 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: A Unified Rollout Budget Allocation Framework for Efficient Agentic Reinforcement Learning
Jun 09, 2026Reinforcement learning with verifiable rewards (RLVR) is a promising approach for enhancing reasoning and agentic behavior in large language models. However, rollout-intensive policy optimization is often limited by insufficient reward contrast, arising when overly simple or complex prompts generate low-variance feedback and when outcome-only rewards assign the same terminal assessment to every decision in a multi-turn rollout. Past efforts have focused on allocating available rollout resources to promising prompts, yet they only leverage sample informativeness at the prompt level and neglect variation in prefix-level informativeness across turns within the same rollout. This work targets multi-turn agentic RL by modeling each ReAct-style thought-action-observation turn as a semantically distinct node, allowing budget allocation to extend from prompt roots to turn-level prefixes with further continuations, which naturally forms tree-structured rollouts. We introduce Tree Rollout Allocation for Contrastive Exploration (TRACE), a unified rollout allocation framework that enhances reward contrast within a fixed sampling budget. Technically, TRACE allocates rollout budget to both prompt roots and intermediate prefixes that are most likely to yield mixed terminal rewards. A shared generalizable predictor estimates conditional success probability at these anchors from prefix histories to guide this allocation. The resulting adaptive tree structure enriches outcome-only feedback and amplifies the policy-update signal. Empirically, TRACE achieves competitive performance and efficiency gains on typical agentic benchmarks, e.g., improving Qwen3-14B Multi-Hop QA average accuracy by 2.8 points over competitive baselines at equal sampling cost.
Momentum for Reasoning: Dense Intrinsic Signals in Policy Optimization
Jun 07, 2026Reinforcement learning with verifiable rewards (RLVR) has emerged as a powerful paradigm for eliciting long-chain reasoning in large language models. However, existing methods based on Group Relative Policy Optimization (GRPO) rely on a binary outcome reward, which induces two structural failure modes: Zero-Advantage Collapse, in which all rollouts in a group share the same outcome and the gradient vanishes, and Hallucinated Certainty, in which the model becomes increasingly confident on incorrect rollouts late in training. We address both modes by densifying the reward with intrinsic signals computed entirely from the policy's own conditional probabilities, and propose ISPO (Intrinsic Signal Policy Optimization, which combines a sequence-level signal measuring how informative the thinking trajectory is for the final answer, with a token-level directional reward whose hallucinated-certainty hinge penalizes confidently-wrong predictions at critical decision tokens. Across three base models and five mathematical reasoning benchmarks, ISPO consistently outperforms competitive baselines, with the largest gains on the hardest benchmarks where zero-advantage collapse is most frequent, and training-dynamics diagnostics confirm that both failure modes are decreased.
From "Weak" Signals to Strong Models: Preference Delta Aggregation with LoRA Merging
May 29, 2026Training strong large language models (LLMs) requires high-quality supervision, which is often scarce. Recent work shows that paired preference data from weak-weaker model pairs (e.g., Qwen3 4B over 1.7B), despite the limited quality of individual responses, can provide an effective supervision signal through relative quality deltas, which we term a "weak" signal. This motivates a key research question: can multiple "weak" signals be constructively aggregated for improving strong models (e.g., Qwen3 8B)? To this end, we propose Preference Delta Aggregation (PDA), the first framework that derives a preference delta from each weak-weaker model pair, instantiates it as a LoRA adapter learned through preference optimization, and aggregates the resulting deltas via LoRA merging. To further mitigate directional interference during LoRA merging, we introduce Geometric Alignment Merging (GAM), a geometry-aware merging method that aligns adapter subspaces before aggregation, enabling more robust composition of diverse deltas. Evaluations on knowledge reasoning and agentic search benchmarks show that aggregating multiple "weak" signals pushes performance beyond any single signal, with further gains as additional signals are incorporated. Correspondingly, PDA with GAM improves the strong model by 6.8 and 7.3 points on average for knowledge reasoning and agentic search, respectively. It outperforms all single-delta and multi-delta baselines, exceeding the best single-delta baseline by 2.1 and 4.3 points. Further analysis attributes these gains to the effective composition of complementary capabilities encoded across distinct preference deltas.
Optimsyn: Influence-Guided Rubrics Optimization for Synthetic Data Generation
Apr 01, 2026Large language models (LLMs) achieve strong downstream performance largely due to abundant supervised fine-tuning (SFT) data. However, high-quality SFT data in knowledge-intensive domains such as humanities, social sciences, medicine, law, and finance is scarce because expert curation is expensive, privacy constraints are strict, and label consistency is hard to ensure. Recent work uses synthetic data, typically by prompting a generator over domain documents and filtering outputs with handcrafted rubrics. Yet rubric design is expert-dependent, transfers poorly across domains, and is often optimized through a brittle heuristic loop of writing rubrics, synthesizing data, training, inspecting results, and manually guessing revisions. This process lacks reliable quantitative feedback about how a rubric affects downstream performance. We propose evaluating synthetic data by its training utility on the target model and using this signal to guide data generation. Inspired by influence estimation, we adopt an optimizer-aware estimator that uses gradient information to quantify each synthetic sample's contribution to a target model's objective on specific tasks. Our analysis shows that even when synthetic and real samples are close in embedding space, their influence on learning can differ substantially. Based on this insight, we propose an optimization-based framework that adapts rubrics using target-model feedback. We provide lightweight guiding text and use a rubric-specialized model to generate task-conditioned rubrics. Influence score is used as the reward to optimize the rubric generator with reinforcement learning. Experiments across domains, target models, and data generators show consistent improvements and strong generalization without task-specific tuning.
DataMan: Data Manager for Pre-training Large Language Models
Feb 26, 2025The performance emergence of large language models (LLMs) driven by data scaling laws makes the selection of pre-training data increasingly important. However, existing methods rely on limited heuristics and human intuition, lacking comprehensive and clear guidelines. To address this, we are inspired by ``reverse thinking'' -- prompting LLMs to self-identify which criteria benefit its performance. As its pre-training capabilities are related to perplexity (PPL), we derive 14 quality criteria from the causes of text perplexity anomalies and introduce 15 common application domains to support domain mixing. In this paper, we train a Data Manager (DataMan) to learn quality ratings and domain recognition from pointwise rating, and use it to annotate a 447B token pre-training corpus with 14 quality ratings and domain type. Our experiments validate our approach, using DataMan to select 30B tokens to train a 1.3B-parameter language model, demonstrating significant improvements in in-context learning (ICL), perplexity, and instruction-following ability over the state-of-the-art baseline. The best-performing model, based on the Overall Score l=5 surpasses a model trained with 50% more data using uniform sampling. We continue pre-training with high-rated, domain-specific data annotated by DataMan to enhance domain-specific ICL performance and thus verify DataMan's domain mixing ability. Our findings emphasize the importance of quality ranking, the complementary nature of quality criteria, and their low correlation with perplexity, analyzing misalignment between PPL and ICL performance. We also thoroughly analyzed our pre-training dataset, examining its composition, the distribution of quality ratings, and the original document sources.
Predicting Rewards Alongside Tokens: Non-disruptive Parameter Insertion for Efficient Inference Intervention in Large Language Model
Aug 20, 2024



Transformer-based large language models (LLMs) exhibit limitations such as generating unsafe responses, unreliable reasoning, etc. Existing inference intervention approaches attempt to mitigate these issues by finetuning additional models to produce calibration signals (such as rewards) that guide the LLM's decoding process. However, this solution introduces substantial time and space overhead due to the separate models required. This work proposes Non-disruptive parameters insertion (Otter), inserting extra parameters into the transformer architecture to predict calibration signals along with the original LLM output. Otter offers state-of-the-art performance on multiple demanding tasks while saving up to 86.5\% extra space and 98.5\% extra time. Furthermore, Otter seamlessly integrates with existing inference engines, requiring only a one-line code change, and the original model response remains accessible after the parameter insertion. Our code is publicly available at \url{https://github.com/chenhan97/Otter}
Qwen2 Technical Report
Jul 16, 2024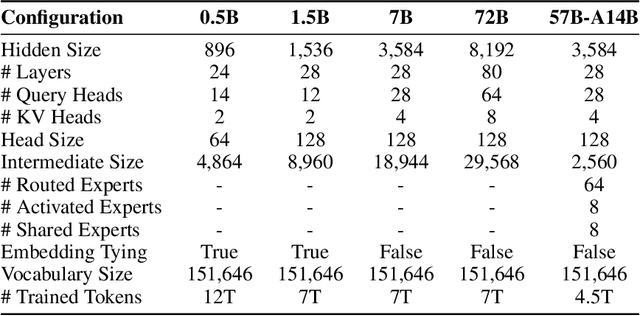
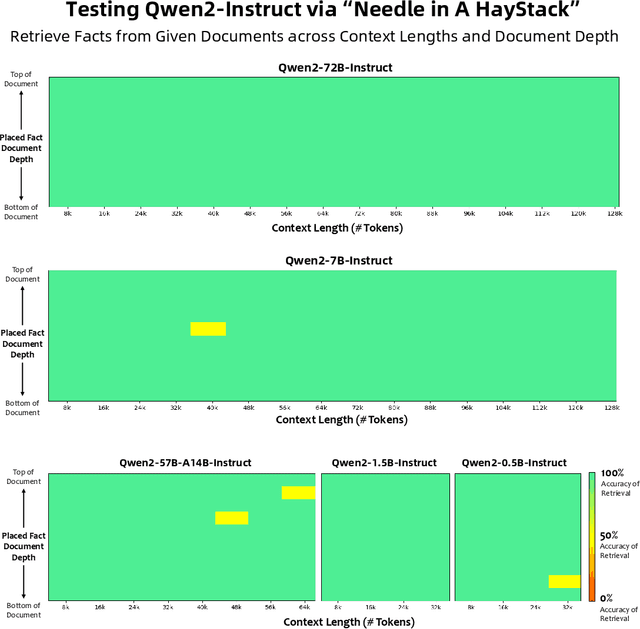
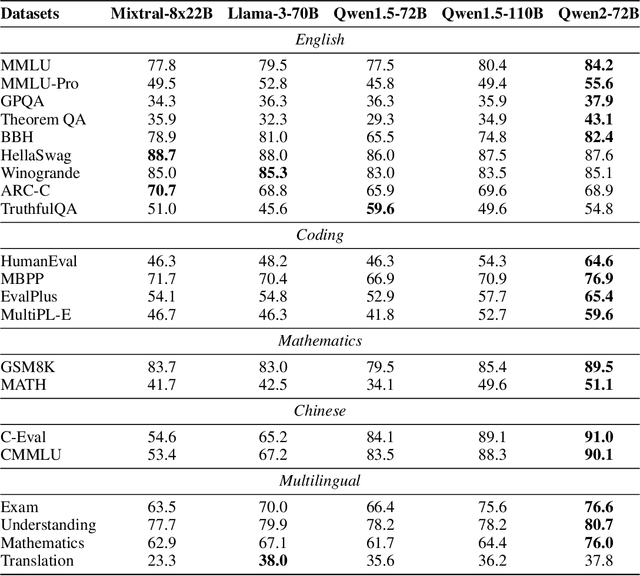
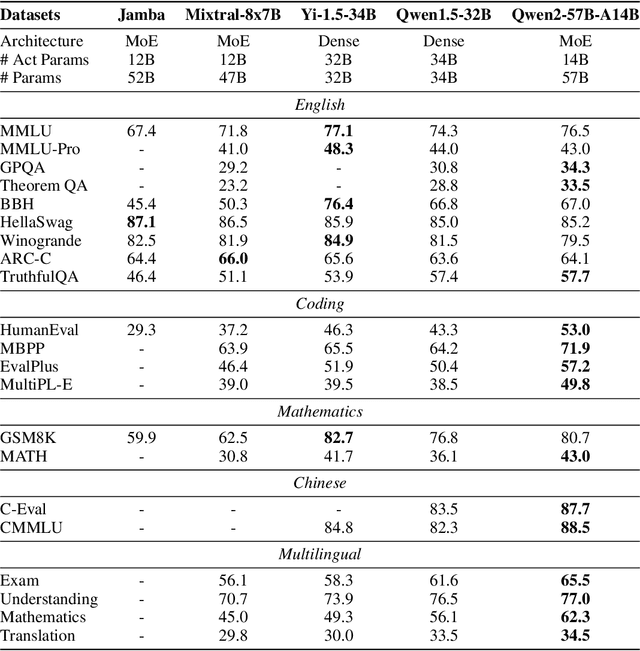
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
DotaMath: Decomposition of Thought with Code Assistance and Self-correction for Mathematical Reasoning
Jul 04, 2024Large language models (LLMs) have made impressive progress in handling simple math problems, yet they still struggle with more challenging and complex mathematical tasks. In this paper, we introduce a series of LLMs that employs the Decomposition of thought with code assistance and self-correction for mathematical reasoning, dubbed as DotaMath. DotaMath models tackle complex mathematical tasks by decomposing them into simpler logical subtasks, leveraging code to solve these subtasks, obtaining fine-grained feedback from the code interpreter, and engaging in self-reflection and correction. By annotating diverse interactive tool-use trajectories and employing query evolution on GSM8K and MATH datasets, we generate an instruction fine-tuning dataset called DotaMathQA with 574K query-response pairs. We train a series of base LLMs using imitation learning on DotaMathQA, resulting in DotaMath models that achieve remarkable performance compared to open-source LLMs across various in-domain and out-of-domain benchmarks. Notably, DotaMath-deepseek-7B showcases an outstanding performance of 64.8% on the competitive MATH dataset and 86.7% on GSM8K. Besides, DotaMath-deepseek-7B maintains strong competitiveness on a series of in-domain and out-of-domain benchmarks (Avg. 80.1%). Looking forward, we anticipate that the DotaMath paradigm will open new pathways for addressing intricate mathematical problems. Our code is publicly available at https://github.com/ChengpengLi1003/DotaMath.
Inference-Time Decontamination: Reusing Leaked Benchmarks for Large Language Model Evaluation
Jun 20, 2024
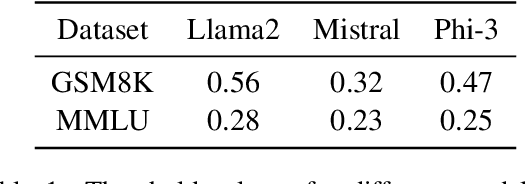


The training process of large language models (LLMs) often involves varying degrees of test data contamination. Although current LLMs are achieving increasingly better performance on various benchmarks, their performance in practical applications does not always match their benchmark results. Leakage of benchmarks can prevent the accurate assessment of LLMs' true performance. However, constructing new benchmarks is costly, labor-intensive and still carries the risk of leakage. Therefore, in this paper, we ask the question, Can we reuse these leaked benchmarks for LLM evaluation? We propose Inference-Time Decontamination (ITD) to address this issue by detecting and rewriting leaked samples without altering their difficulties. ITD can mitigate performance inflation caused by memorizing leaked benchmarks. Our proof-of-concept experiments demonstrate that ITD reduces inflated accuracy by 22.9% on GSM8K and 19.0% on MMLU. On MMLU, using Inference-time Decontamination can lead to a decrease in the results of Phi3 and Mistral by 6.7% and 3.6% respectively. We hope that ITD can provide more truthful evaluation results for large language models.
DORY: Deliberative Prompt Recovery for LLM
May 31, 2024Prompt recovery in large language models (LLMs) is crucial for understanding how LLMs work and addressing concerns regarding privacy, copyright, etc. The trend towards inference-only APIs complicates this task by restricting access to essential outputs for recovery. To tackle this challenge, we extract prompt-related information from limited outputs and identify a strong(negative) correlation between output probability-based uncertainty and the success of prompt recovery. This finding led to the development of Deliberative PrOmpt RecoverY (DORY), our novel approach that leverages uncertainty to recover prompts accurately. DORY involves reconstructing drafts from outputs, refining these with hints, and filtering out noise based on uncertainty. Our evaluation across diverse LLMs and prompt benchmarks shows that DORY outperforms existing baselines, improving performance by approximately 10.82% and establishing a new state-of-the-art record in prompt recovery tasks. Significantly, DORY operates using a single LLM without any external resources or model, offering a cost-effective, user-friendly prompt recovery solution.