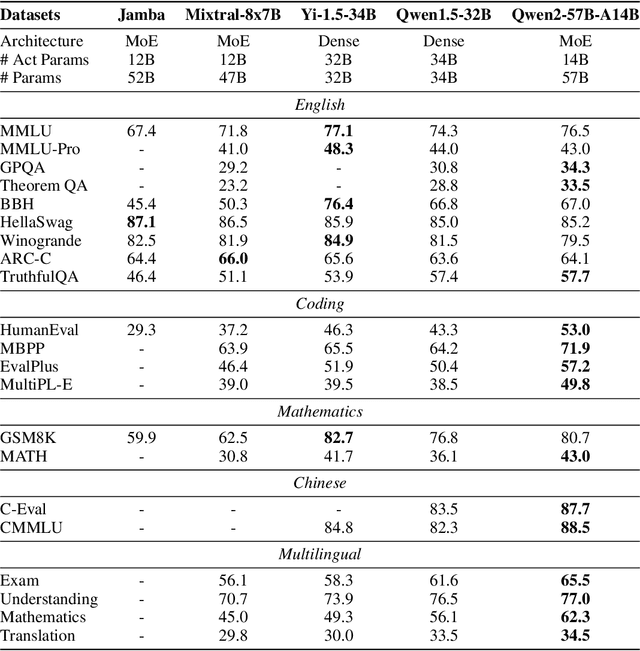
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
DotaMath: Decomposition of Thought with Code Assistance and Self-correction for Mathematical Reasoning
Jul 04, 2024Large language models (LLMs) have made impressive progress in handling simple math problems, yet they still struggle with more challenging and complex mathematical tasks. In this paper, we introduce a series of LLMs that employs the Decomposition of thought with code assistance and self-correction for mathematical reasoning, dubbed as DotaMath. DotaMath models tackle complex mathematical tasks by decomposing them into simpler logical subtasks, leveraging code to solve these subtasks, obtaining fine-grained feedback from the code interpreter, and engaging in self-reflection and correction. By annotating diverse interactive tool-use trajectories and employing query evolution on GSM8K and MATH datasets, we generate an instruction fine-tuning dataset called DotaMathQA with 574K query-response pairs. We train a series of base LLMs using imitation learning on DotaMathQA, resulting in DotaMath models that achieve remarkable performance compared to open-source LLMs across various in-domain and out-of-domain benchmarks. Notably, DotaMath-deepseek-7B showcases an outstanding performance of 64.8% on the competitive MATH dataset and 86.7% on GSM8K. Besides, DotaMath-deepseek-7B maintains strong competitiveness on a series of in-domain and out-of-domain benchmarks (Avg. 80.1%). Looking forward, we anticipate that the DotaMath paradigm will open new pathways for addressing intricate mathematical problems. Our code is publicly available at https://github.com/ChengpengLi1003/DotaMath.
OccuQuest: Mitigating Occupational Bias for Inclusive Large Language Models
Oct 25, 2023The emergence of large language models (LLMs) has revolutionized natural language processing tasks. However, existing instruction-tuning datasets suffer from occupational bias: the majority of data relates to only a few occupations, which hampers the instruction-tuned LLMs to generate helpful responses to professional queries from practitioners in specific fields. To mitigate this issue and promote occupation-inclusive LLMs, we create an instruction-tuning dataset named \emph{OccuQuest}, which contains 110,000+ prompt-completion pairs and 30,000+ dialogues covering over 1,000 occupations in 26 occupational categories. We systematically request ChatGPT, organizing queries hierarchically based on Occupation, Responsibility, Topic, and Question, to ensure a comprehensive coverage of occupational specialty inquiries. By comparing with three commonly used datasets (Dolly, ShareGPT, and WizardLM), we observe that OccuQuest exhibits a more balanced distribution across occupations. Furthermore, we assemble three test sets for comprehensive evaluation, an occu-test set covering 25 occupational categories, an estate set focusing on real estate, and an occu-quora set containing real-world questions from Quora. We then fine-tune LLaMA on OccuQuest to obtain OccuLLaMA, which significantly outperforms state-of-the-art LLaMA variants (Vicuna, Tulu, and WizardLM) on professional questions in GPT-4 and human evaluations. Notably, on the occu-quora set, OccuLLaMA reaches a high win rate of 86.4\% against WizardLM.
How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition
Oct 09, 2023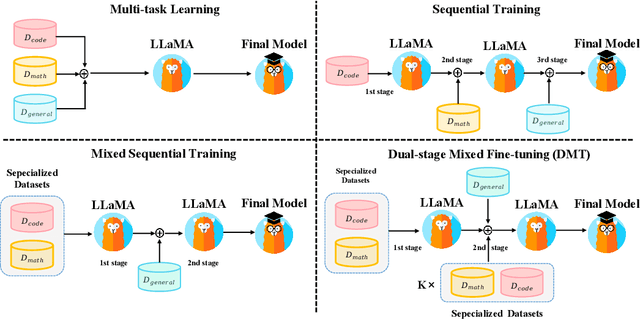
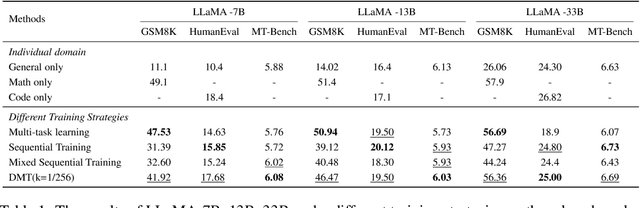
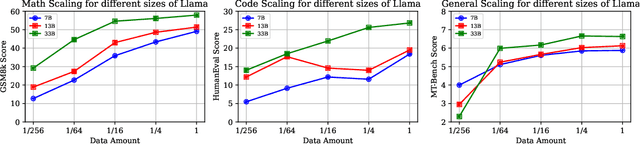
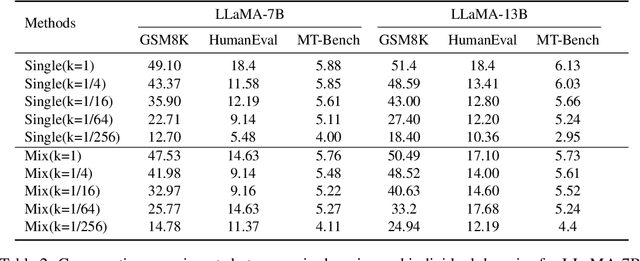
Large language models (LLMs) with enormous pre-training tokens and parameter amounts emerge abilities, including math reasoning, code generation, and instruction following. These abilities are further enhanced by supervised fine-tuning (SFT). The open-source community has studied on ad-hoc SFT for each ability, while proprietary LLMs are versatile for all abilities. It is important to investigate how to unlock them with multiple abilities via SFT. In this study, we specifically focus on the data composition between mathematical reasoning, code generation, and general human-aligning abilities during SFT. From a scaling perspective, we investigate the relationship between model abilities and various factors including data amounts, data composition ratio, model parameters, and SFT strategies. Our experiments reveal that different abilities exhibit different scaling patterns, and larger models generally show superior performance with the same amount of data. Mathematical reasoning and code generation improve as data amounts increase consistently, while the general ability is enhanced with about a thousand samples and improves slowly. We find data composition results in various abilities improvements with low data amounts, while conflicts of abilities with high data amounts. Our experiments further show that composition data amount impacts performance, while the influence of composition ratio is insignificant. Regarding the SFT strategies, we evaluate sequential learning multiple abilities are prone to catastrophic forgetting. Our proposed Dual-stage Mixed Fine-tuning (DMT) strategy learns specialized abilities first and then learns general abilities with a small amount of specialized data to prevent forgetting, offering a promising solution to learn multiple abilities with different scaling patterns.