 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow Deep Learning Can Still Excel in Fine-Grained Few-Shot Learning
Jul 29, 2025Deep learning has witnessed the extensive utilization across a wide spectrum of domains, including fine-grained few-shot learning (FGFSL) which heavily depends on deep backbones. Nonetheless, shallower deep backbones such as ConvNet-4, are not commonly preferred because they're prone to extract a larger quantity of non-abstract visual attributes. In this paper, we initially re-evaluate the relationship between network depth and the ability to fully encode few-shot instances, and delve into whether shallow deep architecture could effectuate comparable or superior performance to mainstream deep backbone. Fueled by the inspiration from vanilla ConvNet-4, we introduce a location-aware constellation network (LCN-4), equipped with a cutting-edge location-aware feature clustering module. This module can proficiently encoder and integrate spatial feature fusion, feature clustering, and recessive feature location, thereby significantly minimizing the overall loss. Specifically, we innovatively put forward a general grid position encoding compensation to effectively address the issue of positional information missing during the feature extraction process of specific ordinary convolutions. Additionally, we further propose a general frequency domain location embedding technique to offset for the location loss in clustering features. We have carried out validation procedures on three representative fine-grained few-shot benchmarks. Relevant experiments have established that LCN-4 notably outperforms the ConvNet-4 based State-of-the-Arts and achieves performance that is on par with or superior to most ResNet12-based methods, confirming the correctness of our conjecture.
RealHiTBench: A Comprehensive Realistic Hierarchical Table Benchmark for Evaluating LLM-Based Table Analysis
Jun 16, 2025With the rapid advancement of Large Language Models (LLMs), there is an increasing need for challenging benchmarks to evaluate their capabilities in handling complex tabular data. However, existing benchmarks are either based on outdated data setups or focus solely on simple, flat table structures. In this paper, we introduce RealHiTBench, a comprehensive benchmark designed to evaluate the performance of both LLMs and Multimodal LLMs (MLLMs) across a variety of input formats for complex tabular data, including LaTeX, HTML, and PNG. RealHiTBench also includes a diverse collection of tables with intricate structures, spanning a wide range of task types. Our experimental results, using 25 state-of-the-art LLMs, demonstrate that RealHiTBench is indeed a challenging benchmark. Moreover, we also develop TreeThinker, a tree-based pipeline that organizes hierarchical headers into a tree structure for enhanced tabular reasoning, validating the importance of improving LLMs' perception of table hierarchies. We hope that our work will inspire further research on tabular data reasoning and the development of more robust models. The code and data are available at https://github.com/cspzyy/RealHiTBench.
DQO-MAP: Dual Quadrics Multi-Object mapping with Gaussian Splatting
Mar 04, 2025Accurate object perception is essential for robotic applications such as object navigation. In this paper, we propose DQO-MAP, a novel object-SLAM system that seamlessly integrates object pose estimation and reconstruction. We employ 3D Gaussian Splatting for high-fidelity object reconstruction and leverage quadrics for precise object pose estimation. Both of them management is handled on the CPU, while optimization is performed on the GPU, significantly improving system efficiency. By associating objects with unique IDs, our system enables rapid object extraction from the scene. Extensive experimental results on object reconstruction and pose estimation demonstrate that DQO-MAP achieves outstanding performance in terms of precision, reconstruction quality, and computational efficiency. The code and dataset are available at: https://github.com/LiHaoy-ux/DQO-MAP.
MLINE-VINS: Robust Monocular Visual-Inertial SLAM With Flow Manhattan and Line Features
Mar 03, 2025



In this paper we introduce MLINE-VINS, a novel monocular visual-inertial odometry (VIO) system that leverages line features and Manhattan Word assumption. Specifically, for line matching process, we propose a novel geometric line optical flow algorithm that efficiently tracks line features with varying lengths, whitch is do not require detections and descriptors in every frame. To address the instability of Manhattan estimation from line features, we propose a tracking-by-detection module that consistently tracks and optimizes Manhattan framse in consecutive images. By aligning the Manhattan World with the VIO world frame, the tracking could restart using the latest pose from back-end, simplifying the coordinate transformations within the system. Furthermore, we implement a mechanism to validate Manhattan frames and a novel global structural constraints back-end optimization. Extensive experiments results on vairous datasets, including benchmark and self-collected datasets, show that the proposed approach outperforms existing methods in terms of accuracy and long-range robustness. The source code of our method is available at: https://github.com/LiHaoy-ux/MLINE-VINS.
TDCNet: Transparent Objects Depth Completion with CNN-Transformer Dual-Branch Parallel Network
Dec 19, 2024



The sensing and manipulation of transparent objects present a critical challenge in industrial and laboratory robotics. Conventional sensors face challenges in obtaining the full depth of transparent objects due to the refraction and reflection of light on their surfaces and their lack of visible texture. Previous research has attempted to obtain complete depth maps of transparent objects from RGB and damaged depth maps (collected by depth sensor) using deep learning models. However, existing methods fail to fully utilize the original depth map, resulting in limited accuracy for deep completion. To solve this problem, we propose TDCNet, a novel dual-branch CNN-Transformer parallel network for transparent object depth completion. The proposed framework consists of two different branches: one extracts features from partial depth maps, while the other processes RGB-D images. Experimental results demonstrate that our model achieves state-of-the-art performance across multiple public datasets. Our code and the pre-trained model are publicly available at https://github.com/XianghuiFan/TDCNet.
Depth-PC: A Visual Servo Framework Integrated with Cross-Modality Fusion for Sim2Real Transfer
Nov 26, 2024



Visual servo techniques guide robotic motion using visual information to accomplish manipulation tasks, requiring high precision and robustness against noise. Traditional methods often require prior knowledge and are susceptible to external disturbances. Learning-driven alternatives, while promising, frequently struggle with the scarcity of training data and fall short in generalization. To address these challenges, we propose a novel visual servo framework Depth-PC that leverages simulation training and exploits semantic and geometric information of keypoints from images, enabling zero-shot transfer to real-world servo tasks. Our framework focuses on the servo controller which intertwines keypoint feature queries and relative depth information. Subsequently, the fused features from these two modalities are then processed by a Graph Neural Network to establish geometric and semantic correspondence between keypoints and update the robot state. Through simulation and real-world experiments, our approach demonstrates superior convergence basin and accuracy compared to state-of-the-art methods, fulfilling the requirements for robotic servo tasks while enabling zero-shot application to real-world scenarios. In addition to the enhancements achieved with our proposed framework, we have also substantiated the efficacy of cross-modality feature fusion within the realm of servo tasks.
TableGPT2: A Large Multimodal Model with Tabular Data Integration
Nov 04, 2024The emergence of models like GPTs, Claude, LLaMA, and Qwen has reshaped AI applications, presenting vast new opportunities across industries. Yet, the integration of tabular data remains notably underdeveloped, despite its foundational role in numerous real-world domains. This gap is critical for three main reasons. First, database or data warehouse data integration is essential for advanced applications; second, the vast and largely untapped resource of tabular data offers immense potential for analysis; and third, the business intelligence domain specifically demands adaptable, precise solutions that many current LLMs may struggle to provide. In response, we introduce TableGPT2, a model rigorously pre-trained and fine-tuned with over 593.8K tables and 2.36M high-quality query-table-output tuples, a scale of table-related data unprecedented in prior research. This extensive training enables TableGPT2 to excel in table-centric tasks while maintaining strong general language and coding abilities. One of TableGPT2's key innovations is its novel table encoder, specifically designed to capture schema-level and cell-level information. This encoder strengthens the model's ability to handle ambiguous queries, missing column names, and irregular tables commonly encountered in real-world applications. Similar to visual language models, this pioneering approach integrates with the decoder to form a robust large multimodal model. We believe the results are compelling: over 23 benchmarking metrics, TableGPT2 achieves an average performance improvement of 35.20% in the 7B model and 49.32% in the 72B model over prior benchmark-neutral LLMs, with robust general-purpose capabilities intact.
Jailbreaking Prompt Attack: A Controllable Adversarial Attack against Diffusion Models
Apr 02, 2024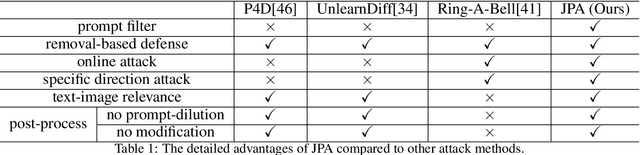



The fast advance of the image generation community has attracted attention worldwide. The safety issue needs to be further scrutinized and studied. There have been a few works around this area mostly achieving a post-processing design, model-specific, or yielding suboptimal image quality generation. Despite that, in this article, we discover a black-box attack method that enjoys three merits. It enables (i)-attacks both directed and semantic-driven that theoretically and practically pose a hazard to this vast user community, (ii)-surprisingly surpasses the white-box attack in a black-box manner and (iii)-without requiring any post-processing effort. Core to our approach is inspired by the concept guidance intriguing property of Classifier-Free guidance (CFG) in T2I models, and we discover that conducting frustratingly simple guidance in the CLIP embedding space, coupled with the semantic loss and an additionally sensitive word list works very well. Moreover, our results expose and highlight the vulnerabilities in existing defense mechanisms.
TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT
Aug 07, 2023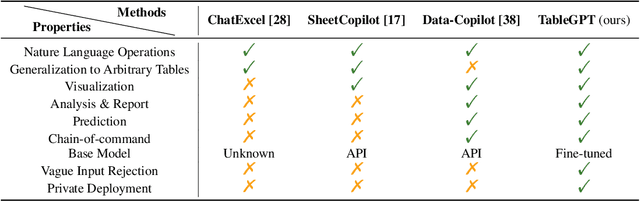



Tables are prevalent in real-world databases, requiring significant time and effort for humans to analyze and manipulate. The advancements in large language models (LLMs) have made it possible to interact with tables using natural language input, bringing this capability closer to reality. In this paper, we present TableGPT, a unified fine-tuned framework that enables LLMs to understand and operate on tables using external functional commands. It introduces the capability to seamlessly interact with tables, enabling a wide range of functionalities such as question answering, data manipulation (e.g., insert, delete, query, and modify operations), data visualization, analysis report generation, and automated prediction. TableGPT aims to provide convenience and accessibility to users by empowering them to effortlessly leverage tabular data. At the core of TableGPT lies the novel concept of global tabular representations, which empowers LLMs to gain a comprehensive understanding of the entire table beyond meta-information. By jointly training LLMs on both table and text modalities, TableGPT achieves a deep understanding of tabular data and the ability to perform complex operations on tables through chain-of-command instructions. Importantly, TableGPT offers the advantage of being a self-contained system rather than relying on external API interfaces. Moreover, it supports efficient data process flow, query rejection (when appropriate) and private deployment, enabling faster domain data fine-tuning and ensuring data privacy, which enhances the framework's adaptability to specific use cases.
CT-BERT: Learning Better Tabular Representations Through Cross-Table Pre-training
Jul 10, 2023

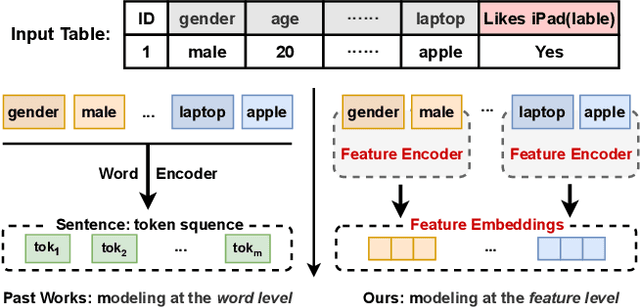
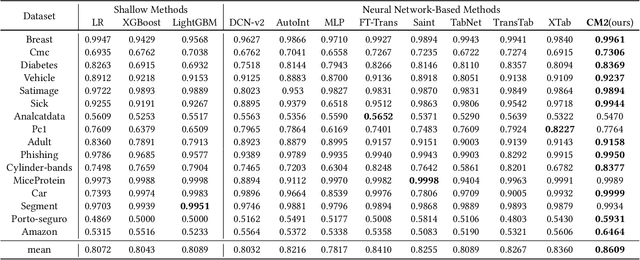
Tabular data -- also known as structured data -- is one of the most common data forms in existence, thanks to the stable development and scaled deployment of database systems in the last few decades. At present however, despite the blast brought by large pre-trained models in other domains such as ChatGPT or SAM, how can we extract common knowledge across tables at a scale that may eventually lead to generalizable representation for tabular data remains a full blank. Indeed, there have been a few works around this topic. Most (if not all) of them are limited in the scope of a single table or fixed form of a schema. In this work, we first identify the crucial research challenges behind tabular data pre-training, particularly towards the cross-table scenario. We position the contribution of this work in two folds: (i)-we collect and curate nearly 2k high-quality tabular datasets, each of which is guaranteed to possess clear semantics, clean labels, and other necessary meta information. (ii)-we propose a novel framework that allows cross-table pre-training dubbed as CT-BERT. Noticeably, in light of pioneering the scaled cross-table training, CT-BERT is fully compatible with both supervised and self-supervised schemes, where the specific instantiation of CT-BERT is very much dependent on the downstream tasks. We further propose and implement a contrastive-learning-based and masked table modeling (MTM) objective into CT-BERT, that is inspired from computer vision and natural language processing communities but sophistically tailored to tables. The extensive empirical results on 15 datasets demonstrate CT-BERT's state-of-the-art performance, where both its supervised and self-supervised setups significantly outperform the prior approaches.