 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Preserving Safety in Fine-Tuned LLMs
Jan 15, 2026Fine-tuning is an essential and pervasive functionality for applying large language models (LLMs) to downstream tasks. However, it has the potential to substantially degrade safety alignment, e.g., by greatly increasing susceptibility to jailbreak attacks, even when the fine-tuning data is entirely harmless. Despite garnering growing attention in defense efforts during the fine-tuning stage, existing methods struggle with a persistent safety-utility dilemma: emphasizing safety compromises task performance, whereas prioritizing utility typically requires deep fine-tuning that inevitably leads to steep safety declination. In this work, we address this dilemma by shedding new light on the geometric interaction between safety- and utility-oriented gradients in safety-aligned LLMs. Through systematic empirical analysis, we uncover three key insights: (I) safety gradients lie in a low-rank subspace, while utility gradients span a broader high-dimensional space; (II) these subspaces are often negatively correlated, causing directional conflicts during fine-tuning; and (III) the dominant safety direction can be efficiently estimated from a single sample. Building upon these novel insights, we propose safety-preserving fine-tuning (SPF), a lightweight approach that explicitly removes gradient components conflicting with the low-rank safety subspace. Theoretically, we show that SPF guarantees utility convergence while bounding safety drift. Empirically, SPF consistently maintains downstream task performance and recovers nearly all pre-trained safety alignment, even under adversarial fine-tuning scenarios. Furthermore, SPF exhibits robust resistance to both deep fine-tuning and dynamic jailbreak attacks. Together, our findings provide new mechanistic understanding and practical guidance toward always-aligned LLM fine-tuning.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
SafeCoT: Improving VLM Safety with Minimal Reasoning
Jun 11, 2025Ensuring safe and appropriate responses from vision-language models (VLMs) remains a critical challenge, particularly in high-risk or ambiguous scenarios. We introduce SafeCoT, a lightweight, interpretable framework that leverages rule-based chain-of-thought (CoT) supervision to improve refusal behavior in VLMs. Unlike prior methods that rely on large-scale safety annotations or complex modeling, SafeCoT uses minimal supervision to help models reason about safety risks and make context-aware refusals. Experiments across multiple benchmarks show that SafeCoT significantly reduces overrefusal and enhances generalization, even with limited training data. Our approach offers a scalable solution for aligning VLMs with safety-critical objectives.
A Comparative Study on Reasoning Patterns of OpenAI's o1 Model
Oct 17, 2024



Enabling Large Language Models (LLMs) to handle a wider range of complex tasks (e.g., coding, math) has drawn great attention from many researchers. As LLMs continue to evolve, merely increasing the number of model parameters yields diminishing performance improvements and heavy computational costs. Recently, OpenAI's o1 model has shown that inference strategies (i.e., Test-time Compute methods) can also significantly enhance the reasoning capabilities of LLMs. However, the mechanisms behind these methods are still unexplored. In our work, to investigate the reasoning patterns of o1, we compare o1 with existing Test-time Compute methods (BoN, Step-wise BoN, Agent Workflow, and Self-Refine) by using OpenAI's GPT-4o as a backbone on general reasoning benchmarks in three domains (i.e., math, coding, commonsense reasoning). Specifically, first, our experiments show that the o1 model has achieved the best performance on most datasets. Second, as for the methods of searching diverse responses (e.g., BoN), we find the reward models' capability and the search space both limit the upper boundary of these methods. Third, as for the methods that break the problem into many sub-problems, the Agent Workflow has achieved better performance than Step-wise BoN due to the domain-specific system prompt for planning better reasoning processes. Fourth, it is worth mentioning that we have summarized six reasoning patterns of o1, and provided a detailed analysis on several reasoning benchmarks.
Jailbreaking Prompt Attack: A Controllable Adversarial Attack against Diffusion Models
Apr 02, 2024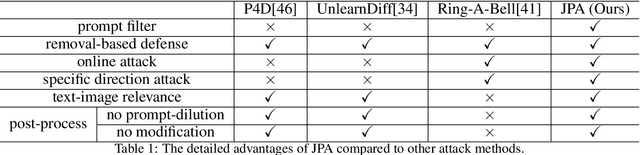



The fast advance of the image generation community has attracted attention worldwide. The safety issue needs to be further scrutinized and studied. There have been a few works around this area mostly achieving a post-processing design, model-specific, or yielding suboptimal image quality generation. Despite that, in this article, we discover a black-box attack method that enjoys three merits. It enables (i)-attacks both directed and semantic-driven that theoretically and practically pose a hazard to this vast user community, (ii)-surprisingly surpasses the white-box attack in a black-box manner and (iii)-without requiring any post-processing effort. Core to our approach is inspired by the concept guidance intriguing property of Classifier-Free guidance (CFG) in T2I models, and we discover that conducting frustratingly simple guidance in the CLIP embedding space, coupled with the semantic loss and an additionally sensitive word list works very well. Moreover, our results expose and highlight the vulnerabilities in existing defense mechanisms.
CAME: Contrastive Automated Model Evaluation
Aug 22, 2023
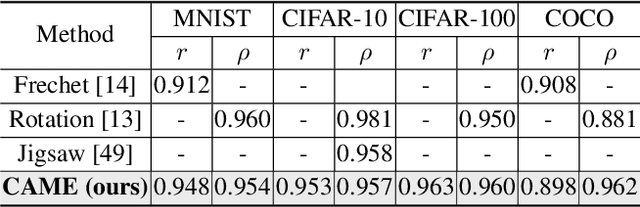

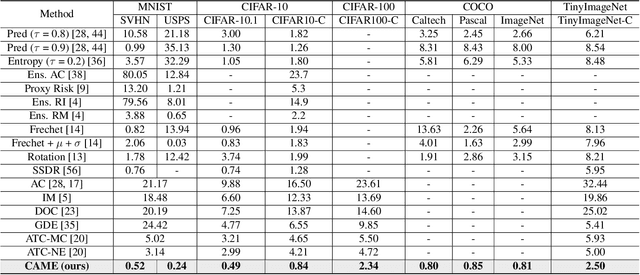
The Automated Model Evaluation (AutoEval) framework entertains the possibility of evaluating a trained machine learning model without resorting to a labeled testing set. Despite the promise and some decent results, the existing AutoEval methods heavily rely on computing distribution shifts between the unlabelled testing set and the training set. We believe this reliance on the training set becomes another obstacle in shipping this technology to real-world ML development. In this work, we propose Contrastive Automatic Model Evaluation (CAME), a novel AutoEval framework that is rid of involving training set in the loop. The core idea of CAME bases on a theoretical analysis which bonds the model performance with a contrastive loss. Further, with extensive empirical validation, we manage to set up a predictable relationship between the two, simply by deducing on the unlabeled/unseen testing set. The resulting framework CAME establishes a new SOTA results for AutoEval by surpassing prior work significantly.