 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAME: Contrastive Automated Model Evaluation
Paper and Code

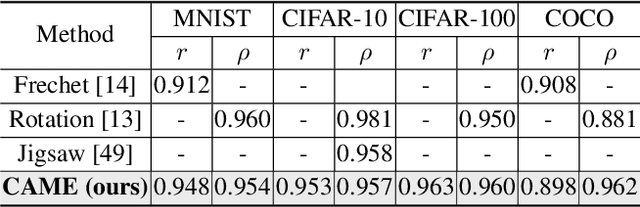

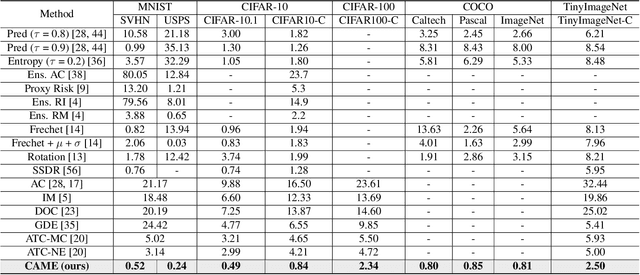
The Automated Model Evaluation (AutoEval) framework entertains the possibility of evaluating a trained machine learning model without resorting to a labeled testing set. Despite the promise and some decent results, the existing AutoEval methods heavily rely on computing distribution shifts between the unlabelled testing set and the training set. We believe this reliance on the training set becomes another obstacle in shipping this technology to real-world ML development. In this work, we propose Contrastive Automatic Model Evaluation (CAME), a novel AutoEval framework that is rid of involving training set in the loop. The core idea of CAME bases on a theoretical analysis which bonds the model performance with a contrastive loss. Further, with extensive empirical validation, we manage to set up a predictable relationship between the two, simply by deducing on the unlabeled/unseen testing set. The resulting framework CAME establishes a new SOTA results for AutoEval by surpassing prior work significantly.