 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreaking Prompt Attack: A Controllable Adversarial Attack against Diffusion Models
Apr 02, 2024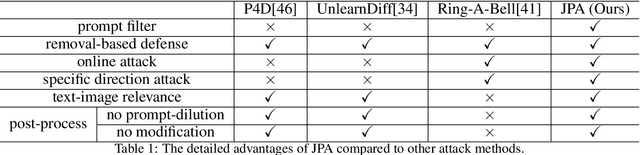



The fast advance of the image generation community has attracted attention worldwide. The safety issue needs to be further scrutinized and studied. There have been a few works around this area mostly achieving a post-processing design, model-specific, or yielding suboptimal image quality generation. Despite that, in this article, we discover a black-box attack method that enjoys three merits. It enables (i)-attacks both directed and semantic-driven that theoretically and practically pose a hazard to this vast user community, (ii)-surprisingly surpasses the white-box attack in a black-box manner and (iii)-without requiring any post-processing effort. Core to our approach is inspired by the concept guidance intriguing property of Classifier-Free guidance (CFG) in T2I models, and we discover that conducting frustratingly simple guidance in the CLIP embedding space, coupled with the semantic loss and an additionally sensitive word list works very well. Moreover, our results expose and highlight the vulnerabilities in existing defense mechanisms.